現代の情報検索タスクにおいて、ユーザは多様なニーズと検索意図を持っています。キーワードを使ったBag of Wordsといった手法では文脈や意味合いが適切に考慮できず、セマンティック検索ではキーワードが十分に一致しない場合などに必要以上に関連度を過小評価してしまうなど、それぞれ適切な結果を得ることができない理論上の欠点があります。このような背景から、キーワード検索とセマンティック検索の利点を組み合わせたハイブリッド検索が重要なアプローチとして知られており、今日では様々な場面で利活用されています。
今回は、ベクトルデータベースであるQdrantを用いてハイブリッド検索を実装する過程を紹介します。
Qdrantとは?
Qdrantは、高性能かつ大規模スケールのベクトル類似性検索エンジンが付属したベクトルデータベースです。Qdrantは高次元ベクトルデータの効率的な保存、検索、管理のために様々なAPIを提供しており、さらにpayloadを使ったフィルタリングもサポートしています。このQdrantを応用することで、RAG、推薦システム、AIエージェント、データ分析、異常検知など様々なプロダクトに応用することができます。
LangChainのドキュメントなどによると、発音はquadrantのように読むとのことです。
Qdrantにデータを構築する
今回はdockerでQdrantを起動させます。基本的に公式ドキュメントのQuickstartの通りに進めれば、ひとまずは利用できるようになります。ここではDockerの細かい設定については言及しません。
今回は程よい大きさのデータセットabisee/cnn_dailymailを利用し、testの記事と類似するtrainの記事をハイブリッド検索するコードを実装します。trainのサイズは約29万で、CNNとDaily Mailのニュース記事から成っています。今回はとりあえずハイブリッドサーチを使うのが目標なので、短いhighlightsのテキストを利用しています。平均の長さは56トークンなので、かなり短いテキストです。
https://huggingface.co/datasets/abisee/cnn_dailymail
検索に用いるハイブリッド検索では複数のベクトルが必要になるため、今回は簡単のために密ベクトルと疎ベクトルを用意することにします。
密ベクトルを得るために、今回はsentence-transformers/all-MiniLM-L6-v2を使いました。384次元のベクトルを得ることができ、これをクラスタリングやセマンティック検索に使うことができます。パラメータ数は22.7Mなので、CPUでも十分に動かすことができます。
https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
一方で、疎ベクトルを得るために今回はBM42を使いました。このBM42は、Bag of Wordsの一つであるIDFにTransformerのAttention機構を導入したもので、BM25について各トークンの重要度を加味することができます。今回はQdrantが提供するモデルを利用することにします。
https://huggingface.co/Qdrant/all_miniLM_L6_v2_with_attentions
最終的には以下のようなPythonコードを書き、Qdrantのデータ構築を行いました。CPUを使っても1時間半程度、GPUを使うと数分で構築が完了しました。GPUは、社内で利用可能なRTX 4060を利用しました。
from datasets import load_dataset
from qdrant_client import QdrantClient, models
from tqdm.auto import tqdm
from sentence_transformers import SentenceTransformer
from fastembed import SparseTextEmbedding
import torch
import numpy as np
import uuid
import pandas as pd
def encode_highlights_dense(model, batch):
embeddings = model.encode(batch["highlights"], convert_to_tensor = True, device = device).cpu().numpy()
return embeddings.astype(np.float32)
def encode_highlights_sparse(model, batch):
