この記事では、n8nのワークフローでWebサイトから情報を取得するための様々な方法を紹介します。目的は、特定の方法を詳細に解説することではなく、どのようなアプローチがあるのかを幅広く理解していただくことです。
そのため、各ノードの細かい設定方法には深く立ち入らず、デモを通じてそれぞれの方法の基本的な考え方を説明します。この記事が、あなたのプロジェクトに最適な方法を見つける手助けとなれば幸いです。
Webからの情報取得は、大きく分けて以下の2つのステップで考えることができます。
- Webページの生データ(HTMLなど)を取得する
- 取得したデータから目的の情報を抽出する
それでは、具体的な方法を見ていきましょう。
基本編:HTTPリクエストと情報抽出
これは最も基本的で直接的なアプローチであり、多くの静的なWebサイト(ページを開いたときに表示される内容が固定されているサイト)に対して非常に有効です。ページのソースコードに含まれている情報であれば、この方法で取得できます。
例として、Keywalkerの会社情報ページから情報を取得してみましょう。
今回の情報取得の対象となる弊社ウェブサイトの会社概要ページ
ステップ1:WebページのHTMLを取得する
まず、n8nの HTTP Request ノードを使って、ターゲットとなるWebページのHTML情報を取得します。
GET メソッドでURLを指定するだけで、ページのHTMLソースコードが丸ごと手に入ります。
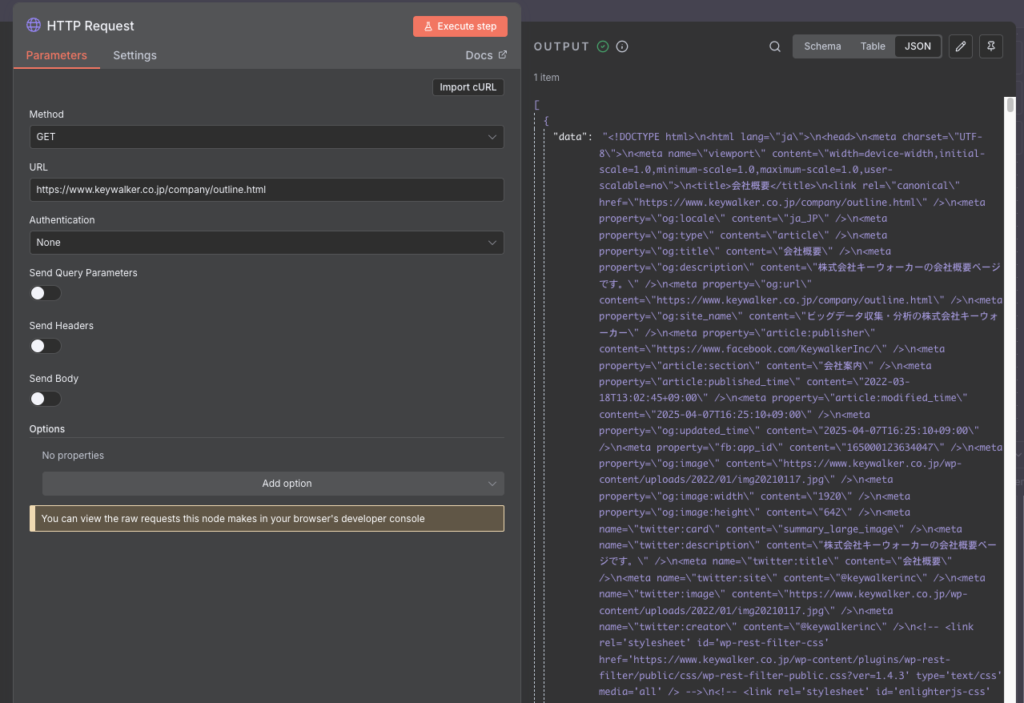
HTTP Requestノードの実行結果。WebページのHTMLがdataプロパティに格納される
