はじめに
- ChatGPT/GPTの画像認識機能(GPT-4V)を用いて画像からhtml要素の識別子(selector)を取得しました。
- 予めhtmlを解析して主要な要素のクラス名を表示した上でスクリーンショットを撮って、画像を作成しています。
- 最後に、識別子(selector)を用いてページより情報を取得できることを確認しました。
- 識別子(selector)を抽出することで、既存のクローラー(例:ShtockData)と組み合わせてデータ取得が行えるようになることを目指しています。

おことわり
本ブログは、情報抽出等に関心がある開発者に弊社のクローラー改善の取り組みの一部を紹介させていただいております。
改善アイデアの検証実験の報告であり、製品に組み込まれている機能ではない点をご承知おきください。
また本ブログで紹介しているプログラムは不完全な物であり、そのままでは動作しませんのでご注意ください。
目次
- 概要
- スクリーンショット取得
- selector取得
- データ取得
- まとめ
1.概要
過去にChatGPT/GPTを用いたWebスクレイピングを試してきました。
しかし過去の調査から、ChatGPT/GPTには実運用を想定した際に下記の問題点があることが分かってきました。
- 必ずしも正確な情報が取得できるわけではない
- 応答時間やコストで大規模なデータ収集には向かない
そこで、今回はChatGPT/GPTを用いて、htmlからデータ取得対象のselectorを抽出し、selectorを用いてデータ取得することで「データの正確性」を担保できないか調査してみました。
1-1.手法概要
3つのステップでデータ取得を行っております。

| Step | 名称 | 説明 |
|---|---|---|
| Step.1 | スクリーンショット取得 | htmlの解析。対象要素と思われるクラス名を表示して画像取得。 |
| Step.2 | selector取得 | GPT-4Vを用いて画像からデータ取得対象のクラス名を取得。 |
| Step.3 | データ取得 | selectorを用いてデータを取得。 |
1-2. 工夫点
今回はSet-of-Mark(※1)的な手法を試みました。
Set-of-Mark(SoM) は、画像内の注目すべき箇所を示すことで、GPT-4Vの性能を向上させる手法です。
※1: SOM プロンプトをはじめとする視覚プロンプトの利用(リンク)
具体的には、ブラウザ画面上に「要素を囲む枠」と「クラス名を表示」することで、GPT-4Vが情報を読み取りやすくする工夫を行っております。

1-3. 対象サイト
具体例として、弊社のブログ一覧ページ(リンク)から「ブログ タイトル」の一覧を取得したいと思います。
2.スクリーンショット取得
ブラウザ画面上に全てのhtml要素のクラス名を表示すると、表示数が多すぎて識別できませんでした。
そこで、「同様な要素が複数含まれているページを対象とする」という条件を付けて、予め表示するクラス名を限定することにしました。
処理の概要
- データ取得対象と思われる要素を絞り込む
- javascriptでクラス名をブラウザ画面上に追加
- スクリーンショットを撮影
また処理は Playwright(リンク) を用いて実装しています。
実装イメージ(動作しないのでご注意ください。)
import { chromium, Browser, Page } from 'playwright';
async function takeScreenshot(url: string): Promise<void> {
// 1. ブラウザの準備
const browser: Browser = await chromium.launch({ headless: true });
const page: Page = await browser.newPage();
await page.goto(url, { waitUntil: 'load' });
// 2. ページ内の全DOM要素を照会し、フィルタリングを行い、特定の要素のみのクラス名を収集する処理