embeddings = list(model.embed(batch["highlights"]))
return embeddings
def create_point(dense_vector, sparse_vector, payload):
# 適当にUUID形式のindexを作成する (整数でも良い)
id = str(uuid.uuid5(uuid.NAMESPACE_DNS, payload["id"]))
return models.PointStruct(
id = id,
vector = {
"dense_vector": dense_vector,
"sparse_vector": models.SparseVector(
indices = sparse_vector.indices,
values = sparse_vector.values,
),
},
payload = payload,
)
def main():
# huggingfaceのデータセットを読み込む
ds = load_dataset("abisee/cnn_dailymail", "3.0.0", split = "train")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_dense = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2").to(device)
model_sparse = SparseTextEmbedding(model_name="Qdrant/bm42-all-minilm-l6-v2-attentions")
batch_size = 64
batch_count = len(ds) // batch_size + 1
# Qdrant関連の初期化
collection_name = "cnn_dailymail"
client = QdrantClient(host = "localhost", port = 6333)
# コレクションの初期化
# スキーマを最初に定義するように、ここでベクトルの形式を定義する
client.create_collection(
collection_name = collection_name,
vectors_config = {
"dense_vector": models.VectorParams(
size = 384,
distance = models.Distance.COSINE, # モデルの学習時の損失関数を元に検討すると良い
),
},
sparse_vectors_config = {
"sparse_vector": models.SparseVectorParams(
modifier = models.Modifier.IDF,
),
},
)
for idx in tqdm(range(batch_count), total = batch_count):
batch = ds[idx * batch_size : (idx + 1) * batch_size]
batch_array = pd.DataFrame(batch).to_dict(orient = "records") # List[dict]に整形し直す
embeddings_dense = encode_highlights_dense(model_dense, batch)
embeddings_sparse = encode_highlights_sparse(model_sparse, batch)
points = [create_point(*args) for args in zip(embeddings_dense, embeddings_sparse, batch_array)]
# Qdrantにデータを実際に追加する
client.upsert(
collection_name = collection_name,
points = points,
)
if __name__ == "__main__":
main()
実行が完了するとcnn_dailymailというコレクションに、以下のようなベクトル情報が構築されたことを確認できます。特に難しいアルゴリズムを使う必要が無ければ、この画面から「FIND SIMILAR」や「OPEN GRAPH」を選択することで、直接類似検索を実行することもできます。
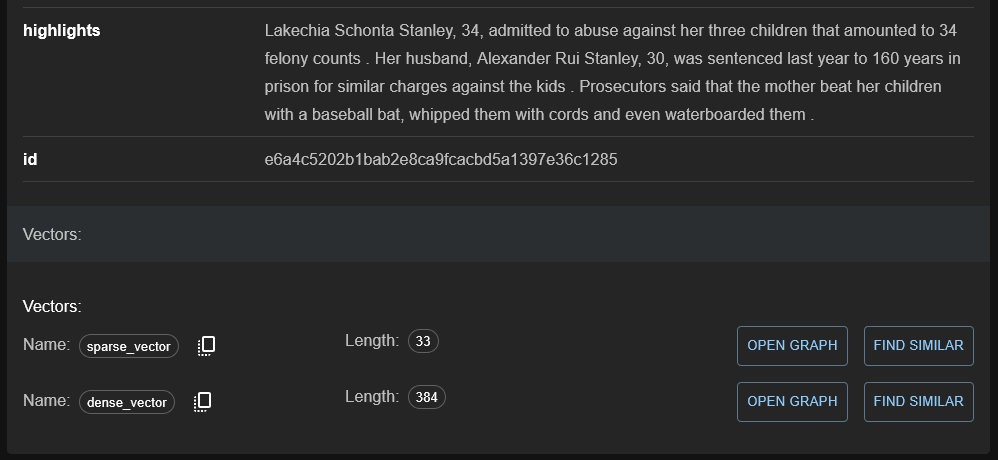
Qdrant上でデータの特徴を見る
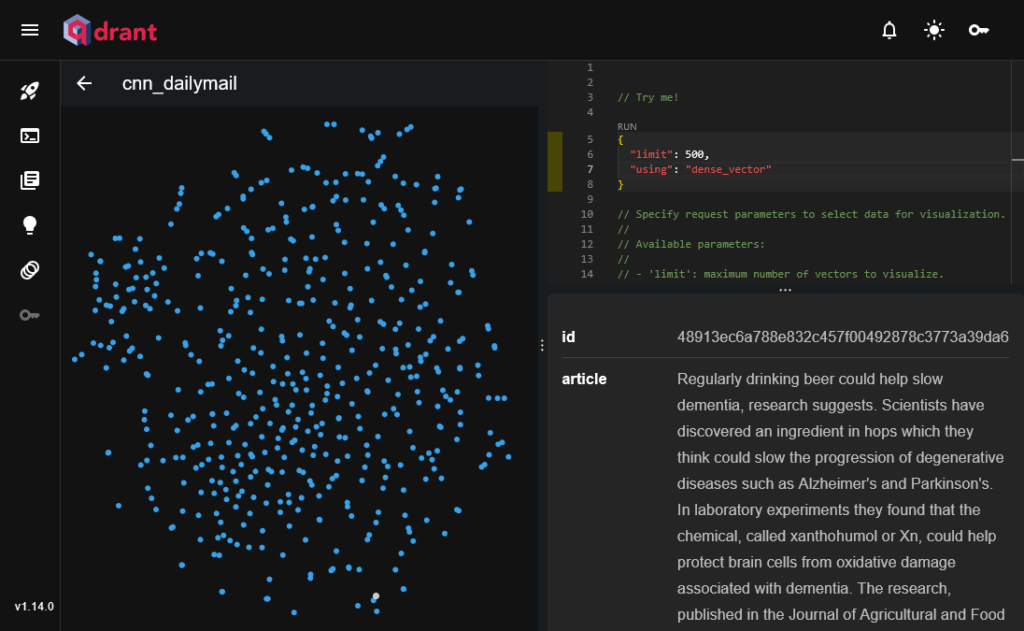
