エンジニアの研修内容紹介と振り返り
2025年9月にデータソリューション開発部に配属されました、山崎です。
キーウォーカーに第二新卒で入社して2ヵ月が経ちました。
弊社では約2ヵ月間の研修があり、対象サイトに対してスクレイピングを定期実行するクローラーを開発します。
弊社に興味を持たれている方にイメージをしていただけるように、クローラー開発にあたって何を使って、どう開発していくのかを、本記事にまとめさせていただきました。
研修について
弊社ではShtockDataProというスクレイピングサービスを展開しています。
スクレイピングとは、 web 上の特定の情報を収集し加工する技術のことです。
ShtockDataProでは、このスクレイピング技術を活用して Web 上の膨大な情報を自動収集し、使いやすい形に整形・加工してお客様へお届けしています。
欲しいデータを探す・まとめるといった手間を削減し、ビジネスでそのまま活用できる状態で納品することが特徴です。
研修では、難易度別に用意されたサイトを対象に、最大 80 万件を超えるデータを収集するスクレイピングを実装します。
収集したデータをファイルとして出力し、納品までの一連の流れを実践形式で体験する内容になっています。
使用した技術スタックと構成
| 技術区分 |
使用技術 |
| 開発環境 |
VSCode, GitHub Copilot |
| 実行環境 |
Node.js |
| 開発言語 |
Typescript |
| ライブラリ |
axios, puppeteer, playwright |
| コンテナ |
Docker |
| オーケストレーション |
Kubernetes |
| データウェアハウス |
BigQuery |
| ストレージ |
Google Cloud Storage |
フェーズ1:データ収集
データ収集は、スクレイピング対象のサイトから必要な情報を収集し、BigQuery(Google Cloudが提供するクラウド型のデータウェアハウス)上にそのデータを格納する工程です。
イメージをしやすいように、架空の依頼と弊社のHPを使って説明をします。
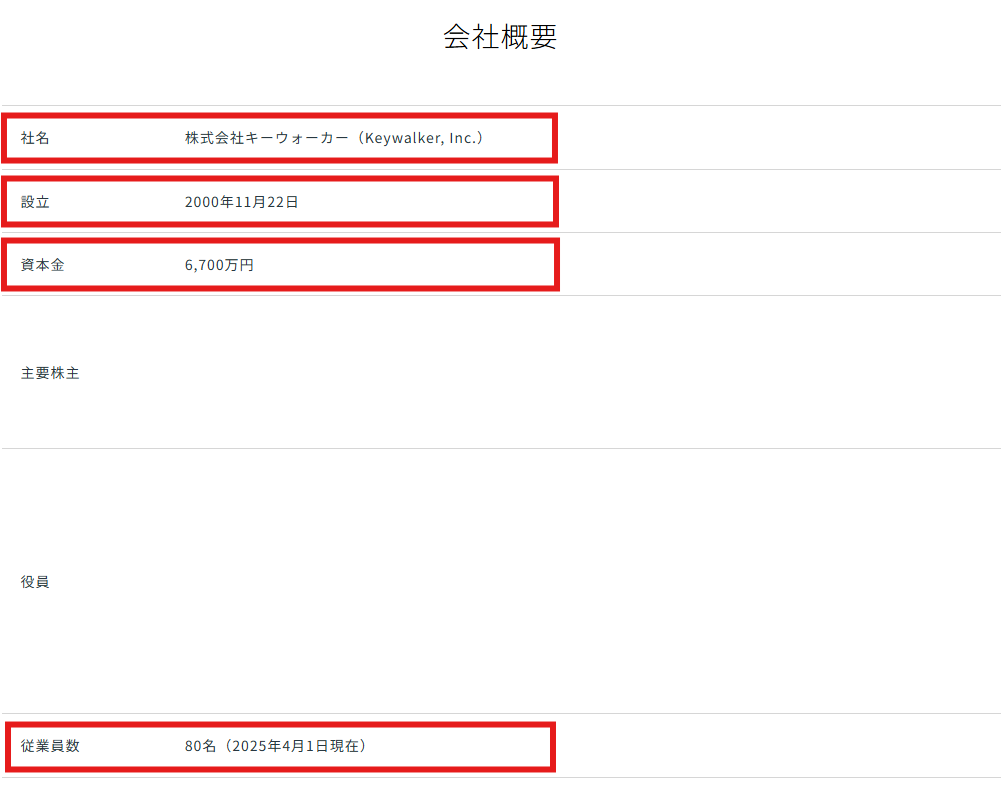
とあるお客様が「企業ごとの設立日・従業員数・資本金を調査し分析を行いたい」という目的で依頼をされたとします。
ですので、データを収集する該当箇所はおおよそこのあたりになるでしょう。
(実際にはお客様の要件を確認しますが、ここでは紹介のため暫定的に決めています)
 どのサイトから、どのような情報を、どう取るのか等の要件がある程度定まったら、開発工程に移るためウェブクライアントの選定をします。
クローラーの開発では、どのウェブクライアントを使用するかを決めるために、対象サイトが静的なサイトか動的なサイトかを調べます。
静的なサイトというのは基本的に、サーバーに置かれたhtmlファイルをそのまま配信するサイトのことです。
動的なサイトというのは骨組みのHTMLだけ予め作成されており、メインとなる部分はjavascriptで生成されるサイトのことです。
例を見てみましょう。
先ほどのKW会社概要のURLには、ディレクトリ配下のファイル名にhtmlと書いてあることがお分かりかと思います。
このような場合は静的なサイトであることが多いです。(断定するにはしっかりとした調査を行います。)
どのサイトから、どのような情報を、どう取るのか等の要件がある程度定まったら、開発工程に移るためウェブクライアントの選定をします。