const classNames = await page.evaluate(() => {
return Array.from(document.querySelectorAll('*'))
.filter('フィルター処理')
.map(el => el.className.trim());
});
// 3. ハイライト処理 & クラス名をブラウザ画面上に表示して、スクリーンショットを取得する処理
await page.evaluate((classNames: string[]) => {
classNames.forEach(className => {
const elements = document.querySelectorAll(.${className});
elements.forEach(el => {
highlight(el, className);
});
});
function highlight(element: Element, className: string) {
if (element instanceof HTMLElement) {
// 要素をハイライト
element.style.outline = '2px solid red';
// クラス名のラベルを作成して配置
const label = document.createElement('div');
label.textContent = className;
label.style.position = 'absolute';
label.style.backgroundColor = 'white';
label.style.color = 'black';
label.style.border = '1px solid black';
label.style.padding = '2px';
label.style.fontSize = '12px';
label.style.zIndex = '1000';
const rect = element.getBoundingClientRect();
label.style.top = ${rect.top + window.scrollY}px;
label.style.left = ${rect.left + window.scrollX}px;
document.body.appendChild(label);
}
}
}, Array.from(classNames));
// 4. ScreenShot撮影
await page.screenshot({ path: 'screenshot.png', fullPage: true });
// 5. 処理が完了した後にブラウザを閉じる
await browser.close();
}
// 対象URLの指定
const url = 'https://www.keywalker.co.jp/blog';
// スクリーンショットの撮影
takeScreenshot(url);
保存されたスクリーンショット(1280×1280に切り出し)
| 対象要素 | データ取得対象としての可能性が低い要素をフィルタリング |
| 赤枠 | 候補要素を赤枠でhighlight |
| クラス名 | 候補要素の左上にクラス名を表示 |
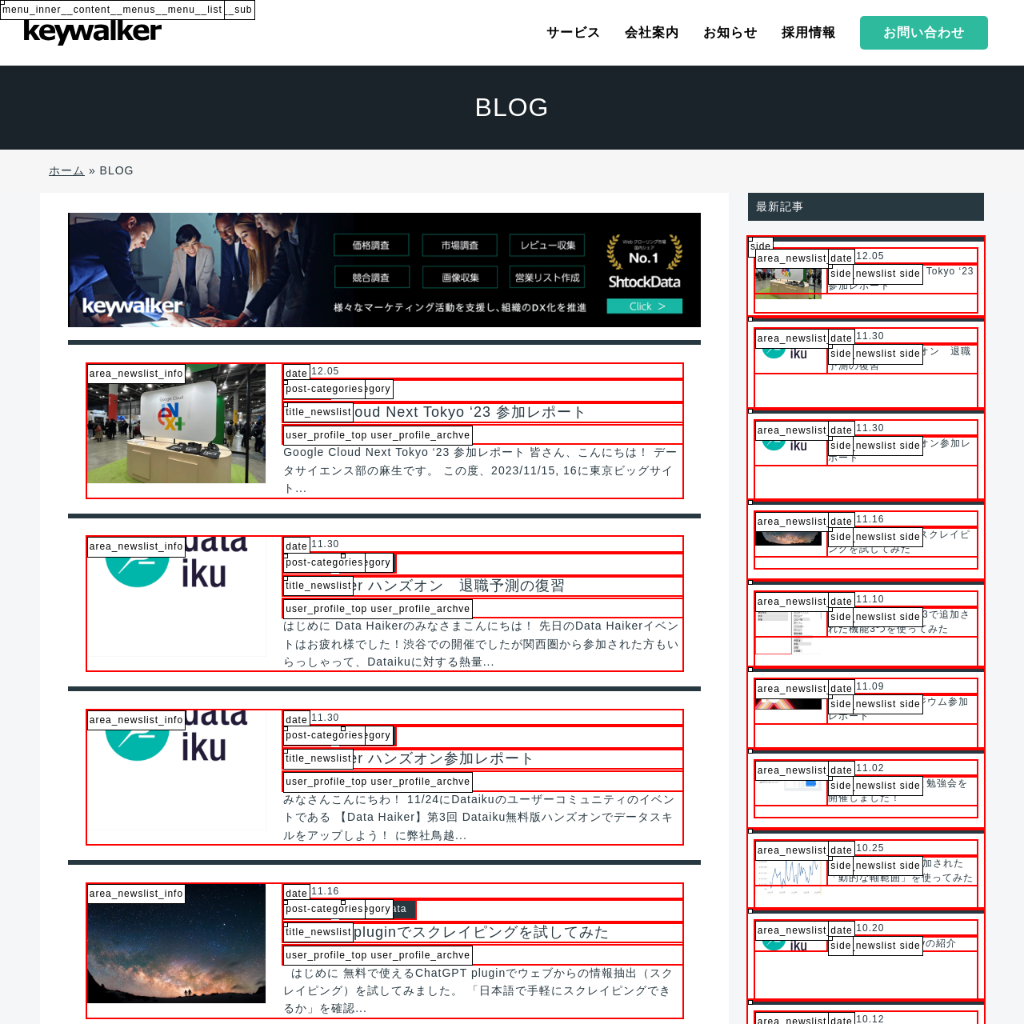
3.selector取得
「2.スクリーンショットの取得」の画像から、GPT-4Vを用いてデータ取得対象のクラス名を取得します。
画像は、OpenAI APIのドキュメント(リンク)にならって、Base64にエンコードしてアップロードしています。
その際、スクリーンショット画像のサイズが 1280 x 17413 と非常に大きかったため、1280 x 1280 のサイズに切り出し、更に 1024 x 1024 にリサイズしています。
GPT-4Vを用いた画像解析
処理概要
- 画像読み込み(サイズ:1280 x 17413)
