はじめに
- 本記事では、弊社で精度検証中の ChatGPT を用いた情報抽出システム について、その検証結果の一部を紹介します。
- 任意の WEB ページを対象に生成 AI を用いた情報抽出を行ったところ、高い抽出性能を示したことから、これまで対応できなかった要件についても対応できる可能性を多いに感じました。
- 弊社は今後とも 「大規模言語モデル×クローラ」 について検証していくとともに、弊社クローラサービスの ShtockData における相互補完なプロダクト開発に取り組んでいきます。
おことわり
- 実装コード等の公開はしておりません。
- 本記事は情報抽出等に関心がある開発者向けの記事となります。
- 本記事は以下のブログ記事の続編となります。
背景
従来クローラ技術の課題
一般的に広く普及しているクローラ技術は、ページ構造を事前に理解した上でのセレクタ指定が前提となります。そのため、一般的なクローラ技術における課題は以下の通りです:
- 自由記述等の自然言語からの情報抽出
- ページ構造は類似しているが記述形式が異なるサイトからの情報抽出
- ページ構造が統一されていない大規模なサイト集合に対する情報抽出
上記の課題に対してアドホックな人的コストを削減すべく、本記事では言語モデルを用いた情報抽出に取り組みます。

言語モデルを用いた文書読解・情報抽出
研究の側面から
ChatGPT や GPT-4 のような大規模言語モデルを用いて、情報抽出や固有表現抽出、文章読解を生成タスクとして扱う研究もいくつか報告されており、より柔軟かつ広汎な情報抽出システムの構築が期待されています。
- Li+’23 – Evaluating ChatGPT’s Information Extraction Capabilities: An
Assessment of Performance, Explainability, Calibration, and Faithfulness
- 固有表現抽出やイベント抽出等を含む 7 つのタスクにおいて ChatGPT の抽出性能・説明可能性・キャリブレーション・忠実性を評価している。
- ラベルセットから該当ラベルを選択する設定では RoBERTa やその他の SOTA モデルに比べて性能が劣る(原因の一つは各ラベルの記述的説明が不足していたこと)一方、ラベルセットによる選択肢がない情報抽出の設定(OpenIE)において ChatGPT の優れた抽出性能・高い忠実性を示した。
- Han+’23 – Is Information Extraction Solved by ChatGPT? An Analysis of Performance, Evaluation Criteria, Robustness and Errors
- 固有表現やイベント抽出等を含む 14 の情報抽出タスクにおいて、(1) 0-shot (2) 5-shot (3) 5-shot + Chain-of-Thought の 3 種類のプロンプトを用いた ChatGPT の抽出性能を評価している。また抽出誤りにおけるエラー分析も行う。
- 実験結果より ChatGPT の情報抽出性能が few-shot で精度向上を示したものの SoTA モデルには及ばないことを示した。また Chain-of-Thought の性能向上は few-shot に比べてが僅かであることを示した。また 0-shot の設定において、タスクと関連性の低いプロンプトが ChatGPT の抽出性能に悪影響を及ぼすことを示した。
- またエラー分析から、出力形式に伴うエラーは数%程度であり、抽出対象でないエンティティの抽出や、抽出したエンティティのスパン誤りがエラーの主な原因であることを示した。
- Wang+’23 – GPT-NER: Named Entity Recognition via Large Language Models
- 大規模言語モデルにおける固有表現抽出の低性能問題が、系列ラベリングとテキスト生成のタスク性質の差異にあるという仮説を立て、固有表現抽出を生成問題として取り組む。具体的には “Columbus is a city” という入力文に対して “@@Columbus## is a city” という出力を生成する。
- また hallucination (confabulation) の問題に対処するためにタイピングされたエンティティがラベルセットに属するかの自問を誘発させる self-verification 戦略を提案する。
- 一般的な 5 つの固有表現抽出データを用いて教師あり学習のモデルと同等の性能を達成。GPT-NER が低資源かつ数ショットの設定において有効であることを示した。

- Qin+’23 – Is ChatGPT a General-Purpose Natural Language Processing Task Solver?
