はじめに
今、「RAG(検索拡張生成)」というAI技術が大きな注目を集めています。最近では主要なクラウドサービスが RAG 構築機能の提供し始めたことで、実装のハードルが下がり、身近な技術になりつつあります。本記事では、その 1 つであるGoogle Cloudの「 Vertex AI RAG Engine 」を使い、専門知識がなくてもノーコードで QA ボットを構築する手順を解説します。
今回使用するデータは弊社Webクローリングツールである ShtockData のマニュアルです。Notion で書かれたものをマークダウンファイルとしてエクスポートしました。本プロダクトの使い方などを回答する QA ボットとして回答できることを目指して構築していきます。
Vertex AI RAG Engine とは
RAG Engine は、Google Cloud上で RAG 環境をフルマネージドで構築でき、さらに細かいチューニングも可能なサービスです。比較的新しいサービスで、2024 年 12 月に GA となりました(https://cloud.google.com/vertex-ai/docs/release-notes#December_20_2024)。
このサービスでは、ドキュメントの集合体である「コーパス」を作成することで、LLM が必要なデータを参照できるようになります。
類似のサービスに Vertex AI Search がありますが、こちらは検索機能に焦点を当てているのに対し、RAG Engine は RAG 構築の全工程を幅広くサポートしているという違いがあります。
RAG を使用せずに生成 AI へ質問したところ…
まず、RAG を使用せずに Gemini へ ShtockData の使い方に関する質問をしてみました。
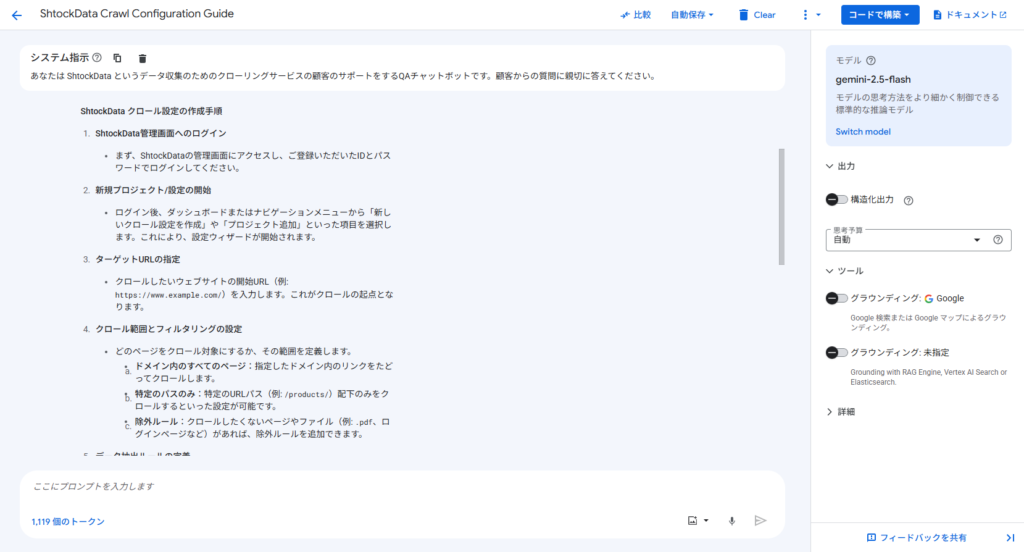
RAG を使用しない場合、Gemini は参照する情報がないため想像でアプリケーションの説明を始めてしまい、ハルシネーション(事実に基づかない情報の生成)が起こってしまいました。
例えば、下の画像における「プロジェクト追加」や「クロール範囲とフィルタリングの設定」は ShtockData にない機能にも関わらず、こういった機能について言及してハルシネーションを起こしていることが分かります。
今回は、RAG を構築することによって、このようなハルシネーションのリスクを低減しようと考えています。
RAG 構築
それでは、さっそく RAG を構築していきましょう。
まず、 Google Cloud のコンソールで Vertex AI のページを開き、サイドバーから「Agent Builder > RAG Engine」を選択します。
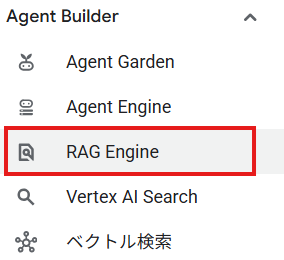
RAG Engine のページを開くとコーパスの一覧画面が表示されます。「コーパスを作成」から作成を開始します。 (注:リージョンは選択できますが、2025年6月現在は米国か欧州のみのようです)
