はじめに
Tableau Conference 2026 で紹介された新機能 Composable Data Sources について取り上げます。
Salesforce+ で公開されている動画の中にも、この Composable Data Sources に詳しく触れているセッション(Salesforce+:Modular by Design: Scaling with Composable Data Sources)がありました。そこで本記事では、動画から読み取れる範囲で「Composable Data Sources とは何か/何が変わりそうか」を整理したうえで、Keynote で発表された 「Agentic Analytics Platform」 の方針とどうつながりそうかを、筆者の解釈として考察します。
あわせて、6月の GA(一般提供)に向けて、Tableau ユーザー・利用企業が今から準備しておくべきことも、実務目線でまとめます。
なお、2026/5/27現時点では公開情報ベースの整理であり、仕様や提供時期・範囲は今後変更される可能性があります。最新情報は Tableau の公式リリース/アナウンスをご確認ください。
弊社としても引き続き情報を追い、アップデートが出次第、内容を補足してまいります。
参考リンク
【Tableau Conference 2026レポート】分析は「見る」から「実行」へ。ビジュアライゼーションツールを超えたTableau の進化系Composable Data Sourcesについて
- パブリッシュされたデータソース同士を組み合わせ(リレーションシップ)して、1つの合成データソースとして使える
- その合成データソース自体を公開でき、他のワークブックやPulse/APIでも再利用できる
- 上流のデータソース更新が下流にライブに反映され、複製・ロジック乱立を減らせる
AI時代の前提は「信頼できるデータ基盤」
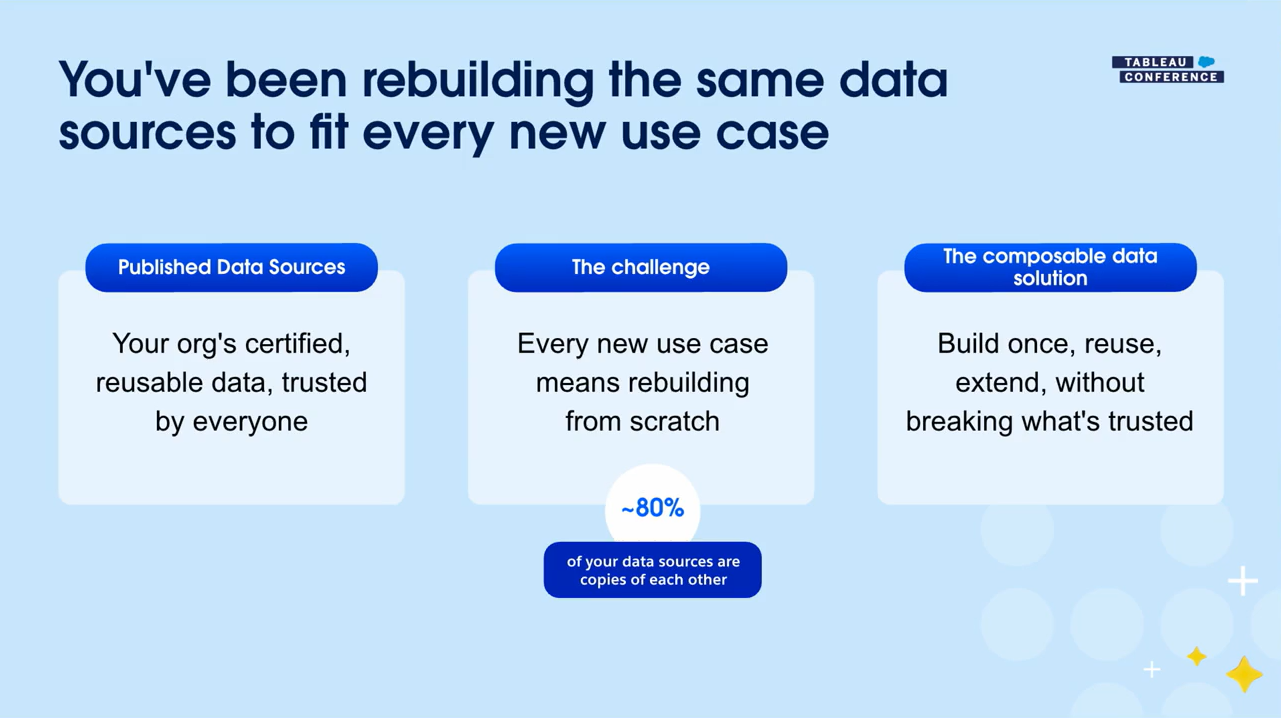
AI/エージェントが意思決定やアクションに関わるほど、データ定義のブレ(同じ在庫でも部署ごとに定義・計算が違う等)がそのまま誤判断を増幅します。そのため、Trusted / Governed / Connected なデータ基盤が必要です。
Tableauのパブリッシュされたデータソースは信頼の背骨だが、現実には複製が起きる
2026/5/27現時点ではパブリッシュされたデータソース同士の結合・リレーションシップが出来ません。
そのためユースケースに合わないと、パブリッシュされたデータソースをクローンして少しずつ変えたものが大量発生し、ロジック(計算フィールド)が組織内で乱立してエラーの温床になります。
解決策が Composable Data Sources(コンポーザブル・データソース)
パブリッシュされたデータソース同士をレゴのようにリレーションシップで組み合わせ、必要なら拡張し、合成したもの自体を再公開して再利用できるようにします。さらに、上流のパブリッシュされたデータソース更新が下流(合成データソース)に ライブに追随します。
大規模化に備えた体験もセットで提供
階層表示の切替、折りたたみ、未使用要素の非表示など、複雑さを扱うためのUI/機能も Composable Data Sourcesに対応しています。
「Agentic Analytics Platform」 との関係性の考察

- ガバナンスは守りつつ、現場は組み合わせで柔軟に拡張できる設計
- 複製をルールで禁止するのではなく、再利用した方が得になるように誘導する思想
- 依存関係(上流→下流の更新反映)や見せ方まで含めて仕組み化する思想
「中央集権の統制」と「現場の柔軟性」を両立させる設計
