Google Cloud Next Tokyo ‘25 データ基盤関連講演レポート
2025年8月5日(火)、6日(水)に東京国際展示場(ビッグサイト)で開催されたGoogle Cloud Next Tokyoに参加しました。都合により6日の限られた時間のみの参加でしたが、多くの学びを得た有意義な体験でした。
筆者はキーウォーカーのデータ分析基盤のチームで活動しており、データ基盤に関する以下の2つの講演が特に印象深く感じました。
- BigQueryを中心としたオープンデータレイクハウスとデータパイプライン
- データ基盤チームに休日を。データ活用を支えるBigQueryとData Product
本記事では主にこれらの講演について、内容と学んだこと、追加で調べたことを含めてまとめ、共有いたします。
イベント概要
- 日程:2025年8月5日(火)、8月6日(水)
- 会場:東京ビッグサイト 南展示棟
- 主催:グーグル・クラウド・ジャパン合同会社
- イベントページ:https://www.googlecloudevents.com/next-tokyo?utm_source=google&utm_medium=unpaidsoc&utm_campaign=FY25-Q1-japan-JAP27437-physicalevent-er-NextTokyo2025_mc&utm_content=gcbg8&utm_term=-
来年のイベントに参加される方・検討中の方へ
- 来年は2026 年7月30 日(木)- 31 日(金)に開催
- Google Cloudに関する知見があまりなくても楽しめる・勉強になるイベントだと思います。様々な分野に関して、知識と実際に協賛企業の皆様がどのようなことを行っているか見て学べますので、少しでも興味があれば足を運ばれることをお勧めします!
- 受講票(入場時やイベント参加時などに使うQRコードの印刷された紙)は事前に紙に印刷して持っていくことをお勧めします。スムーズに入場できました。ちなみにこの紙を入れて首にかけられるホルダーが会場でもらえます。
- かなり人が多いです、聞きたいセッションなどある場合は時間に余裕をもっていく方が良いと思います。セッションの事前登録も早めに行いましょう。
BigQueryを中心としたオープンデータレイクハウスとデータパイプライン
Google Cloud カスタマーエンジニア 唐澤 匠 様
Google Cloud カスタマーエンジニア 堤 崇行 様
概要
大規模データセットを管理するためのモダンなフォーマット「オープンテーブルフォーマット」は、ファイルベースのストレージにメタデータを付与して管理することができるオープンソースの情報管理体系です。一般的なオープンテーブルフォーマットの情報と、Google Cloudでオープンテーブルフォーマットをデータレイクに適用する構成についてご説明いただきました。
またレイクハウスを含むデータパイプラインの構成と、そのために必要なコンポーネントや各種機能を担うツールの役割、機能についても説明がありました。本章ではデータパイプラインに関する一般的な構成とGoogle Cloud独自の概念、データパイプラインを実現するGoogle Cloudのサービスについてまとめています。
各ツールの使われ方を含めてご紹介いただく講演内容で、BigQueryを中心としたデータパイプラインやレイクハウス実現の解像度が高まりました。これについて実際に試せるようなコンテンツを探し、試しながら学習してみたいと思っています。
Google Cloudにおけるオープンテーブルフォーマット
モダンアーキテクチャの1つ「オープンテーブルフォーマット」に関してご説明いただき、これをGoogle Cloudで実現するにはどうするかの説明につながる内容でした。