クローラーの開発では、どのウェブクライアントを使用するかを決めるために、対象サイトが静的なサイトか動的なサイトかを調べます。
静的なサイトというのは基本的に、サーバーに置かれたhtmlファイルをそのまま配信するサイトのことです。
動的なサイトというのは骨組みのHTMLだけ予め作成されており、メインとなる部分はjavascriptで生成されるサイトのことです。
例を見てみましょう。
先ほどのKW会社概要のURLには、ディレクトリ配下のファイル名にhtmlと書いてあることがお分かりかと思います。
このような場合は静的なサイトであることが多いです。(断定するにはしっかりとした調査を行います。)
 動的なサイトは対照的に、URL構造だけでは判別しにくいことが多いです。
そのため、ブラウザに少し設定を加えてみます。
動的なサイトは対照的に、URL構造だけでは判別しにくいことが多いです。
そのため、ブラウザに少し設定を加えてみます。
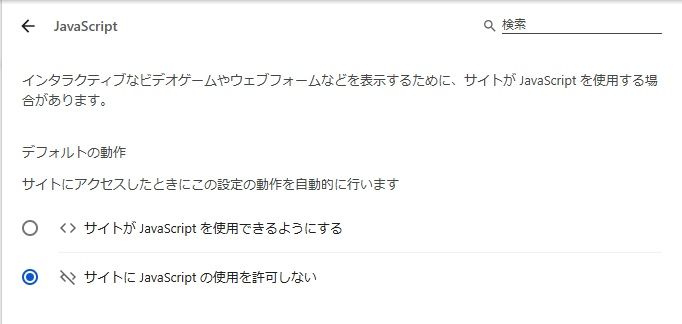 この状態で開けないサイト、または「設定でJavascriptを有効にする必要があります。」と怒られるサイトは動的な要素を含んだサイトと判別していいでしょう。
(サイトによっては、一部静的な要素、一部動的な要素が合わさって構成されているものも存在します。)
サイトの確認が完了したら、次にウェブクライアントを選定します。
弊社では静的なサイトに対してはaxiosクライアント、動的なサイトや画面操作を行いたいサイトに対してはpuppeteer, playwrightクライアントを使用します。
axiosはHTTPレスポンスの中身をそのまま受け取ってくれるので、対象のcssセレクタを指定し要素を抽出できます。
この状態で開けないサイト、または「設定でJavascriptを有効にする必要があります。」と怒られるサイトは動的な要素を含んだサイトと判別していいでしょう。
(サイトによっては、一部静的な要素、一部動的な要素が合わさって構成されているものも存在します。)
サイトの確認が完了したら、次にウェブクライアントを選定します。
弊社では静的なサイトに対してはaxiosクライアント、動的なサイトや画面操作を行いたいサイトに対してはpuppeteer, playwrightクライアントを使用します。
axiosはHTTPレスポンスの中身をそのまま受け取ってくれるので、対象のcssセレクタを指定し要素を抽出できます。
try{
const response = await axios.get("https://www.keywalker.co.jp/company/outline.html")
const ducument = response.data;// ページのhtmlコンテンツ
// 会社名(株式会社キーウォーカー)が含まれているCSSセレクタを指定する。
const companyName = [
...document.querySelectorAll("table[class*=table_company] tbody tr td")
].find((item) => item.textContent.includes("株式会社")).textContent
console.log(companyName);
} catch (error) {
console.log("GETできませんでした。",error);
}
'株式会社キーウォーカー(Keywalker, Inc.)'
