1 はじめに
Dataikuのバージョン12.6.2から、Snowflake CortexのモデルをDataikuのLLMレシピで使用することができるようになりました。これにより安全に、データを移動することなくAIをノーコードで使用できるようになり、大変便利になりました。
しかし、Snowflake Cortexで利用できるLLMには多くの種類があり、性能も様々です。加えて、Dataiku Cloudのリージョンによって利用できるLLMが異なります。このような状況において、使用できるLLMやモデルの性能について日本語でまとめられている情報が存在しません。
そのため、今回は日本のDataiku Cloudユーザーに向けて、東京リージョンで稼働しているDataikuを通じて使用できるSnowflake CortexのLLM性能について比較してまとめました。
(2025年7月時点の情報です。今後、利用できるLLMは拡張されていくと思います。)
また、次回のブログでは、DataikuとSnowflake Cortexを接続して使用する手順を解説していますので、気になった方はぜひご覧ください。
2 東京リージョンで稼働しているDataiku経由で利用可能なSnowflake Cortex LLM
東京リージョンで稼働しているDataikuを通じて使用できるSnowflake CortexのLLMは以下の通りです:
テキスト生成モデル:
- Llama 3.1 70B
- Mistral Large 2
- Mixtral-8x7B
- Mistral 7B
- Mistral Large
埋め込みモデル:
- E5-base-v2
- Snowflake Arctic Embed M
結論として、日本語のデータを扱う場合、テキスト生成には Mistral Large 2、埋め込みにはSnowflake Arctic Embed Mが最も高い性能を示しています。
3 各モデルの概要と特徴
本ブログでは、各モデルの概要や特徴をわかりやすく解説し、それぞれのメリットとデメリットについても整理してご紹介します。
3.1 テキスト生成モデル
Llama 3.1 70B
Llama 3.1 70BはMeta社が提供するオープンソースLLMで、Llama 3.1 70Bの「3.1」はLLMのバージョン番号、「70B」はパラメータ数(700億)を表しています。
多くのベンチマークスコアにおいて、Mixtral-8x7BやGPT-3.5 Turboを上回る性能を示しています。
しかし、サポートする8言語に日本語が含まれていません。
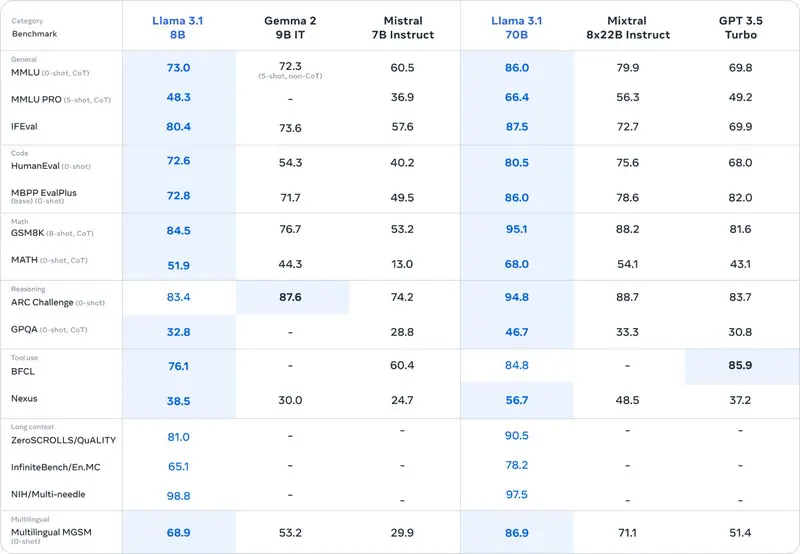
Llama 3.1 70Bのベンチマーク表の画像
出展: Introducing Llama 3.1: Our most capable models to date(https://ai.meta.com/blog/meta-llama-3-1/)
Llama 3.1 70Bのメリット
- 高いパフォーマンスを発揮する
Llama 3.1 70Bのデメリット
- 対応する8言語に日本語が含まれていない
Mistral Large 2
Mistral Large 2は、Mistral AIによって開発された、パラメータ数123Bの大規模言語モデル(LLM)です。
非常に広い128kトークンのコンテキストウィンドウを備え、長文処理に優れた性能を発揮します。
対応言語も豊富で、日本語をはじめ、英語、フランス語、ドイツ語、スペイン語、イタリア語、ポルトガル語、アラビア語、ヒンディー語、ロシア語、中国語、韓国語など、多言語対応に優れています。
さらに、Python、Java、C、C++、JavaScript、Bashを含む80種類以上のプログラミング言語もサポートしており、コード生成や補完などのタスクにも強みを持ちます。
トレーニング段階では、ハルシネーション(事実に基づかない出力)を最小限に抑える工夫が施されており、高い信頼性を実現しています。
また、Llama 3.1 (405B)と比較すると、パラメータ数は約1/4であるにもかかわらず、同等レベルの性能を発揮すると評価されています。
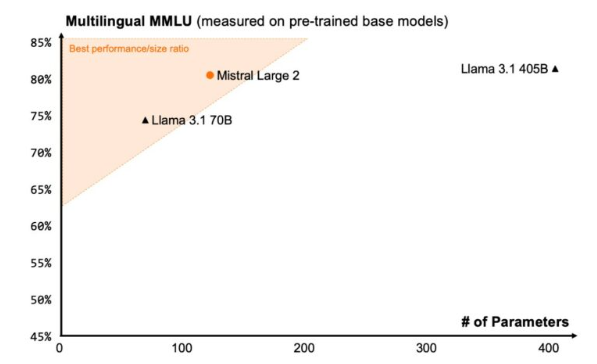
Mistral Large 2のベンチマークの画像
出展:Large Enough(https://mistral.ai/news/mistral-large-2407)
Mistral Large 2のメリット
- 前述のLlama3.1 70Bを超える非常に高い性能を誇る
- 日本語を含む多言語に対応している
Mistral Large 2のデメリット
- モデルサイズが大きい
- 運用コストが高い
Mistral-8x7B
Mixtral(Mistral-8x7B)は、高品質なオープンウェイトのSparse Mixture of Experts(SMoE)モデルです。