オープンテーブルフォーマットとは
- データレイクに保存されている大規模なデータセットを効率的に管理するためのオープンソースのテーブルフォーマット
- データレイク内の大量のファイル群を「テーブル」として扱えるようにする規格
- Apache Iceberg、Apache Hudi、Delta Lakeなどがある
- Google Cloud Storage、HDFSなどのような分散ストレージ上に構築可能で、大量のデータを保持しつつ高速なクエリを実現
- ACIDトランザクションをサポートし、データの信頼性と整合性を保証
- タイムトラベル機能の実装により、過去の特定時点のデータスナップショットにアクセスしたり、以前の状態にロールバックしたりすることが可能
オープンテーブルフォーマットの処理の流れ
このフォーマットでは4つのコンポーネント「クライアント」「実行エンジン」「カタログ」「データ保存場所」の間でデータや指示のやりとりが行われています。
以下は情報を読み取り処理する流れについて、講演のスライドを参考に図示したものです。
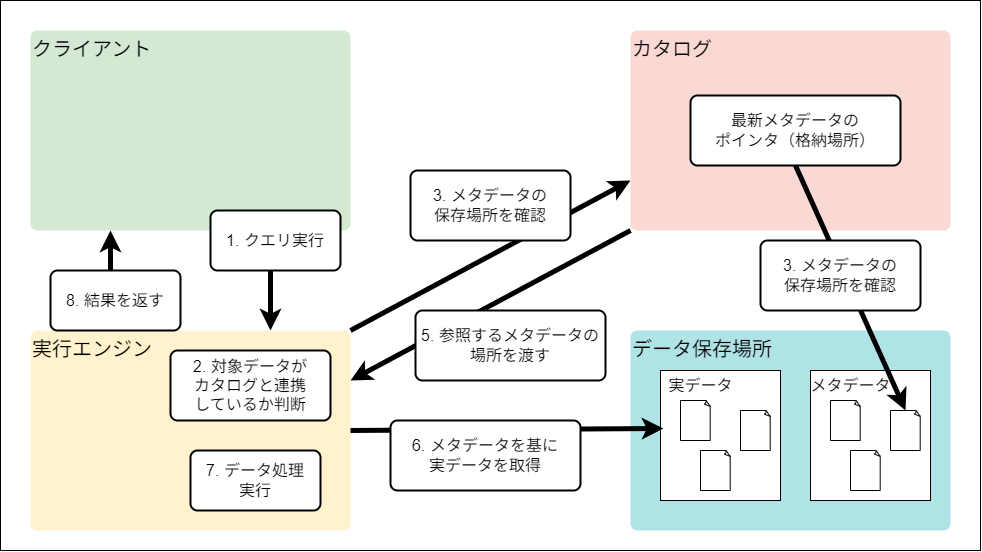
Google Cloudにおける、オープンテーブルフォーマットのコンポーネント
実際にGoogle Cloudでオープンテーブルフォーマットを実装する際の構成についてもご説明いただきました。
- クライアント:BigQuery Studio (SQLやApache Sparkの実行環境)
- カタログ:BigLake Metastore (複数の実行エンジンのための共有メタストア。Apache Iceberg RESTカタログをサポート:プレビュー版機能。)
- 実行エンジン:BigQuery (Dremel)
- テーブルパターン1 BigLake tables for Apache Iceberg in BigQuery (フルマネージドのIcebergテーブル)
- テーブルパターン2 Apache Iceberg external tables (IcebergをBigLakeでサポート)
- データ保存場所:Cloud Storage
仕組みと利点をただ知るだけでなく、どのようなツールを用いてどのようなケースに実装できるのか知ることができてより実感がわきました。
BigQueryを中心として、すでにオープンテーブルフォーマットに対応したレイクハウス構築の土台と知見が用意されているのは、自分のような初学者にとっても大変ありがたいことだと感じます。実際にやってみることで威力と仕組みを学び、「自分ならどのような場面で使うか・提案するか」を考えてみようと思いました。
データパイプライン
「レイクハウス」を中心としたデータパイプラインの構築の際にGoogle Cloudを用いるとどのようなツールで実装が叶うのかを解説していただきました。
事前知識として、データパイプラインの構成とGoogle Cloudのデータパイプライン特有の概念について説明します。
一般的なデータパイプラインの構成とGoogle Cloud独自の概念
データパイプラインとは、ここではデータをソースから取り込み(ETL)、加工を行って様々なツールで参照(Read)、もしくはシステムにデータを書き込み(リバースETL)できるように整えられた一連のデータフローを言います。
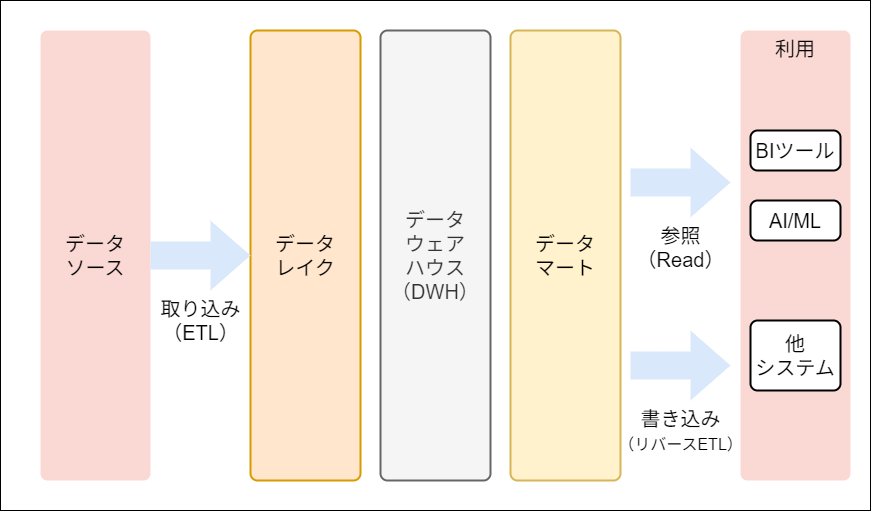
まず一般的に、データパイプラインの中でデータ管理・加工を行う部分は主に以下の3層構造で実現されています。
データレイク層
- 生データをそのまま格納する層
- 様々なデータソースから構造化・非構造化・半構造化データを加工せずに保存