しかし、このままではただの長い文字列であり、活用は困難です。そこで、次のステップで必要な情報だけを抜き出します。
ステップ2:HTMLから情報を抽出する
HTMLから目的の情報を抜き出すには、いくつかの方法があります。それぞれに特徴があるため、目的に応じて使い分けましょう。
1. LLMを利用する(柔軟性重視)
ChatGPTやGeminiのようなLLMは、構造化されていないテキストから情報を抽出するのが得意です。
HTTP Request ノードで取得したHTMLを、そのままLLMのノード(例:Geminiノード)に入力し、「このHTMLから会社概要をJSON形式で抽出して」のように自然言語で指示するだけで、目的のデータを整形してくれます。
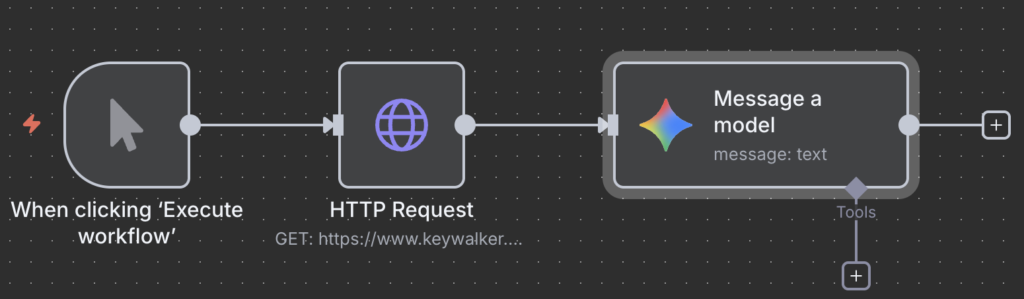
取得したHTMLをGeminiノードに入力し、会社概要を抽出するワークフローと設定例
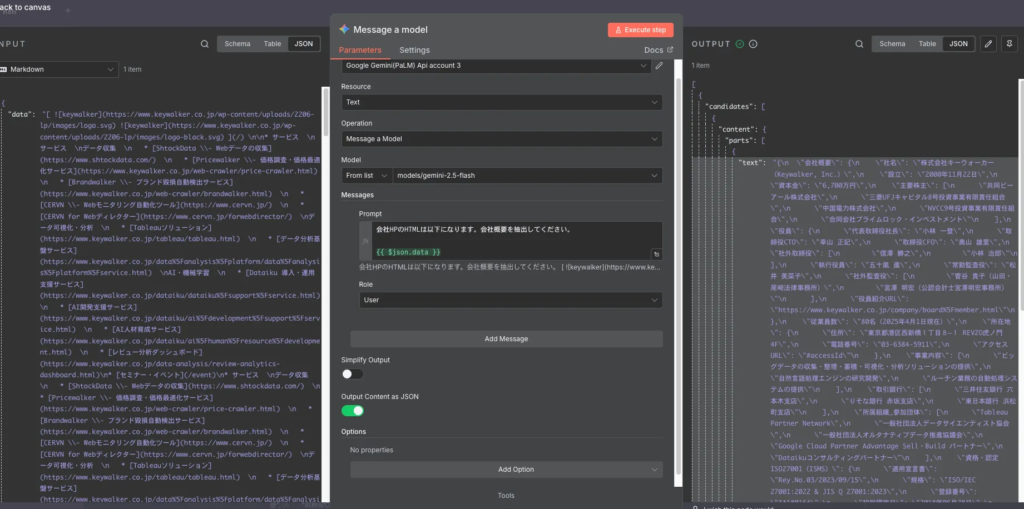
Geminiノードの入力と出力例
LLMで抽出したJSON(一部抜粋):
{
"会社概要": {
"社名": "株式会社キーウォーカー(Keywalker, Inc.)",
"設立": "2000年11月22日",
"資本金": "6,700万円",
"主要株主":[
// ...
],
"従業員数": "80名(2025年4月1日現在)",
"所在地": {
"住所": "東京都港区西新橋1丁目8−1 REVZO虎ノ門4F",
"電話番号": "03-6384-5911",
"アクセスURL": "#accessId"
},
"役員": {
// ...
