少し前に話題となったbrowser-useですが、こちらは生成AIにブラウザを操作させることでユーザの代わりにデータの取得や作業をさせることができるPythonのパッケージです。 今回はbrowser-useの所感を紹介いたします。
browser-useとは?
公式ホームページでは、以下のような特徴を謳っています。
- 視覚的な情報とHTMLの構造データの組み合わせによる理解
- 複雑なタスクや並列実行時における複数タブの管理
- 一貫性のある動作のためのHTML要素追跡
- データベース操作、ユーザによる入力処理などの独自のアクションを導入可能
- 自動回復機能による、より堅牢なワークフローの自動化
- 様々なLLMのサポート
今回は試しにOpenAIのLLMを使っていくつかワークフローの自動化を実現してみたので、紹介します。
実行環境の準備
基本的に必要なパッケージはPyPiにまとまっているため、環境さえ整っていれば簡単に導入することができます。Python 3.11以上が要求されているため、今回の検証ではpyenvで3.12.10をインストールしました。
以下のコマンドを実行することで、パッケージ本体と自動化ブラウザのインストールが完了します。
pip install browser-use playwright playwright install
また、LLMを使う都合上、APIキーをあらかじめ取得する必要があります。各々の利用方法はLangChainの使い方に従うようです。今回はOpenAIのAPIキーを使うことにしますが、Geminiなど様々なサービスの利用が可能です。将来的にはローカルのLLMも利用可能になるよう、開発が進められているそうです。
早速使ってみる
今回は2つのシチュエーションを想定して、実際にLLMにブラウザ操作をしてもらいました。全体的には公式ドキュメントのものを参考にしています。
ニュース記事の要約
1つ目のワークフローとして、ニュースの要約を自動化してみます。通常のLLMへのプロンプトと同様に、タスク内容の齟齬が出ないように比較的丁寧に定義します。
from langchain_openai import ChatOpenAI
from browser_use import Agent
from dotenv import load_dotenv
load_dotenv()
import asyncio
llm = ChatOpenAI(
model_name = "gpt-4o",
)
async def main():
agent = Agent(
task = """
あなたは、今日のニューストピックスを調査・要約して提供するエージェントです。
調査対象とするサイトは以下の通りです。
- https://news.yahoo.co.jp/
調査手順は以下の通りです。
1. 上記のサイトにアクセスし、最新のニューストピックスを調査してください。
2. 調査したトピックスの中から、特にホットなトピックスを3つ、ITに関連するトピックスを5つ選んでください。これはあなたの判断のみで行います。
3. 選んだトピックスのそれぞれのページに遷移し、内容を要約してください。
4. 要約した内容を、ホットなトピックスとIT関連トピックスに分けて出力してください。
""",
llm = llm,
)
result = await agent.run()
print(result)
asyncio.run(main())
このコードを実行すると、以下のようにクリック可能な要素がハイライトされたブラウザが起動します。LLMが現在のページの状態、今までの行動履歴などを加味して次のアクションを自律的に決定しながらワークフローを完遂する様子を見ることができます。
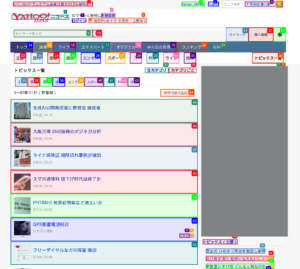
INFO [agent] 🎯 Next goal: Navigate back to the IT section to continue selecting and summarizing the next articles.
INFO [agent] 🛠️ Action 1/1: {"go_back":{}}
INFO [controller] 🔙 Navigated back
実際に生成された要約文は以下の通りです。プロンプトに日本語での出力を指定していなかったためか、英語と日本語が混在する出力となってしまいました。しかし、それぞれのニューストピックスの詳細ページに入って内容を要約できているようです。
### Hot Topics Summary: 1. **Expo Sentiment Analysis** - Title: 大阪万博 SNS投稿のポジネガ分析 - Summary: This article analyzed the mixed sentiment on social media regarding the Osaka-Kansai Expo that began on April 13, 2025. Positive reactions focused on the enjoyment of pavilions while negative comments criticized political aspects. Instagram showed more positive sentiments. 2. **NTT Docomo's New Logo** - Title: ドコモ、赤い“NTTマーク”が付いた新コーポレートロゴ発表 - Summary: NTT DoCoMo revealed its new corporate logo featuring the 'Dynamic Loop' to align with parent company NTT's rebranding. The logo retains Docomo Red hues. 3. **Nico Nico Membership Decline** - Title: Nico Nico's Drop in Premium Members and Reasons Behind It - Summary: Nico Nico's premium membership decreased to 989,000, primarily due to VISA payment issues and cybersecurity incidents affecting operations. ### IT-Related Topics Summary: 1. **Generative AI Incentives** - Title: 生成AIの開発・促進に懸賞金 総額約8億円 経産省などが募集 - Summary: The Japanese government launched an 800 million yen prize project to promote the development and implementation of domestic generative AI. 2. **JAPANNEXT 5K Monitor Launch** - Title: JAPANNEXT JN-27IPS5K-C9 Launch - Summary: JAPANNEXT announced the launch of a 27-inch 5K monitor alongside other models like the 4K JN-i27U-C6. 3. **Mobile Data Pricing Changes** - Title: スマホ通信料 値下げ時代は終了か - Summary: Major carriers like NTT Docomo announced pricing strategies suggesting the end of the reduced mobile data pricing era. 4. **LINE Image Quality** - Summary: Discussed options for sending higher quality images via LINE by changing default compression settings. 5. **NTT Financial Summary** - Summary: Detailed NTT's financial performance, future projections, and strategic plans involving branding and global business changes.