データウェアハウス層
- 複数のシステムから構造化データを全社的に統合し、データ分析用に保存する層
- データレイクに登録したデータのみを用いて構築
データマート層
- 特定の目的に使用するデータのみを抽出して格納するデータベース
- データウェアハウスのサブセットとして機能
- 特定用途ごとにデータを管理することでアクセス性能を向上
データレイクハウス
Google Cloudでは、従来のデータレイクとデータウェアハウスの利点を組み合わせた「データレイクハウス」という新しいアーキテクチャが採用されています。データレイクハウスの特徴は以下の通りです。
- データレイクの柔軟性とデータウェアハウスの構造化・管理機能を統合
- 構造化・非構造化・半構造化のすべてのタイプのデータを単一プラットフォームで管理
- 複雑なETLパイプラインによるデータ移動・処理・重複を削減
- 低コストストレージと高度な管理機能を同時に提供
メダリオンアーキテクチャ
Google Cloudのレイクハウスでは、「メダリオンアーキテクチャ」が採用されています:
Bronze層(ブロンズ層)
- データソースから収集した生データをCloud Storageにそのままの形で蓄積
- 後のレイヤーのためにデータを加工しても、生のデータを保持
Silver層(シルバー層)
- Bronze層のデータをBigQueryに取り込み、クレンジングや構造化を実施
- 重複排除済みのトランザクションデータや顧客マスタなどを格納
- アドホックな分析や機械学習への利用が可能な状態
Gold層(ゴールド層)
- Silver層のデータを元に、ビジネス要件に合わせた集計や機械学習モデル作成
- BIツール(Looker)やAI(Vertex AI)から活用できる状態に整備
- より非正規化され、多くのユーザーから利用される準備が完了
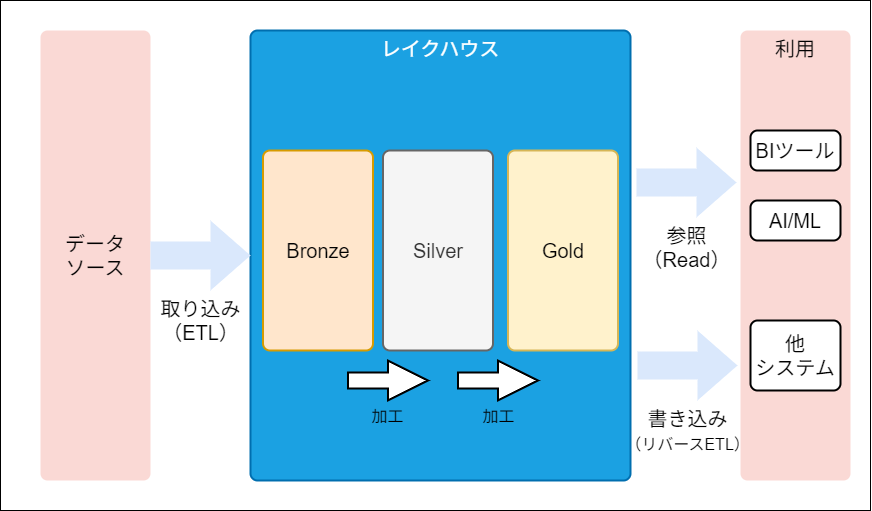
Google Cloudを用いたデータパイプライン構築のアイディア
データパイプラインの構築に使えると講演内でご説明いただいた各サービスについて、とくに詳しくご説明いただいたものをまとめました。
Pub/Sub 単一メッセージ変換(SMT)
データ取得に用いる。ストリーミング取り込み用メッセージングサービスPub/Sub内で、追加サービスを使わない軽量なデータ変換を実行。
Dataflow
ETLに用いる、ApacheBeamのマネージドプロダクト。バッチ処理でのデータ取得、ストリームでのリアルタイムのデータ取得の両方を可能にする。
元々専門性が高く使いづらかったBeamsに対してDataflowはテンプレート機能により少し扱いやすくなっていた。現在、DataflowはYAML形式で少ない記述量でのデータ処理フロー作成ができたり、「ジョブビルダー」でグラフィカルインターフェースでの簡単なデータ処理パイプラインの作成が可能になっていたりと、より使用する敷居が下げられている。
BigQuery
データパイプラインに使える機能がどんどん拡充されている。
リバースETL:EXPORT文を用いることで、「Cloud Spanner/Bigtable」や「Pub/Sub」へのリバースETLが可能。例えば、Cloud SpannerのデータにBigQueryで大規模パッチ処理を適用し結果をリバースETLで返すといったことも可能。
継続的クエリ:SQLベースで受信データの継続的なリアルタイム分析処理が可能になる。またリアルタイムに生成AIによる分析を行う機能を備えたパイプラインも実装できる。
ワークフロー・オーケストレーション
- Cloud Composer: Apache Airflowベースのデータパイプラインオーケストレーション