- NLP の代表的な 7 タスクにおいて ChatGPT の 0-shot 性能を調査する。
- ChatGPT が算術演算のような推論能力を伴うタスクで良好な性能を発揮する一方で、情報抽出の代表的なアプローチの一つである系列ラベリングのような特定タスクで課題があることを示した。
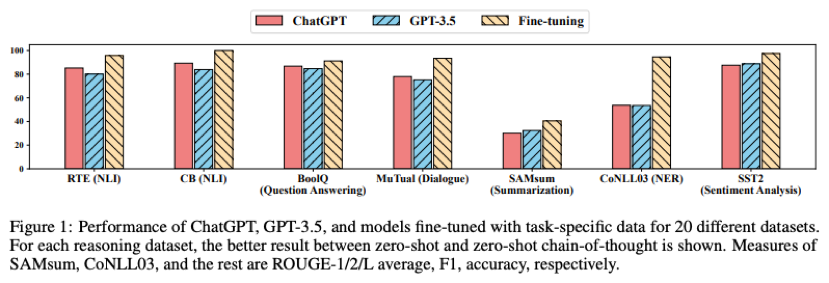
開発の側面から
- 特に ChatGPT の台頭によって、ここ数ヶ月で WEB サイトや PDF を対象に情報収集を行うプロダクトのリリースが繁多となっており、extractGPT, perplexity, ChatGPT WEB Browsing, GPT Scraper, Cheatlayer, Kadoa, scrapeghost, ChatPDF, SciSpace, Marvin といった関連プロダクトが公表されています。
- また NatBot や Mind2Web のような WEB サイトに特化した AI エージェントも提案されています。さらに LangChain から Automating Web Research 、@hellokillian 氏からはローカル環境から WEB スクレイピングを含む PC 上の一般操作を実行する Open Interpreter、Zhang氏から UI 上で直接対話を行うことでアプリケーション操作・ウェブ検索・ウェブショッピング等の一連の操作を実現する AutoUI が紹介されており、WEB からの情報収集エージェント分野について今後の技術推進が期待されています。
- 以下のブログでは PlayWright Browser Toolkit と呼ばれるブラウザと対話できるツールを使用して、任意の WEB ページから情報抽出を行う取り組みを紹介しています。
ChatGPT を用いたスクレイピング
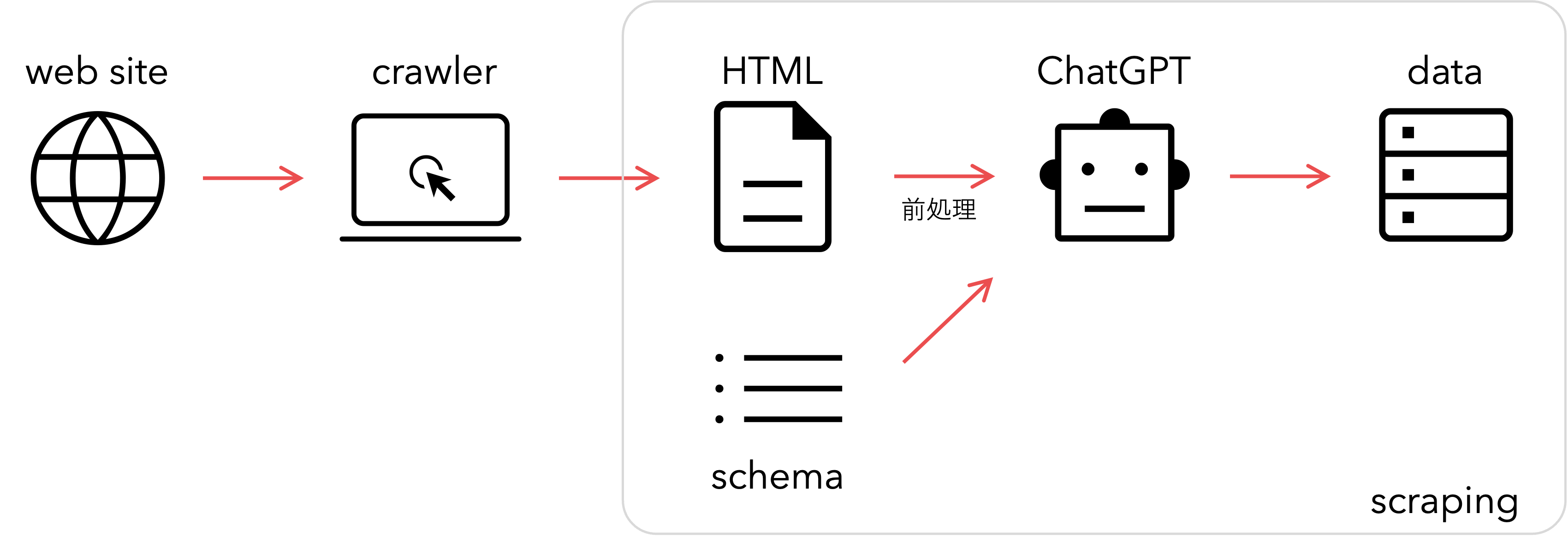
一般的なクローラ技術における人的コストの軽減を最終目的に、ChatGPT の技術発展の機会を捉えるべく、今回 ChatGPT を用いた情報抽出システムの精度検証を行いました。
以降では、弊社で開発している ShtockData というクローラを用いて事前に収集した WEB ページに対して人手で正解を付与したものを検証セットとして利用しました.
検証設定
■ 基本設定
事前に取得対象のキーが与えらる項目推定タスクとして情報収集を行いました。またモデルには gpt-3.5-turbo-16k を使用しました。
正解の判定基準は「納品可能な情報を含み、かつ簡単な正規表現で整形可能であること」 とし、予測結果を人手で判定しました。評価指標として正解率、適合率、再現率、F1 値を採用しました。
■ 検証セット