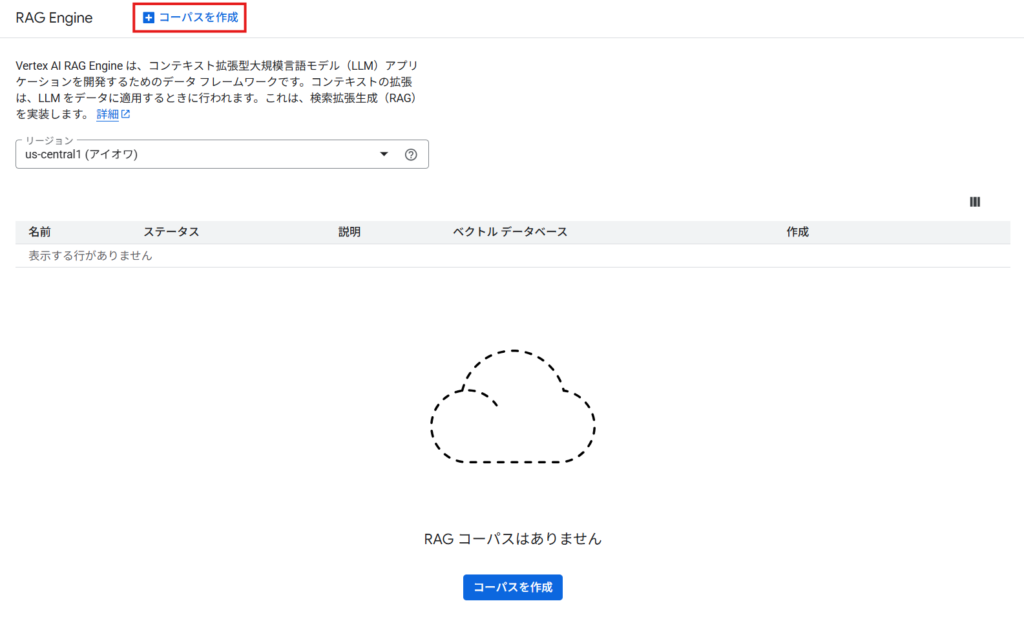
1. アップロード元の指定
次に、参照させたいデータを選択します。データのアップロード元として、以下の5つのサービスが利用可能です。
- Google Cloud Storage (GCS)
- Google ドライブ
- Slack
- Jira
- SharePoint
特に指定がない場合は、 GCS のバケットにデータを格納してアップロードするのがスムーズです。
今回は、GCSに ShtockData のマニュアルのマークダウンファイルを格納しました。
2. レイアウトパーサーの選択
詳細オプションを開くと、レイアウトパーサーを選択する設定があります。
レイアウトパーサーとは、ドキュメントから情報を抽出するための解析機能です。以下の3種類から選択できます。
- デフォルトの解析ライブラリ
- ドキュメントからテキストを抽出する基本的なパーサーです。
- LLM パーサー
- Gemini モデルを使用し、ドキュメント内のテキストや図から複雑なコンテキストを抽出できます。
- 参考:https://cloud.google.com/vertex-ai/generative-ai/docs/rag-engine/llm-parser?hl=ja
- Document AI レイアウト パーサー
- Document AI を使用し、ドキュメントから表やリストの内容を高い精度で抽出できます。
- 参考:https://cloud.google.com/vertex-ai/generative-ai/docs/rag-engine/layout-parser-integration?hl=ja
今回は対象がテキストのみのマークダウンファイルのため、「デフォルトの解析ライブラリ」を選択します。

設定が完了したら、「続行」をクリックして次の画面に進みます。
3. エンベディングモデルとベクトルデータベースの選択
次に、エンベディングモデルとベクトルデータベースを選択します。エンベディングモデルは、ドキュメントの情報を機械が理解しやすいベクトル形式に変換するモデルです。ベクトルデータベースは、そのベクトル化された情報を格納・検索するためのデータベースです。
エンベディングモデル 現在、RAG Engine では以下の3種類のモデルが提供されています。
- text-embedding-005
- text-embedding-004
- text-multilingual-embedding-002
このうち、日本語のテキストを扱う場合は「text-multilingual-embedding-002」を選択する必要があります。「text-embedding-005」と「text-embedding-004」は英語に特化しています。
今回は日本語のマニュアルなので「text-multilingual-embedding-002」を使用します。
ベクトルデータベース Google Cloudのサービス3種類と、サードパーティ製サービス2種類から選択できます。