}
【ポイント】 LLMにHTMLをそのまま渡すと、大量のトークン(処理単位)を消費してしまいます。事前にHTMLをMarkdown形式に変換してから渡すことで、トークン数を大幅に削減でき、コスト削減と処理速度の向上が期待できます。
HTMLをMarkdownに変換してからLLMに渡すことで、処理するトークン数を大幅に削減できる
この例では、トークン数を約1/5まで節約できました。
- HTMLそのまま:36,829
- HTMLをMarkdown形式に変換:6,859
ただし、変換によって一部の情報が失われる可能性もあるため、注意が必要です。
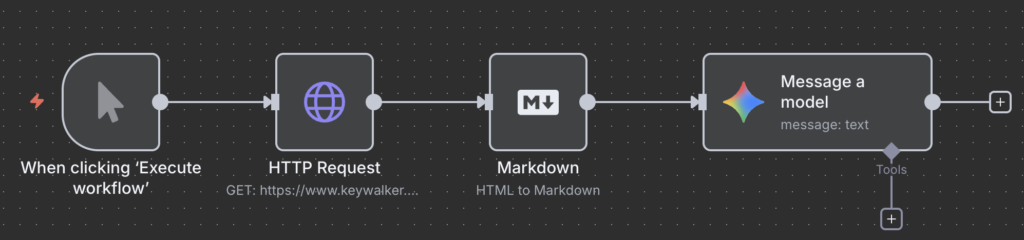
2 .n8nの Extract HTML Content ノードを利用する(速度・正確性重視)
n8nには、HTMLからの情報抽出に特化した Extract HTML Content という専用ノードがあります。このノードでは、CSSセレクタを使って抽出したいHTML要素をピンポイントで指定します。
CSSセレクタは、ブラウザのデベロッパーツール(ページ上の要素を右クリックして「検証」)で簡単に確認・取得できます。この方法は、LLMのように毎回APIコストがかからず、非常に高速かつ正確に構造化されたデータを抽出できるため、定期的に同じサイトから同じ情報を取得する場合に最適です。
n8nのExtract HTML Contentノード
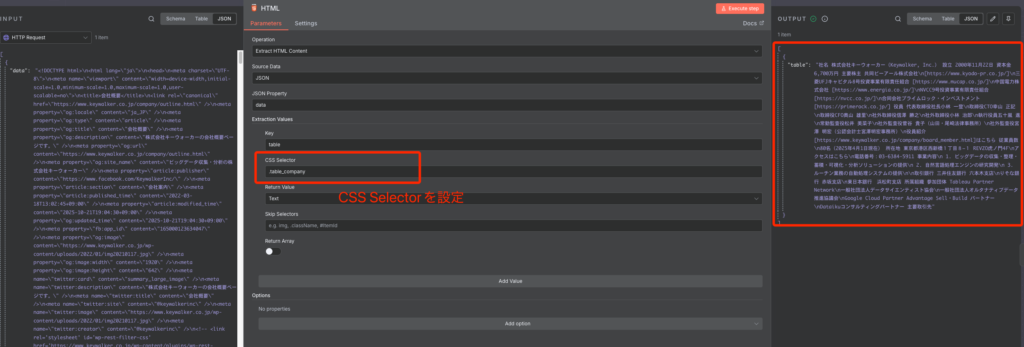
CSSセレクタを指定して特定の情報をピンポイントで抽出できる
応用編:ブラウザ自動化による動的サイトへの対応
HTTP Request ノードでは、JavaScriptによって動的にコンテンツが生成されるWebサイトの情報を完全には取得できません。例えば
- ページを開いた後に読み込まれる情報が多いサイト
- ログインしないと見れない会員専用ページ
- ボタンをクリックしたり、検索窓に入力したりしないと表示されない情報
- 無限スクロールで次々に読み込まれるコンテンツ
このようなケースでは、単にページを取得するだけでなく、一連の「操作」が必要です。ここで有効になるのが、RPA(Robotic Process Automation)の発想、つまり人間のブラウザ操作そのものをプログラムで再現する「ブラウザ自動化」というアプローチです。
この方法では、ボタンのクリック、フォームへの入力、ページのスクロールといった人間と同じ操作を自動化し、画面に表示された通りの情報を取得できます。
【自作環境の主な利点】
- Web上の定型業務を完全自動化: ログイン、レポートのダウンロード、複数ページにわたる情報収集など、一連のWeb-RPA処理を構築できます。
- 動的コンテンツへの完全対応: 人間がブラウザで見るのと同じ画面を操作するため、JavaScriptで複雑に制御されるWebアプリケーションにも対応できます。
- データの機密性: 外部APIにデータを送信する必要がなく、機密情報も安全に扱えます。
- コストの予測可能性: 従量課金ではなく、自前のサーバーコストのみで運用できます。
ただし、この方法は技術的難易度が高く、環境の構築・維持にコストと手間がかかる点がデメリットです。
n8nでの実装方法
n8nでブラウザ自動化を実現するには、主にPlaywrightやPuppeteerといったライブラリを使います。
1. コミュニティノードの利用
n8nには、コミュニティが開発したPlaywright用のノード (n8n-nodes-playwright) があります。これをn8nにインストールすれば、ワークフロー内でページを開く、スクリーンショットを撮るなどの基本的なブラウザ操作が可能になります。簡単なWeb-RPAであれば、ここから始めるのが手軽です。
Playwrightのコミュニティノード。基本的なブラウザ操作をn8n内で直接実行できる
2. 外部サーバーとして構築する