対してpuppeteer, playwrightは「ユーザがアクションを起こしてレンダリングを行う」動的サイトを対象にスクレイピングを行うので、ウェブクライアントに実際のそのページを訪れてもらう操作を、ヘッドレス環境で行います。
イメージだとこんな感じです。
webクライアントに指定のURLにアクセスをしてもらう→アクセスしたページのレンダリングを実行させる→レンダリング後、対象のDOM要素を取得する。
コード上では端的に以下の様に記述をします。
// ~~~~~~~~省略~~~~~~~~
// 対象の動的サイトにアクセスをしてもらい、そのサイトで一定時間ネットワーク通信のないことで完了を判定(レンダリング実行完了まで待つ)
await page.goto("https://hogehogeCompany.jp/",{ waitUntil: 'networkidle0', timeout: 60 * 1000 })
// そのページの会社名のcssクラスがcomapyNameであるとしてconst companyName = await page.locator("h1[class*='companyName']").innerText();
console.log(companyName)
"株式会社hogehoge"
playwright, puppeteerではこのように、そのページに訪れる命令(goto)や、そのボタンをクリックさせる命令(click)など、コードベースでブラウザを操作することで要素を確定させ、動的なサイトに対してスクレイピングを行えます。
(例えば、人数、出発地、到着地、出発日などを決定しないと料金が決まらないシステムでは、その料金を取得するために、page.click()などを駆使してコードベースで操作を行う必要があります)
このようなwebクライアントを駆使してデータを収集し、BigQueryに格納をします。
フェーズ2:ファイル生成プラグラム
ファイル生成プログラムでは、収集したデータが格納されているBigQuery上から一度データを取得し、お客様の求める形でファイル(csv)を生成します。
ここで行うことはデータの整形とファイル出力のプログラム作成です。
データ整形について、例えば前述でスクレイピングした会社概要のデータがひとまずこのようにあるとします。
{
"data": {
"companyName": "株式会社キーウォーカー(Keywalker.inc)",
"establishment": "2000年11月22日",
"capital": "6,700万円",
"employees": "80名(2025年4月1日現在)"
}
}
お客様の想定のデータフォーマットが以下のようなものだとします。
| カラム |
形式 |
| 会社名 |
株式会社〇〇 |
| 設立日 |
YYYYMMDD |
| 資本金 |
単位を省いてカンマ削除 |
| 従業員数 |
単位を省いてカンマ削除 |
つまり、このフォーマットに合わせるために整形を行い、以下の結果になることが期待されます。
{
"companyName": "キーウォーカー"
"establishment": "20001122"
"capital": "67000000"
"employees": "80"
}
ファイル生成では、お客様ごとにフォーマットが異なるので、収集したデータに対して整形を行う必要があります。
そのあとは、各キーをcsvファイル内のカラムに対応付けて出力し、GCS(Google Cloudが提供するオブジェクトストレージサービス)のテスト用バケットにアップロードするまでのプログラムを作成します。
フェーズ3:監視プログラム
作成したファイルは最終的にお客様環境へアップロードを行うのですが、その前にテスト用バケットに格納されたファイルをチェックします。