- Workflows: サーバーレスワークフロー管理サービス
- BigQuery パイプライン: BigQuery関連のアセットをワークフローとしてまとめ、スケジュール実行できる機能
AIを用いたデータパイプライン構築
また、データパイプラインの中にどんどんとAIやAIエージェントが入ってきて様々な機能を担っているという話も伺えました。
例えば、BigQueryの「データ準備」ではGeminiを活用してのデータ準備ができるようになっています。また「データキャンパス」のようなGeminiを用いた対話によってデータ探索からクエリ作成、可視化、分析サマリーまでを一つのキャンバス上で完結させ、非エンジニアでも直感的に高度なデータ分析ワークフローを構築できる機能も用意されているようです。
この講演ではAIを用いた機能に関して詳しいお話はあまりありませんでしたが、データ加工・分析能力がより万人の持ちうるものになる未来が近づいていることに希望を感じました。
感想
私はオープンテーブルフォーマットに関して全くと言っていいほど知見がなかったのですが、今後大規模データの処理や分析基盤を作成する際に知っておくべき仕組みだと感じました。大量データに対して高速という点はもちろんですが、信頼性と整合性、特定時点のスナップショットを得られるという点もデータ基盤構築においてとても重要だと感じます。
データパイプラインの構築についても、知らないツールや名前だけ知っていたがどの部分でどう使うかを知らないツールなど、多くのツール・サービスを具体的にデータパイプライン上での役割毎に紹介していただきとても勉強になりました。
また、ツールやサービスの増加と拡大、AIエージェントなどのAI技術の発展によりますます多くの人がデータ基盤・データパイプラインに携われるようになっていることを実感しました。これらすべてにキャッチアップするのは難しいことですが、このような流れがあることを把握しつつ、間口が広がっている今だからこそ「やってみよう」の精神で積極的に試しながら知見を広げたいと思いました。データパイプラインについてはGoogle Cloud Skills BoostにBigQueryを用いてデータフローを構築するハンズオンがあるので、実際にトライしてみようと思います。
データ基盤チームに休日を。データ活用を支えるBigQueryとData Product
Google Cloud Data Analytics Specialist 村上 祐磨 様
概要
データ基盤チーム、つまり企業内の「情報システム部」など、データを扱う部署はなぜタスク量が膨大になってしまうのか。その分析と一般的な企業でのケースをまとめ、その現状を打破しうるデータ基盤のあり方として「データメッシュ」「データプロダクト」「データコントラクト」の相互作用というデータアーキテクチャをご紹介いただきました。
本記事ではこれらの概念について少し踏み込んで調査を行い、まとめました。また講演ではこのアーキテクチャのGoogle Cloudでの実装例も交えて説明がありました。
大きな問題を解決しうるアーキテクチャではありますが、このアーキテクチャの導入をただ行うだけでは問題が解決するとは限りません。まずは少しずつ導入し、組織へ浸透・拡大させていくプロセスが問題の本質的な解決に肝要であると思われます。
データ基盤チームの抱える問題点
生成AIでデータ基盤チームの仕事が増える
昨今、生成AIの登場などでデータの利用・分析が容易になっています。しかしこれらの分析を行う際は、人間にも生成AIにも正しいデータを正しい手法で参照してもらう必要があり、結果としてデータチームのタスクは寧ろ増加につながっていると考えられます。
データ基盤チームはなぜ忙しいのか?