本モデルは、ほとんどのベンチマークにおいてLLaMA 2 70Bと比較して約6倍の推論速度を実現しつつ、それを上回る性能を発揮します。さらに、多くの評価指標においてGPT-3.5と同等以上の精度を示しています。
対応言語は、英語、フランス語、イタリア語、ドイツ語、スペイン語に及び、実用性の高い多言語対応を特徴としています。しかし、日本語は対応言語に含まれていません。
また、Mistral Large 2と同様に、ハルシネーション(事実に基づかない出力)が抑制されており、信頼性の高い応答が期待できます。
Mistral-8x7Bのメリット
- 推論速度が高速
- ハルシネーションが抑制されている
Mistral-8x7Bのデメリット
- 日本語に対応していない
Mistral 7B
Mistral 7Bは、オープンソースとして公開されている高性能な大規模言語モデル(LLM)です。
あらゆる主要なベンチマークにおいて、Llama 2 13Bを上回る性能を示しています。
また、Grouped-Query Attention(GQA)を採用することで、推論の高速化を実現しています。
さらに、Sliding Window Attention(SWA)を用いることで、長文の処理においても低コストかつ効率的な推論が可能です。
Mistral 7Bのメリット
- 小型ながら高い性能を発揮する
- 日本語に対して中程度の対応力がある
Mistral 7Bのデメリット
- LLaMA 3.1 70Bなど大規模モデルと比べると性能は劣る
Mistral Large
Mistral Largeは、LLaMA 3.1(70B)やClaude 2を上回る性能を持つ大規模言語モデルです。
ただし、LlaMA 3.1(405B)やMistral Large 2など、より高性能なモデルには及びません。
多言語対応にも優れており、英語、フランス語、スペイン語、ドイツ語、イタリア語をネイティブレベルで処理可能です。
また、日本語にも対応しており、一定の精度で理解・出力が可能です。
さらに、32Kトークンのコンテキストウィンドウを備えており、長大な文書やコードの処理にも適しています。
Mistral Largeのメリット
- LLaMA 3.1 70Bには及ばないものの、高い性能を持つ
- 多言語に対応している
Mistral Largeのデメリット
- 日本語対応はあるものの、自然さや正確性でGPT-4などに劣る
3.2 埋め込みモデル
E5 Base v2
E5 Base v2は、埋め込み表現の生成に特化したモデルであり、RAG(Retrieval-Augmented Generation)、クラスタリング、各種NLPタスクにおける特徴量抽出などに活用されます。
本モデルは、MS MARCOおよびBEIRベースのコントラスト学習により訓練されており、検索精度やクラスタリング性能に優れている点が大きな特徴です。
なお、推論(質問応答)やテキスト生成タスクには対応していません。
E5 Base v2のメリット
- 埋め込みモデルとして、クラスタリングや検索に高い精度を発揮する
E5 Base v2のデメリット
- 埋め込み専用のため、推論や生成タスクには対応していない
Snowflake Arctic Embed M
Snowflake Arctic Embed Mは、モデルサイズ110Bの埋め込みモデルです。
OpenAIの埋め込みモデル(text-embedding-3-large)と比較すると、推定パラメータ数は約1/4、埋め込み次元数は約1/3でありながら、検索性能において優れた結果を示しています。
特に日本語のベンチマークにおいて高いスコアを獲得しており、日本語の検索や類似度計算に強みを持つモデルです。
Snowflake Arctic Embed Mのメリット
- 埋め込みモデルの中でも高い性能を発揮する
- 日本語において特に高い精度を誇る
Snowflake Arctic Embed Mのデメリット
- 埋め込み専用モデルのため、推論や生成タスクには対応していない
4 まとめ
東京リージョンで稼働しているDataikuを通じて利用可能なSnowflake Cortexのモデル性能をまとめました。
Dataikuを通じてSnowflakeを補完的に活用することで、組織全体がデータドリブンな意思決定基盤を構築できるようになります。
日本語のデータを用いた推論・生成タスクを行う場合は、日本語対応かつ高性能なMistral Large 2の活用を、まずは検討することをおすすめします。また、次回のブログでは、Dataiku上でSnowflake Cortexを使用する方法を解説します。
Dataiku導入を考えている方へ
KeywalkerはDataikuのパートナーとしてDataikuの導入支援を行っています。データ分析による業務改善にご興味がある方は是非、Keywalkerにご連絡ください。
Keywalker 問い合わせフォーム:https://www.keywalker.co.jp/inquiry.html