評価セットには https://www.keywalker.co.jp/company のような企業概要ページを無作為に 100 サイト選出し、正解データとして以下の項目に該当する値を人手で収集しました。
WEB サイトの HTML には JavaScript 等のプログラム言語、コメント、属性値など、推定対象に関連しない情報が多く含まれてるため、前処理として ①不要タグの除去 ②コメントの除去 ③タグ内の属性除去 ④テーブルや画像のデータ変換 ⑤その他クレンジング処理 を行ないました。
また入力プロンプトのトークン長が 16,384 を超えると予想される場合は、HTML に対してトークン数に基づく単純な分割を実施しました。
■ プロンプト
Batch Prompting の入力形式を踏襲し、ChatGPT には 「タスク指示, 制約条件, HTML, 項目スキーマ」 を入力し、各項目の値を JSON 形式で出力しました。
なお、項目スキーマは以下の通りとなります。
{
"企業名": "抽出対象の企業名(本社情報を対象とする)",
"電話番号": "${企業名} の電話番号",
"郵便番号": "${企業名} の郵便番号",
"住所": "${企業名} の住所",
"代表者名": "${企業名} の代表取締役社長および会長",
"資本金": "${企業名} の創業資本金",
"売上高": "${企業名} の特定期間の売上高",
"従業員数": "${企業名} の従業員数",
"事業概要": "${企業名} の事業概要",
"キーマン情報": "${企業名} の役員情報",
"設立年月": "${企業名} の設立年月",
"交通アクセス": "${企業名} へのアクセス方法",
"Email": "${企業名} の Email アドレス",
}
検証結果
結果詳細
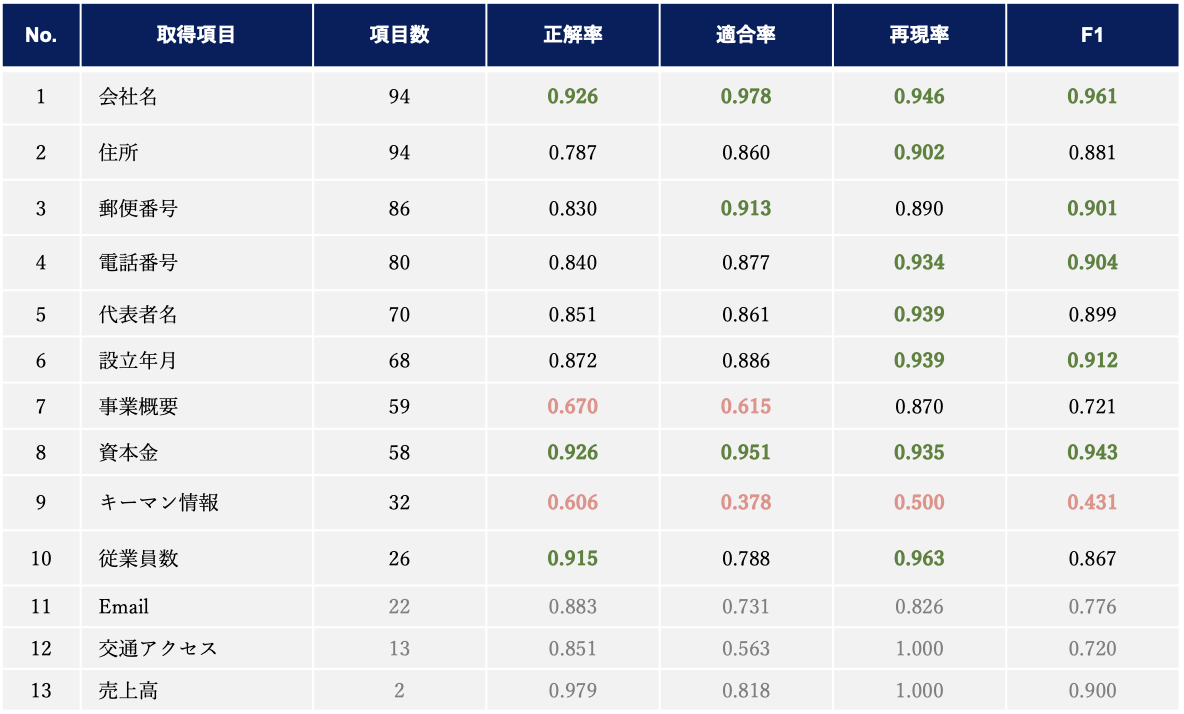
ChatGPT を用いた情報抽出の評価結果を以下に示します。なお項目数でソートしています。プロンプトの中間に位置する指示内容が反映されない問題 (Liu+’23) や、選択肢付き QA では選択肢の順番が正解率に影響する問題 (Pezeshkpour+’23) などありますが、プロンプトの内容は 検証設定 で指定した通りです。
今回の設定では gpt-3.5-turbo-4k の利用料金は 100 社あたり $0.64 程度でした。
またサイトあたりの平均応答時間は 27 秒程度となりました。request-per-minutes や token-per-minutes のような制限が存在するため、組織レベルでの大規模な利用には向かない可能性があります。
エラー分析
- タスクの難易度