少し横道にそれますが、Qdrantでは標準でいくつかの可視化機能が提供されています。以下の例では、先ほど構築したコレクションの代表500件について2次元まで次元削減した可視化を行っています。usingパラメータを使うことで可視化に使うベクトルの種類を指定することができますが、疎ベクトルには対応していません。
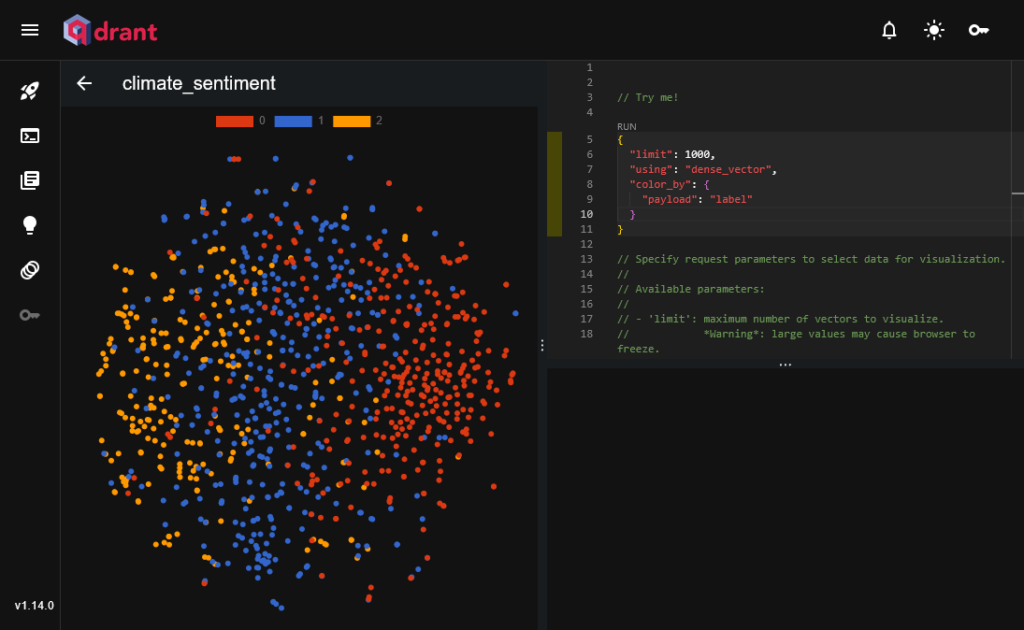
別のテキスト分類用のデータセットclimatebert/climate_sentimentを使って、ラベルをもとにカラーリングを行うと、以下のように同じラベルのテキスト同士が近い位置にプロットされていることを確認できます。このような可視化を踏まえ、ベクトルの活用方法をすぐに検討することができます。例えば、プロットの色関係なしに満遍なくプロットされてしまっている場合には、そのベクトル化手法はこの分類タスクには向いていない、と早期に判断することができます。
https://huggingface.co/datasets/climatebert/climate_sentiment
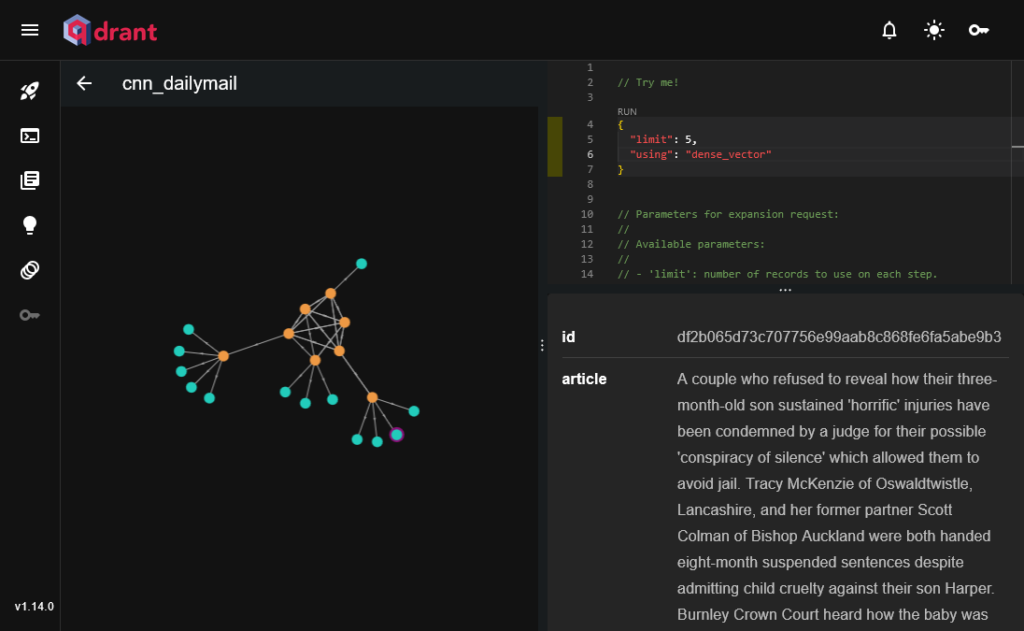
また、グラフを描画することで、似ている類似度の上位をエッジで繋ぐ可視化も可能です。以下の例では、オレンジ色のノードそれぞれについて類似する記事上位5件をエッジで結んでいます。図の中央の方にある六角形状になっているエッジの各ノードは、相互に類似した記事であることが分かります。
いずれの可視化ツールについても、各ポイントにマウスをホバーさせるとそのポイントの生データを閲覧可能です。さらに、payload中に画像URLがあると、画像をWebUI上で確認することもできます。
ハイブリッドサーチを実装する
本題に戻り、2種類のベクトルを用いて実際に文書検索を行ってみます。以下のようなコードを書いて、testデータのごく一部についてハイブリッド検索を行いました。
from datasets import load_dataset
import torch
from sentence_transformers import SentenceTransformer
from fastembed import SparseTextEmbedding
from qdrant_client import QdrantClient, models
import numpy as np
# 一部関数は使い回します
def main():
ds = load_dataset("abisee/cnn_dailymail", "3.0.0", split = "test")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_dense = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2").to(device)
model_sparse = SparseTextEmbedding(model_name="Qdrant/bm42-all-minilm-l6-v2-attentions")
collection_name = "cnn_dailymail"
client = QdrantClient(host = "localhost", port = 6333)
# とりあえずテストの10件について検索する
test_cases = ds[:10]
embeddings_dense = encode_highlights_dense(model_dense, test_cases)
embeddings_sparse = encode_highlights_sparse(model_sparse, test_cases)
search_results = []
for dense, sparse in zip(embeddings_dense, embeddings_sparse):
search_result = client.query_points(
collection_name = collection_name,
prefetch = [
models.Prefetch(
query = dense.tolist(),
using = "dense_vector",
limit = 100,
),
models.Prefetch(
query = models.SparseVector(
indices = sparse.indices.tolist(),
values = sparse.values.tolist(),
),
using = "sparse_vector",
limit = 100,
)
],
query = models.FusionQuery(fusion = models.Fusion.RRF),