今回のタスクは複数のページを往復するタスクな上、browser-useはページのスクリーンショットを読み込ませてモデルが判断する仕組みのため、入力トークン数が大きくなる傾向があります。なお、出力トークン数は入力に比べるとかなり小さく、無視できるレベルです。
ログインのあるワークフロー
browser-useにはセンシティブな認証データなどをセキュアに利用できる仕組みが用意されています。この仕組みを利用することで、「LLMにログインしてもらい、予約履歴のデータを取得する」といったワークフローを自動化することができます。
ここでは実験のためだけのwordpressをdockerで起動し、ログインを自律的に行うことができるかを検証します。その上で、今日のNVIDIAの株価を調べてもらい、その結果をwordpressに日付とともに記録するタスクをLLMに依頼するため、以下のようなコードを作成しました。
sensitive_dataを利用するワークフローの場合、allowed_domainsによるアクセス可能なサイトのドメインは常に設定しておくようにします。これはLLMの挙動次第では全く無関係のサイトにログイン情報を入力してしまうなど、セキュリティ上のリスクを抑えるためです。
from langchain_openai import ChatOpenAI
from browser_use import Agent, Browser, BrowserConfig
from browser_use.browser.context import BrowserContextConfig, BrowserContext
from dotenv import load_dotenv
load_dotenv()
import asyncio
llm = ChatOpenAI(
model_name = "gpt-4.1-mini-2025-04-14",
)
browser_config = BrowserConfig()
context_config = BrowserContextConfig(
allowed_domains = ["localhost", "www.google.com"],
)
browser = Browser(config = browser_config)
context = BrowserContext(browser = browser, config = context_config)
# 実際は環境変数などに格納するのが望ましい
sensitive_data = {
"wp_username": "sample-user",
"wp_password": "***********"
}
async def main():
agent = Agent(
browser_context = context,
task = """
あなたは指示された株価をwordpressに投稿することで記録する作業を任されました。
以下の手順に従ってください。なお、全てのコンテンツは日本語で記述してください。
1. https://www.google.com/finance/quote/NVDA:NASDAQ\ にアクセスし、今日のNVIDIAの株価・概況と今日の日付を取得します。
2. http://localhost:8080/wp-admin\ にアクセスし、 wp_username と wp_password を使ってログインします。
3. 新規投稿を作成します。投稿ページを開くことで「投稿を追加」というボタンを選択できます。タイトルは先ほど取得した今日の日付、本文はNVIDIAの株価の概況を書きます。例えば、その日の上昇幅や、終値などに言及します。
4. 投稿を公開します。公開ボタンは複数回押す必要があるため、確実に投稿できているか確認しながら行ってください。
""",
llm = llm,
sensitive_data = sensitive_data,
)
result = await agent.run()
print(result)
asyncio.run(main())
実行してみると、早速株価の情報を調査し、以下の画面で認証情報を入力してログイン、無事に投稿することができました。


今回の試行では比較的簡単なタスクのためにgpt-4.1-miniを利用しました。ただし、パラメータ数の小さいモデルを使うと、より詳細な部分を指示しないと操作が途中で終了してしまうなどの不具合に繋がるため、実際の自動操作の様子を見ながら調整することが必要です。
おわりに
今回はブラウザの操作を含むワークフローを自動化できるPythonのパッケージbrowser-useを実際に利用してみました。以前、smolagentsを利用したエージェント作成を試したことがありますが、それと比較してこちらの方がよりスクレイピングの色が濃いように感じました。
冒頭に紹介したカスタムアクションなどを使うと、製品の価格調査など幅広いタスクに応用可能だと思います。しかしながら、生成AIがその処理に介在する以上、開発者の意図した通りに動かなかったりなどする可能性が大いにあります。
特にデータ数が多くなってくる場合には、さまざまなパターンに対応するようチューニングする必要があるため、実用的な利用には人手による開発は必要不可欠です。生成AIの力を最大限に活かしつつ、人間の判断や介入を適切に組み合わせることにより、より信頼性のある頑健な自動化フローを構築することが重要です。