データ基盤チームは「ドメイン」どうしの間に立つ仕事であり、社内コミュニケーションの中継地点となっています。
ここで、今後用いる言葉について簡単に整理します。
- ドメイン:ここでは組織内の様々な部門のこと。
- プロデューサー:データを用意する、あるいは持っているドメインのこと。例えば、顧客データを持っている「営業部」や会計データを用意する「管理部」などが該当する。
- データユーザー:データを用いて分析業務などを行うドメインのこと。「Consumer」とも。例えばBIツールを用いて可視化を行うチームや、生成AIアプリケーションを作成する開発者などが該当。
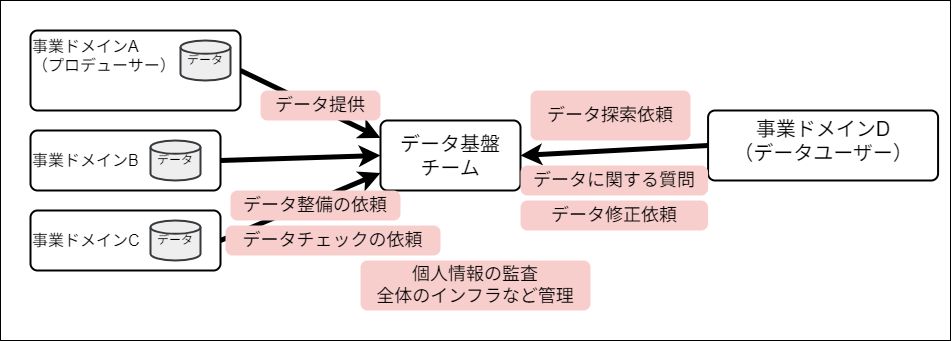
プロデューサードメインとユーザードメインはデータ活用に際してそれぞれデータに関する問い合わせや要望をやり取りしますが、データ基盤チームが間に入っているようなシステムにおいてはそれらすべてのコミュニケーションが基盤チームを介して行われます。これにより本来組織全体で担うべき責任が集中してしまい、この状況では基盤チームがボトルネックになりかねません。
基盤チームをボトルネックにしないデータアーキテクチャとは?
これを避けるためのデータアーキテクチャが「データメッシュ」「データプロダクト」「データコントラクト」の相互作用です。
- Data Mesh (データメッシュ):データを非中央集権的に分散させる文化
- Data Product (データプロダクト):データメッシュを構成
- Data Contract (データコントラクト):データプロダクトを支える
データ基盤チームは個々のデータの管理ではなく全体のガバナンスや共通基盤の管理など、横断的な役割に集中する仕組みを目指します。
データメッシュとは?