そのチェックで問題が無ければお客様環境へアップロードされるというフローになっています。
ザックリと、どのようなチェックを行うのか紹介をします。
仮に前述のファイル生成でこのようなcsvファイルが作成できたとします。
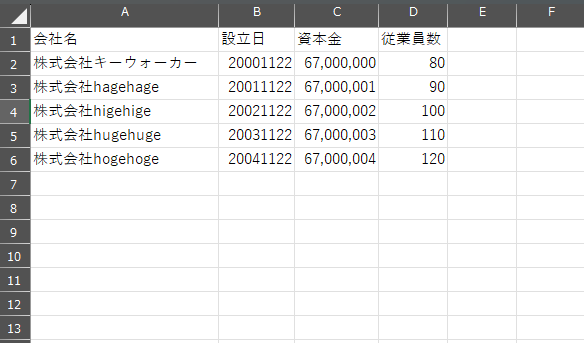 各カラムのデータについてみてみましょう。
会社名:株式会社○○という表記である…○
設立日:YYYYMMDDのフォーマットで、いずれも存在する年月日である…○
資本金:単位を省いてカンマ削除されている…○
従業員数:単位を省いてカンマ削除されている…○
見た限り、この結果から出力されたファイルに不正なデータは無いとわかります。
今は目視で行いましたが、監視プログラムでは
“必要な情報が欠けなく揃っているか、 データが定義されたルールや制約を満たしているか”
を一つ一つのデータに対してチェックを行います。(バリデーションチェック)
もし、バリデーションにエラーがある場合は社内でキャッチアップできるようにメッセージを作成し、Slack Bot経由でメッセージを投げるプログラムを作成します。
問題が無い場合のみテスト用バケットからお客様環境へファイルをアップロードし、納品が完了します。
各カラムのデータについてみてみましょう。
会社名:株式会社○○という表記である…○
設立日:YYYYMMDDのフォーマットで、いずれも存在する年月日である…○
資本金:単位を省いてカンマ削除されている…○
従業員数:単位を省いてカンマ削除されている…○
見た限り、この結果から出力されたファイルに不正なデータは無いとわかります。
今は目視で行いましたが、監視プログラムでは
“必要な情報が欠けなく揃っているか、 データが定義されたルールや制約を満たしているか”
を一つ一つのデータに対してチェックを行います。(バリデーションチェック)
もし、バリデーションにエラーがある場合は社内でキャッチアップできるようにメッセージを作成し、Slack Bot経由でメッセージを投げるプログラムを作成します。
問題が無い場合のみテスト用バケットからお客様環境へファイルをアップロードし、納品が完了します。
まとめ
弊社の研修プログラムについて3つの工程に分けて概要をお伝えしました。
- データ収集:ブラウザ操作の自動化とデータ取得の概要を紹介
- ファイル生成プログラム:データの正規化やクリーニングのイメージを紹介
- 監視プログラム:データ品質の担保とエラーハンドリングの実装イメージの紹介
いかがでしたでしょうか。
この記事が、入社後のイメージづくりの一助になれば幸いです。
おわりに
本記事では概要の紹介にとどまっておりますが、実際の業務の成果物では、単に動くプログラムを作るだけでなく、後の改修や運用を前提としたコードの書き方や、他者が理解しやすい監視の仕組みなど、一定水準の要件が求められます。
その一定水準の要件を満たすために、社内ではOJTの段階からバックアップ体制があります。
例えば、コードレビューがその一例です。
自身の書いたコードの中で、バグの可能性がある個所の指摘、コードの保守性・可読性を高めるための記述方法など、第三者だからこそできる視点で品質を向上できます。
また、開発・運用を効率化するための社内共通モジュール開発や、Claude Code, GitHub Copilotなどのツール活用に対しても積極的に取り組んでいます。
- 価値創出に向けて主体的に行動したい
- 最新技術(生成AIやLLMなど)を活用にチャレンジしたい
- 技術だけでなくビジネス視点も大切にしたい
新卒・中途問わず、そんな意欲ある仲間を歓迎しています。
少しでも興味を持っていただいた方は、ご応募・お問い合わせください。
👉 詳しくは 新卒採用ページ 、中途採用ページをご覧ください。