より柔軟で安定した運用を目指すなら、Playwrightを実行する環境をn8nとは別のサーバーに構築し、APIとして呼び出す方法が推奨されます。n8nは HTTP Request ノードでこのAPIに指示を送り、ブラウザ操作の結果を受け取ります。
このアーキテクチャは、n8nの「ワークフロー管理能力」とPlaywrightの「強力なブラウザ操作能力」を分離でき、スケーラビリティやメンテナンス性の面で優れています。
外部APIサービスとの比較:
- 有料APIサービス: セットアップが簡単で、すぐに使える。ただし、データを外部に送信する必要がある。
- 自作環境: 初期構築に手間がかかるが、機密データを外部に送らず処理できる。カスタマイズも自由自在。
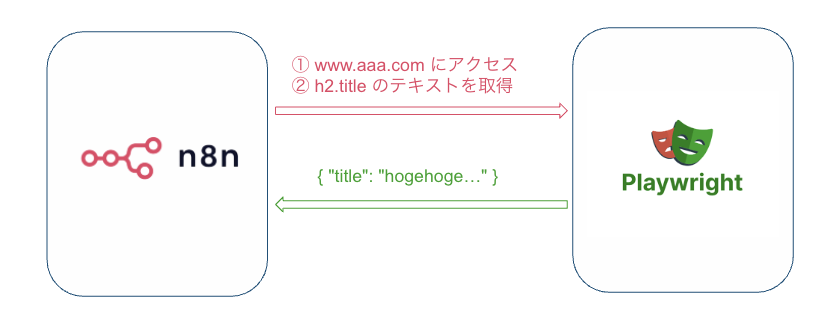
Playwrightサーバーを外部に構築するアーキテクチャ例。n8nはAPI経由でブラウザ操作を指示する
まとめと選択ガイド
ここまで紹介した2つの方法をまとめます。
| 方法 | 適用シーン | メリット | デメリット | n8nでの実装方法 |
|---|---|---|---|---|
| HTTPリクエスト + 抽出 | 静的サイト、APIからの情報取得 | シンプル、高速、低コスト | JSで動的に表示される内容には非対応 | HTTP Request, HTML Extract, LLMノード |
| 自作のブラウザ自動化 | 動的サイト、ログイン等の操作が必要なサイト、データの機密性が重要な場合 | 完全な制御権、高い柔軟性、動的コンテンツに対応可能 | 開発・維持コストが高い、技術的難易度も高い | コミュニティノードまたは HTTP Request (自作API) |
どの方法を選ぶか?
- まず HTTP Request ノードで試します。 ターゲットのURLから取得したHTMLに必要な情報がすべて含まれていますか?
- はい → この方法が最適です。Extract HTML Content やLLMで情報を抽出すれば、最も効率的です。
- いいえ → ステップ2へ。
- ブラウザ自動化を検討します。JavaScriptによるコンテンツ読み込みや、ログイン・クリックなどの操作が必要な場合は、この方法が必要です。小規模なテストならコミュニティノードから始め、本格的な運用や複雑な処理が必要なら、外部サーバーの構築を検討しましょう。
どちらを選ぶかは、プロジェクトの要件、技術リソース、セキュリティ要件などを総合的に判断して決めることが重要です。
おわりに
n8nでWeb情報を取得する方法は一つではありません。まずは最もシンプルな方法から試し、要件に応じてより高度な方法を検討していくのが良いでしょう。
もし、この記事で紹介した方法でも対応が難しい場合や、ブラウザ自動化環境の構築に困難を感じる場合は、専門のWebスクレイピングAPIサービスを利用する選択肢もあります。これらのサービスは、面倒なプロキシ管理やJavaScriptのレンダリングなどを代行してくれるため、より手軽にデータを取得できる場合があります。
さらに、大規模なデータ取得、CAPTCHA認証の突破など、特に難易度の高いWebスクレイピングが必要な場合は、専門家にご相談いただくのが確実です。
弊社キーウォーカーでは、長年の経験を活かしたWebスクレイピングの専門開発サービスを提供しております。 お客様の要件に合わせた最適な収集基盤の構築から運用までサポートいたしますので、お困りの際はお気軽にご相談ください。
この記事が、あなたの目的に合った最適な方法を見つけるための地図となることを願っています。
最後に
私たちキーウォーカーは 「まずは試す」「成功も失敗もオープンに共有する」ことを大切にしています。
新しい技術やツールを積極的に取り入れ、事業成果/顧客価値に結びつける取り組みを続けています。
- 新しいことに主体的に取り組みたい
- 最新技術(生成AIやLLMなど)を活用した価値創出へチャレンジしたい
- BizとDevの垣根を越えて挑戦してみたい
新卒・中途問わず、そんな意欲ある仲間を歓迎しています。 少しでも興味を持っていただいた方は、ご応募・お問い合わせください。
詳しくは 新卒採用ページ 、中途採用ページ をご覧ください。