データメッシュは、データを分散させるアプローチとそれを動かす「文化」という説明でした。具体的には、データを持ち提供するプロデューサードメインをデータのオーナーと定め(オーナーシップを移譲)、基盤チームは各ドメイン同士の連携や横断的な管理に集中するというアクションが考えられます。
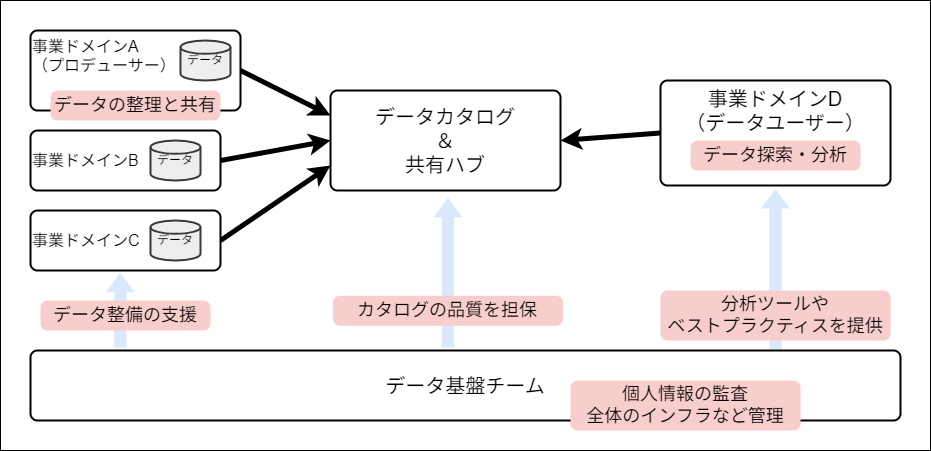
データメッシュが実現するのは「非中央集権的なアーキテクチャ」です。各プロデューサードメイン→中央データベース→各ユーザードメインの流れがある中で、様々なデータが各ドメイン間で網目(メッシュ)のようにやり取りされるということでこのような名前になっているようです。
データメッシュアーキテクチャには根幹に4つの原則があります。
- ドメイン主導のオーナーシップとアーキテクチャ
- プロダクトとしてのデータ
- セルフサービス型データ基盤
- 横断的なガバナンス
特に1,2を実現するのに必要なのが、後述の「データプロダクト」であると思われます。
データプロダクトとは?
データプロダクトは、データメッシュ実現のために各ドメインがデータをどのように扱うかの指標となる考え方です。ただデータを集めるのではなく、迷わず安心して使えるようパッケージ化された、価値あるデータ製品をプロデューサーが用意します。
具体的には以下のような情報を含むことが求められます。
- データ本体
- メタデータ・ドキュメント
- スキーマ / テーブル・列の説明
- 分析例(サンプルのSQL/Notebook/Canvas)
- 品質基準
- データ品質テストとその結果
- SLO (日常運用品質を担保) / RTO (障害時の復旧許容時間)
- データアクセスの担保
- データへのアクセス権 / 権限管理方法
- エージェント
- データカタログでの検索可能性
これらの基準やルールはデータ基盤チームが全社的に管理し、それに基づいて各プロデューサードメインがデータプロダクト化を行います。
データコントラクトとは?
データコントラクトとはデータの仕様を人間・機械が理解可能なように整備したものです。GoCardlessのAndrew Jonesによって2021年ごろ提唱されたものであると説明がありました。
この考え方の下で各プロデューサーは、データのスキーマなどの情報(どんなデータがあるか)だけでなく「そのデータがどんなルールを守って作られたのか」「そのデータはどの頻度で更新されるか」など様々な仕様情報をまとめ、それをAPI経由でアクセスできるようにします。
API経由で機械的に仕様にアクセスできることで、データ品質チェックやデータ取得など様々なタスクをルールの範囲内で自動化できるようになります。
データコントラクトの使い方は大きく2通りあるということでした。1つ目は「プロデューサー側でコントラクトの作成・提供」と「コントラクトを満たしているかのチェック(バリデーション)」まで行う方法。プロデューサーはコントラクトを満たさないデータはそもそも提供できず、ユーザーは受け取ったデータが「コントラクトの仕様を満たしている」ことを信頼して使います。データユーザの負担が少なくデータ活用を促進しやすい形式です。
2つ目がプロデューサーが提供したコントラクトに基づいてバリデーションはユーザー側で行うという方法です。プロデューサー側で品質の担保が行えない場合や利用者側が要求する品質期待値が非常に高い場合などにはこちらが推奨されるそうです。
Google Cloudにおけるデータアーキテクチャ
