はじめに
AI開発のスピードが加速する中、多くの企業が直面しているのが「プロトタイプから本番環境への移行」の壁です。 ソフトウェア開発のスピードを上げるためにAIコード生成ツールが急速に普及していますが、 出力されたコードは多くのビジネス部門やガバナンス部門にとってレビューが難しく、ブラックボックス化してしまいがちです。
そんな課題を解決するツールとして、AIサクセスプラットフォームを提供するDataikuから2026年6月18日より「Dataiku Cobuild」が一般提供されました。 本記事では、Cobuildの概要や具体的な対応範囲、使い方、他のAIツールとの違い、触ってみた感触についてまとめます。
1. Dataiku Cobuildについて
Dataiku Cobuildは、ビジネス上の課題を自然言語で入力するだけで、コードを一切書かずにAIプロジェクトを自動生成するエンタープライズ向けのAI構築エージェントです。
最大の強みは、解読不能なコードではなく「Dataikuのビジュアルフロー」を直接生成する点です。 これにより、ビジネス部門、IT部門、ガバナンス部門の全員が同じ画面を見て、本番移行前に処理の意図を検査・編集・承認することが可能になります。
対応している基盤とモデル
Cobuildは主要なエンタープライズインフラやLLMと安全に直結した状態で動作します。具体的には以下のプラットフォームやモデルに対応しており、企業の管理下にあるセキュアな環境で利用可能です。
- Snowflake Cortex AI
- Databricks AI Gateway
- AWS Bedrock
- Google Gemini
- Microsoft Foundry
- OpenAI
- Anthropic
構築可能なレシピと成果物の範囲
Cobuildはデータ準備からML、生成AIまで非常に幅広いコンポーネントの構築に対応しています。
- コアビジュアルレシピ
Prepare, Filter/Sample, Sync, Group, Sort, Join (Fuzzy, Geo含む), Distinct, Top N, Pivot, Stack, Window
- コードレシピ
Python, SQL Query
- 機械学習 (ML)
モデルの学習 (Train), 予測 (Predict)
- 生成AI (GenAI)
データセットやドキュメントの埋め込み (Embed), 知識バンク (Knowledge Bank) の構築
- フロー以外の成果物
チャート、ダッシュボード、Jupyter Notebook、WebApp、Wikiの作成
- 自動化
上記すべてを組み合わせて自動実行するシナリオ (Scenario) の構築
- 既存の成果物に対する操作
抽出に失敗した行の特定、既存フローのリファクタリング、ジョブログの監査、エラーに対する解決策のガイダンス提示
2. Cobuildを使うには
Cobuildを実際にプロジェクトで活用するための手順と、知っておくべき仕様をまとめました。
導入方法
Cobuildの導入方法を紹介します。
Dataiku Version 14.7にバージョンアップすることで、Cobuildの利用が可能です。
Dataiku Cloudの場合、Launchpadの「Settings」メニューからセルフアップグレードを実行できます。
「Upgrade and maintenance preferences」から即時アップグレードか時間指定が選べます。
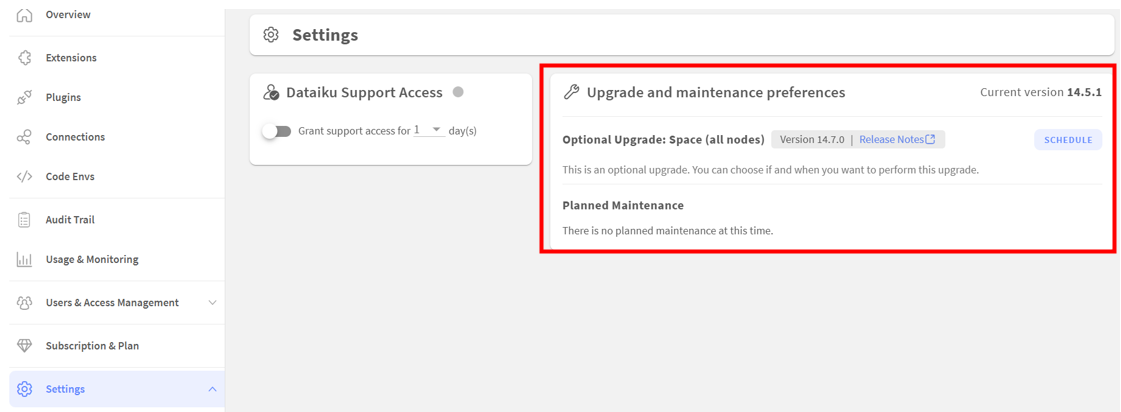
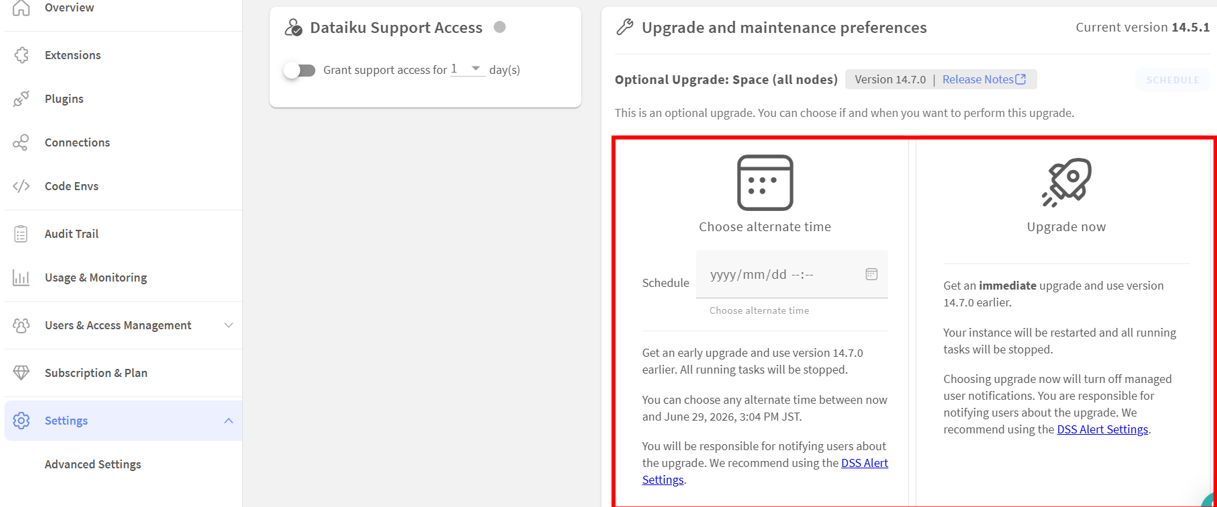
左が時間指定で右が即時アップグレードです。
事前設定
Cobuildを利用し始める前に、Dataikuの管理者によるいくつかの設定確認が必要です。
管理者がアドミニストレーション設定を開きます。