with_payload = True, # 結果出力用にpayloadも含める
limit = 10,
).points
search_results.append(search_result)
return search_results
if __name__ == "__main__":
# 10件のクエリについて、それぞれ10件ずつ検索結果が返ってくる
results = main()
クエリの最初の1件について、見やすいように一部のhighlightsを出力してみました。結果に挙がってきた1~3は、いずれもsourceの文書に似たり寄ったりの文書がヒットしています。結果データに直接payloadが含まれるように設定しているため、追加でQdrantを叩く必要なしにデータを閲覧できますが、indexが明らかであればretrieveメソッドを使ってデータを取得することもできます。
source: Membership gives the ICC jurisdiction over alleged crimes committed in Palestinian territories since last June . Israel and the United States opposed the move, which could open the door to war crimes investigations against Israelis . ================================================================================ 1: ICC prosecutes individuals accused of crimes against humanity, war crimes, genocide . Set up at conference in 1998 and established in 2002 . 115 states have ratified the treaty, but not United States, Russia, China, Israel . 2: Hamas signed a document demanding that the Palestinian Authority go before the ICC . The International Criminal Court could investigate war crimes on both sides . Israel and the United States have pressured the Palestinians not to do that . Rockets continued to land in Israel . 3: Palestinians want Israel to be hauled before the International Criminal Court . They claim that the country's attack on Gaza resulted in war crimes . Netanyahu met with US lawmakers to discuss the Gaza conflict . Israeli leader hoping US can prevent his country from being investigated .
prefetchとして疎密ベクトルのそれぞれについて事前の検索を行い、それぞれの結果をRRF (Reciprocal Rank Fusion) を使って融合しています。RRFについてここでは詳述しませんが、それぞれのランキング結果について各ドキュメントに逆順位スコアを割り当てて、新たな1つのランキングを作成する仕組みを言います。 今回は2つのベクトルを使ってハイブリッド検索してみましたが、ドメインやタスクによってはさらに画像のベクトル情報を加味する、といった場面が想定できます。そういった場合にでもQdrantを使うことで容易に検索を拡張することができます。
おわりに
Qdrantを使ったベクトルのハイブリッド検索を実装してみました。ベクトルデータベースの機能を存分に活用することで、省メモリで高速に、そして簡単にベクトル検索を行うことができます。また、可視化機能を活用することで、本格的な実装の前にある程度ベクトル化手法の性能や傾向を把握することができるため、コードを実装してから残念な思いをする、というリスクも減らすことができると思います。
本記事が、これらリッチな機能を活用しながらのより効率的な開発の一助となれば幸いです。