Google Cloudでどういうツールを用いればこれらが実現できるか、についてもご紹介いただきました。以下はデータメッシュをGoogle Cloudのサービスを用いて実装する一例です。
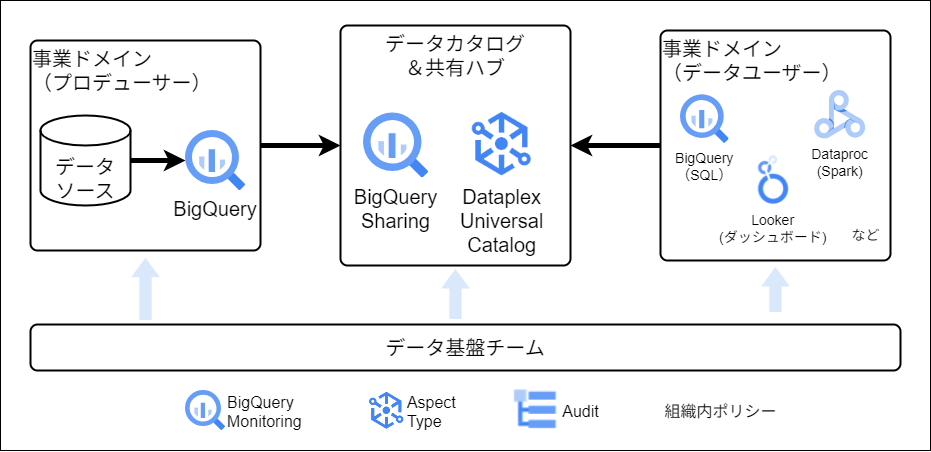
データアーキテクチャだけで問題は解決しない(かもしれない)
最後の話題は「アーキテクチャだけでデータ基盤チームの問題が解決するとは限らない」というお話でした。ドメイン単位に分割されたものの、ドメイン内でデータ担当が分断され、ビジネス担当との折衝に悩む…結局は問題の場所が移動しただけ…
とならないように各所での考え方の変化も必要です。こういった点も踏まえて最初から全社で変革に取り組むのではなく、最初は局所的に導入して少しずつ拡大していくのが良いでしょう。
まとめ
- データ基盤チームは構造上多忙になりがち
- データアーキテクチャの改革で負担の軽減を目指す
- Data Mesh:権限とともに問題を分割・移譲する
- Data product:価値あるデータを定義し組織に広める
- Data Contract:データ仕様を定義し自動化も拡大する
- ビジネスの相互理解と合わせて少しずつ導入、負担をコントロールしてやがて休日を取り戻す!
感想
一連のデータアーキテクチャの考え方は「データ民主化」に向けた取り組みの1つとして、多くの人に知ってほしいと強く感じました。データ活用を組織で推進する1つのソリューション案として、また「データの属人化」という大きな問題を解決するポテンシャルを持つフレームワークとして、正しく理解した上で情報を周知していきたいと思います。
より細かく考えると、データプロダクトを実現するニーズは今後も高まっていくことを感じています。キーウォーカーでもデータプロダクトを実現するためのルール作りやワークショップの整備を行い、お客様がスムーズにデータプロダクト化を推進するための体制を整えることが急務だと思いました。
データコントラクトはAPIで提供という形で紹介されましたが、重要なのは「データ提供元とデータ提供先でオーナーシップがあり、受け入れの要件を合意できる。また、データが実際に受け入れ要件を満たしているか継続的に監視できる体制が存在する。」という点だと感じました。これを実現するツール・形式は企業などによって異なるので、講演でご紹介いただいたGoogle Cloudのサービスを含め、適切なものを選び用いる必要があると思いました。
おわりに
本イベントはやはりAI時代の到来を実感するもので、イベントとしてのコンセプトもAIに寄ったものでしたし、生成AI関連の講演や協賛ブースも非常に多かったように感じました。その中で、生成AIを代表とした新技術の根本には質の高いデータを保持する環境が不可欠という認識を持っていたので、2つの講演はそのベースとなる「データ」や「基盤」の観点でのお話をいただき、筆者の普段の業務にもつながる内容が多く、拝聴できてよかったです。
データを適切な形式で保持し、組織内で適切にそれらをやりとりする一連の考え方。およびそれを企業に導入・提案する際の手順・構成と導入する理由。これらを今後学び整理したうえで業務に生かしていきたいと思いました。
キーウォーカーでは分析基盤構築の支援を行っています。本イベント・講演でキャッチアップしたテーマを含めたサービスのアップデートも検討しておりますので、この記事を読んで興味を持った方がいらっしゃいましたらぜひお気軽にご相談ください。
スピーカーの皆様、貴重なお話をありがとうございました!