- 画像をcrop(サイズ:1280 x 1280)
- 画像をresize(サイズ:1024 x 1024)
- 画像をBase64にエンコード
- GPT-4Vにブログタイトル部分のクラス名を問い合わせ
3-1-1. 画像の準備(処理1~4)
GPT-4Vへアップロードする準備として処理1~4までを行います。
画像の準備を行うスクリプト例
import os
import cv2
import base64
# 画像をBase64 stringに変換する関数
def cvToBase64(img):
_, encoded = cv2.imencode(".png", img)
img_str = base64.b64encode(encoded).decode("utf-8")
return img_str
# 画像をcrop&resizeして、Base64 stringに変換する関数
def getBase64String(image_path, new_length=1024):
# 画像読み込み
img_org = cv2.imread(image_path)
print(f'image size:{img_org.shape}')
# 正方形に画像をCrop
img_min_length = min(img_org.shape[0], img_org.shape[1])
cropped_img = img_org[:img_min_length, :img_min_length, :]
print(f'cropped image size:{cropped_img.shape}')
# 画像をresize
resize_img = cv2.resize(cropped_img, (new_length, new_length))
print(f'resized image size:{resize_img.shape}')
# 画像を base64 string へ変換
return cvToBase64(resize_img)
base64_image = getBase64String(image_path)
print(base64_image)
3-1-2. GPT-4Vへの問い合わせ1(処理5)
Base64でエンコードした画像をGPT-4Vにアップロードし、ブログのタイトルと思われるクラス名を問い合わせています。
GPT-4Vへの問い合わせスクリプト例
import json
from openai import OpenAI
def requestToGPT4V(base64_image, message):
client = OpenAI(api_key=api_key)
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": message},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
},
],
}
],
max_tokens=1000,
)
return response
def createMessage():
'''
この画像は、ブログ一覧のページの「html要素のクラス名」を表示した画像です。
この画像から「ブログのタイトル」と思われる「html要素のクラス名」を抽出してください。
クラス名は項目名を"class_name"としたJSON形式で回答してください。
'''
message = '''
This image displays the "html element class name" of the blog list page.
Please extract the "html element class name" that is thought to be the "blog title" from this image.
Please answer the class name in JSON format with the item name as "class_name".