- 「事業概要」や「交通アクセス」に対して回答する場合、WEB サイトからの抽出性能に加え、要約等の記述能力が問われることになります。このような複合的なタスクを伴う項目では、他の項目に比べて抽出精度が低い値となります。
- WEB ページの形式にも依存しますが、例えば取得項目がテーブル内のセルに該当する場合は抽出精度が高く、pタグ等で記述される自然言語のような場合は精度が低下します。
- スキーマの特定性
- 「キーマン情報」という指定は「取締役会長、代表取締役社長、執行役員」など複数の項目が該当することから、特定性(問題となっている名詞が具体的に指している対象を話し手が頭に思い浮かべているかどうかを表す概念)が低い項目であるといえます。当然ながら特定性の低さは抽出性能に悪い影響を与えることが分かりました。
- コンテキストの形式
- コンテキスト内にグループ会社が混在したり、電話番号が複数存在するようなページが散見されました。このように解答候補が複数存在する場合は、「080-**」 のような文字列がコンテキスト内に一つしか存在しない場合と比べて抽出精度が低い値となりました。
- 住所や電話番号等が img タグ内の画像内の視覚情報として記述されているページも存在します。このようなケースでは、クロール時点でコンテキストに正解が含まれないため正しく回答することができません。
- ハルシネーション
- コンテキストに会社情報が十分に含まれない場合に ChatGPT によるでっちあげが発生しました。
- また「住所」と「交通アクセス」のように類似する項目がスキーマ内に存在する場合、「住所」の情報から、交通アクセスがページ内に記述されていないにも関わらず、「最寄駅徒歩n分」のような生成結果が見られました。
展望
- 2023.06.14 には OpenAI から gpt-3.5-turbo-16k のようなモデルが公開されたことで、入力可能なトークン長の最大値が 4 倍程度に拡張されましたが、精度低下せずに入力サイトのトークン数を減少させることは依然として我々の課題となります。また同項目の値が HTML に複数含まれている場合も課題となります。Deng+‘23 による Sentence-BERT 等の小規模なモデルを用いたチャンク分割の実現など、効率的な抽出方法の検討も進めていきます。
- 解釈性を上げるため、抽出情報の参照元を特定する方法論についても検討する必要があります。上記のチャンク分割に加え Wang+’23 による生成モデルを用いたエンティティのタグ付けのような工夫についても検証していきます。
- WEB サイトや PDF ファイル等は、テキストによる言語情報に加え、様々な視覚情報や空間情報が保持されています。これら構成要素の意味的な関係を正しく捉え、HTML から適切な情報を収集できるような枠組みについても検証していきたいと思っています。例えば Liu+’23 で提案されている文書内の構成要素間の顕現性を考慮した手法や、LlamaIndex で提唱されている Recursive Retriever 等の階層構造を考慮した手法についても検討していきます。