認証・ガバナンスされた中核(パブリッシュされたデータソース)を壊さずに、現場は必要に応じて別のパブリッシュされたデータソースを足して拡張できる、という二層の考え方です。
再利用がデフォルトになるプロダクト化
人の頑張りやガイドラインで「複製するな」を徹底するのではなく、再利用した方が自然に得する(組み合わせて公開できる、反映も自動)仕組みに寄せている。
依存関係をプロダクトとして扱う
「上流が改善されたら下流も更新される」を運用ルールではなく、ライブ接続としてプロダクトに組み込むという考え方です。協業を前提にした設計になっています。
既存の権限・Extract・フィルター等を壊さず拡張する
新概念を入れても、権限モデルや Extract、データソースフィルターといった既存資産をそのまま使えるようにし、導入障壁を下げています。
複雑化するのを織り込み済みで、UI/可視化でマネージする
機能追加で複雑さが増えることを前提に、「階層の表示切替」「折りたたみ」「未使用の非表示」など 複雑性を制御する体験も一緒に作り込んでいます。
Composable Data Sourcesが担う役割

Tableau資産をKnowledgeとして扱う流れ
Keynoteでは「AIにできないのは分析への信頼を作ること」という趣旨のメッセージがあり、Data ではなく信頼できる Knowledge(定義・セマンティクス・パブリッシュされたデータソース等)が重要だと受け取りました。
セッション「Modular by Design: Scaling with Composable Data Sources」では、まさにそのKnowledgeの中でも中心に置かれている Published Data Sources(パブリッシュされたデータソース)を「増やさず、壊さず、再利用する」ための仕組みについて語っています。
「Knowledge Graph」構想の入力品質を上げる役割
Knowledge Graphは「どのデータが何を意味し、どう関係しているか」をAIが理解できる形にする構想、と捉えることが出来ます。
Composable Data Sourcesは、データソース間をリレーションシップでつなぎ、依存関係(上流→下流)をライブで維持するので、Knowledge Graphが扱う関係性を安定して増やす方向性と相性が良さそうです。
- 複製が多い世界:同じ意味のロジックが複数に分裂し、グラフ上の正しさが揺れる
- Composableな世界:中心の認証済み/統制済みソースを保ちながら拡張でき、関係性も追随する → グラフの信頼できる接続が増える
「See → Do」=「Agentic Analytics」を成立させる土台
実行(Do)に踏み込むほど、誤った指標定義・集計ロジックは事故につながります。
Composable Data Sourcesはこの点で、
- 一つの真実(single source of truth)を作りやすく
- それを 各所に再利用しやすく(ワークブック/Pulse/API)
- 上流変更の反映も自動化する
= 実行可能な分析に必要な「信頼できる前提」を整える機能、と位置づけられます。
「Take your trusted knowledge anywhere」=配る先を増やすための部品化
Composable Data Sourcesは、信頼できる知識(パブリッシュされたデータソース)を 部品化して組み合わせ・再公開できるので、届ける知識をメンテしやすい形に変える取り組みです。
- これまでは:ユースケースごとにコピーが増え、配布先が増えるほど整合が取れない
- これからは:中核+拡張の組み合わせで 「配っても壊れにくい知識」 を作る
Tableauユーザー・利用企業がすべきこと
まずやること:ダッシュボードの棚卸し