- Google Cloud
- RagManaged ベクトルストア
- フルマネージドで複雑な設定なしに利用できるベクトルデータベース。小規模なRAGの構築や検証に適しています。
- Vertex AI Feature Store
- BigQuery基盤のベクトルデータベース。費用対効果が高く、大規模なRAG構築に向いています。
- Vertex AI Vector Search
- Google Research開発の技術をベースにしたベクトルデータベース。大規模環境での利用に適しており、現在Google Cloudのサービスで唯一GAされています。
- RagManaged ベクトルストア
- サードパーティ
- Pinecone
- Weaviate
既にPineconeやWeaviateを利用している場合はそちらを選択し、そうでない場合は目的に合わせてGoogle Cloudのサービスを選びましょう。
今回は最も手軽な「RagManaged ベクトルストア」を使用します。
最後に「コーパスを作成」を押せば、作業は完了です。

4. 動作確認
コーパスが完成したら、「Vertex AI Studio でテストする」から、作成したコーパスを使ってGeminiと対話することができます。

画面右側で「グラウンディング:RAG Engine」がONになっていれば、Geminiが先ほどのコーパスを参照する準備ができています。この状態でプロンプトを入力して質問してみます。
以下の画像のように、ShtockDataの使い方について質問したところ、マニュアルに基づいて正確な情報を返してくれました。どのドキュメントを参考にしているかも明示してくれます。
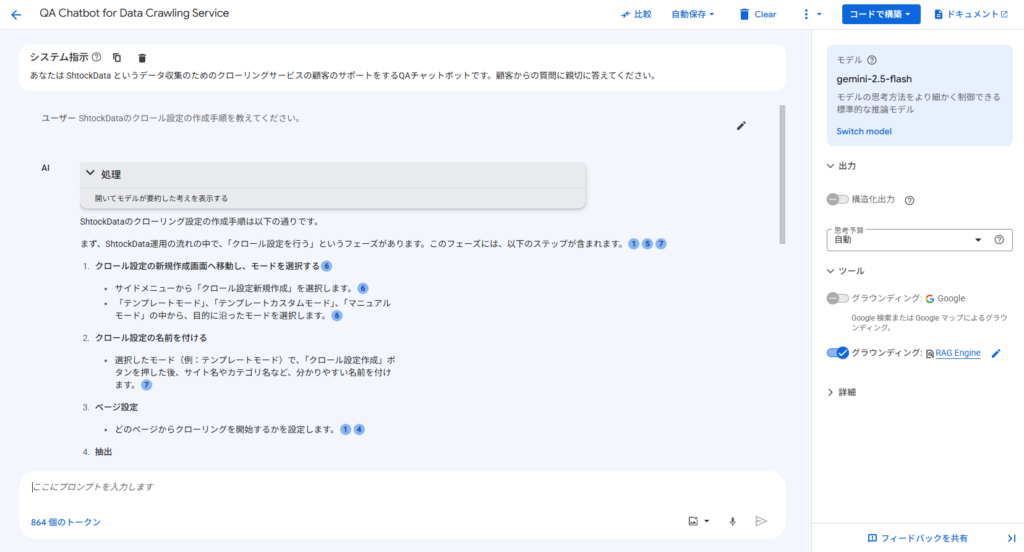
RAG を使用しないパターンと比較するとハルシネーションがなくなり、正確な情報を返してくれるようになりました。
まとめ
本記事では Google Cloud の Vertex AI RAG Engine を用いて、ノーコードでRAG を構築する手順を解説しました。LLMの課題であるハルシネーションを抑制し、根拠のある回答を生成する仕組みを、インフラの専門知識なしに構築できる点は、開発者にとって大きな魅力です。
また Vertex AI RAG Engine には今回紹介した手軽さに加え、詳細なチューニングオプションも備えています。この柔軟性により、小規模な検証から大規模なサービス開発まで多様な要件に対応可能です。
今後は、実際の業務データを使った応用や、RAGのチューニングによる回答精度の向上など、より実践的な活用方法にも挑戦していく予定です。
本記事が、皆様のLLM活用推進の一助となれば幸いです。
キーウォーカーの生成AI実装支援
本記事で紹介した内容をはじめとする生成AIの実装支援を行っています。
PoC(概念実証)から導入企画、独自モデルの開発、データ基盤の整備まで、AI活用における幅広いニーズに対応可能です。事業課題に応じたご相談も承っておりますので、ぜひお気軽にお問い合わせください。