'''
return message
# 要求の作成
request_message = createMessage()
# GPT-4Vへ問い合わせ
response = requestToGPT4V(base64_image, request_message)
# 応答の確認
print(response.choices[0].message.content)
応答の内容
json { "class_name": "title_newslist" }残念ながら意図するJSON形式での応答ではありませんでした。
GPT-4Vでは、response_format を指定することができないため、JSON形式で回答させるには工夫がいるようです。
本検証は初期段階の実験のため、この箇所に拘ることは一旦止めて、応答から手動で「title_newslist」を抜き出すことにしました。
3-1-3. TypeScriptからの呼び出し
GPT-4Vからの応答が正しいJSON形式で得られなかったため、本検証ではTypeScriptからのpythonスクリプトの呼び出しは保留にしました。
応答から手動でクラス名:「title_newslist」を抜き出して、データ取得することにしました。
4.データ取得
「3.selector取得」で取得したselectorを用いてデータを取得します。
selectorを指定してデータを取得するスクリプト例
import { chromium, Browser, Page } from 'playwright';
async function main(url: string, className: string) {
// Playwrightブラウザインスタンスを起動
const browser: Browser = await chromium.launch({ headless: true });
const page: Page = await browser.newPage();
// 目的のページにアクセス
await page.goto(url);
// 特定のセレクターで要素を取得
const selector = '.' + className; // クラス名の前にピリオドを追加
const elements = await page.$$(selector);
// 各要素のテキストを取得して出力
for (const element of elements) {
const text = await element.textContent();
console.log(text);
}
// ブラウザを閉じる
await browser.close();
}
const url = 'https://www.keywalker.co.jp/blog';
const className = 'title_newslist';
main(url, className);
取得例(ブログタイトルの一覧)
Google Cloud Next Tokyo ‘23 参加レポート DataHaiker ハンズオン 退職予測の復習 DataHaiker ハンズオン参加レポート ChatGPT pluginでスクレイピングを試してみた Tableau Prep2023.3で追加された機能3つを使ってみた DS協会10thシンポジウム参加レポート primeNumberさんと勉強会を開催しました! Tableau2023.3で追加された「動的な軸範囲」を使ってみた Dataiku Communityの紹介 DataikuでKaggleのSpotifyのデータを分析してみた デザインのイベント「Design I/O #1 “Introducing the Dashboard Interface Guidelines”」を開催しました! AI を用いた情報抽出システムの試作 #01 (省略)
途中で省略していますが、ブラウザ画面上の全てのブログ タイトル(81件)を取得できていました。
5.まとめ
利点
- selectorを用いたデータ取得のため、対象要素のselectorを取得出来れば、データの正確性が担保されます。
- また、解析を行ったページと同様の構造を持ったページに対しては、selectorが分かっているため通常のクローラーでデータ収集が可能になります。
欠点
- 必ずしもクラス名が付与されているとは限らないため、selectorが取得できない要素が存在します。
- 表示するクラス名の絞り込み方には確実な手順が存在しないため、絞り込みの方法によっては selectorが上手く抽出できないことがあります。
- ページ全体のスクリーンショットをGPT-4Vで解析をさせるとコスト的に厳しいため、画像の一部を切り出していますが、切り出し方よってはデータ取得対象が含まれないことがあり得ます。
- GPT-4Vを用いたselecor抽出の精度も100%ではないです。
selectorが取得出来れば、正確な情報抽出が行えると共に、既存のクローラーで大規模なデータ収集も可能になります。
しかし実際に検証を行ってみると、サイト構造への依存性が高く、上手くいかないケースが多いことが分かりました。
この方法では、取得したselectorの確認を人が行う必要があり、既存のクローラーを置き換えるのは不可能と考えられます。ただし本検証の成果を開発工数削減に適用できないか検討したいと思っています。
ShtockData(リンク)
弊社のShtockDataは、Webサイトを周期的にクローリング(巡回)し、Webページ上のデータを抽出・収集するというサービスです。
「大量データ収集」や「正確な情報収集」が行えるだけでなく、お客様の活用しやすい形にデータを整形したうえでご提供が可能です。
ご興味がございましたら、こちら(ShtockDataリンク)のページ下部にあるお問い合わせフォームよりご連絡ください。