- 我々は ChatGPT が従来モデルに対してどのような役割を持つか正しく理解し、文書および文書画像読解による適切なアプローチを探索していきます。
おわりに
- 本記事では ChatGPT を用いた情報抽出システムの検証における弊社の中間報告を紹介しました。
- 任意の WEB サイトとして無作為に抽出した企業概要ページ 100 件に対して ChatGPT を用いた情報抽出を実施したところ 0.80~0.90 程度の抽出精度(F1)を示すことができました。
- ChatGPT など生成モデルを用いた情報抽出ではハルシネーションチェックが必須となるため、ステークスに応じた適切な提供も進めていきます。抽出誤り等が許容されない高い抽出精度を求める場合は、弊社サービスの ShtockData の導入をご検討いただけますと幸いです。
- また弊社では ChatGPT をはじめとする大規模言語モデルを用いた開発および検証を行なっています。ChatGPT を用いたプロダクトについて興味のある方々からのご相談、ぜひお待ちしています。
関連
- Li+’23 – Evaluating ChatGPT’s Information Extraction Capabilities: An Assessment of Performance, Explainability, Calibration, and Faithfulness
- Burns+’23 – A Suite of Generative Tasks for Multi-Level Multimodal Webpage Understanding
- Arora+’23 – Language Models Enable Simple Systems for Generating Structured Views of Heterogeneous Data Lakes
- 加藤 (京都大) +’23 – 論文紹介:ChatGPT で情報抽出タスクは解けるのか? Is information extraction solved by ChatGPT? An analysis of performance, evaluation criteria, robustness and errors
- NTT人間情報研究所+’23 – Collaborative AI: 視覚・言語・行動の融合 / 第13回 Language and Robotics研究会 招待講演
著者:宮脇峻平(データサイエンス部) [プロフィール]
最終更新日: 2023.07.21