Composable 前提の設計に移る前に、いま社内で「どのダッシュボードが、誰に、何のために使われているか」を一度つかんでおくのが近道です。ここが曖昧だと、後で「置き換えたら現場が困る」「同じKPIが別定義で残る」が起きます。
台帳を作る(まずは最低限でOK)
以下を台帳にまとめます。
- オーナー(責任者)
- 目的(モニタリング/探索/説明)
- 主要KPI(意思決定に使う指標)
- 参照データソース(Published Data Sources/DB/抽出など)
- 更新頻度(いつ更新される前提か)
- 利用状況(誰がどれくらい見ているか、重要度)
仕分けする(やることを決めるための分類)
棚卸しの結果、各ダッシュボードを次の4つに分けます。
- 公式として残す:経営・部門の共通言語として守りたいもの
- 直す:定義・注釈・命名などを整えれば生き返るもの
- 畳む:統合・廃止できる(似たものが複数ある/役目を終えた)
- 置き換える:Composable を前提に再設計した方が早いもの
次にやること:データソースの見直し
ダッシュボードの土台が「コピーされたデータソース」だらけだと、AI/エージェント活用以前に “同じ質問に違う答えが返る” 事故が起きます。Composable Data Sources を活かすには、まずパブリッシュされたデータソースの整理が効きます。
パブリッシュされたデータソースを棚卸しして台帳化する
パブリッシュされたデータソースを、3種類に分けて台帳化します。
- 公式候補(共通KPI・共通ディメンションを持つ中核)
- 用途別コピー(似ているが少しだけ違う派生)
- 個人用(検証・一時利用のもの)
同じKPIの定義の差を見つける
売上・在庫などの重要KPIは、どこでどう定義されているかを洗い出します。
- 計算フィールド名
- 定義(フィルター条件、除外条件、粒度、期間の扱い)
- どのダッシュボードで使われているか
共通の土台を決め、運用ルールを置く
共通KPI/共通ディメンション/行レベルセキュリティを集約した「共通の土台(標準データソース)」を決めます。ここはプロダクトとして扱い、責任者と変更ルール(レビュー、周知、互換性)をセットで置きます。
「追加テーブルは直足しせず、別ソースで」を原則にする
部門・用途固有の追加テーブル/局所ロジックは、共通の土台に直足しせず「部門・用途の上乗せ(パブリッシュされたデータソース)」として分離します。relationship で合成して再利用する前提に寄せると、共通の土台の信頼性を守ったまま現場の柔軟性が出ます。
置き換え設計(「共通の土台+上乗せ」の組み合わせを決める)
置き換え対象のダッシュボードごとに、「どの共通の土台+どの上乗せ」で支えるかをマッピングします。あわせて、ダッシュボード側に残っている独自計算(本来はデータソース側に置くべきもの)を減らしていきます。
依存関係と周知の仕組みを作る
上流データソースの変更が、どのデータソース/どのダッシュボードに影響するかをつなぎます。通知先(オーナー/利用部門)と、簡単なリリースノート(変更内容・影響・回避策)を残せる状態にしておくと、運用で詰まりにくくなります。
まとめ
ブログが描く「信頼できるKnowledgeを起点に、仕事の流れの中でAIが提案し実行する未来」を実現するために、Composable Data Sourcesは Knowledge(パブリッシュされたデータソース)を複製せずに拡張・再利用し、関係性とガバナンスを保ったまま流通させるための基盤機能として連動している、という現状の整理になります。
「Tableauソリューション」
サービス紹介資料
Tableauソリューションの特徴や事例などをご紹介します。
ダウンロードはこちら