「AI Services」タブを開きます。

AI Assistant機能を「ON」にします。(過去に設定済みの場合は再設定不要です)。

同設定内の「Operation mode」で「Bring your own LLM」を選択することで、Dataikuの「Connections」で事前に設定した自社のLLM(OpenAI、Anthropic、AWS Bedrock、Snowflake Cortexなど)をCobuildのバックエンドとして安全に利用することが可能です。
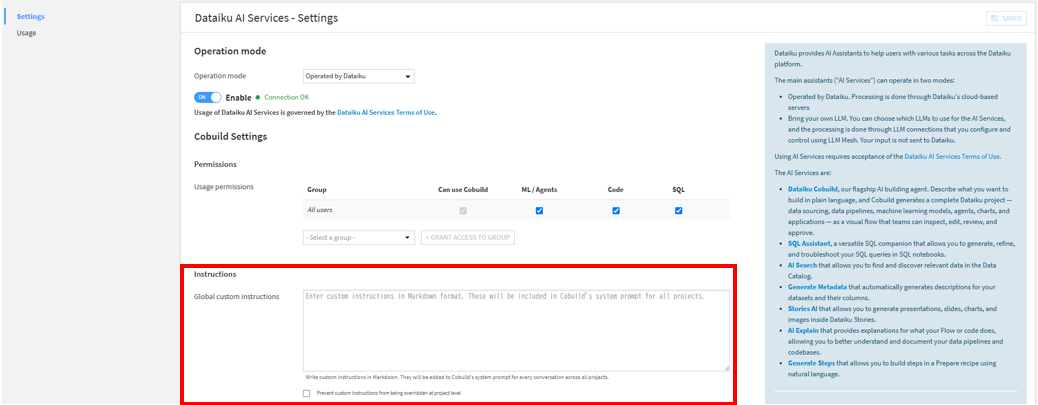
同設定内の「Global custom instructions」から全社共通の前提指示を設定したり、プロジェクト設定から「このプロジェクト独自の命名規則」などのカスタムプロンプトを定義しておくことで、生成される成果物の品質を標準化できます。
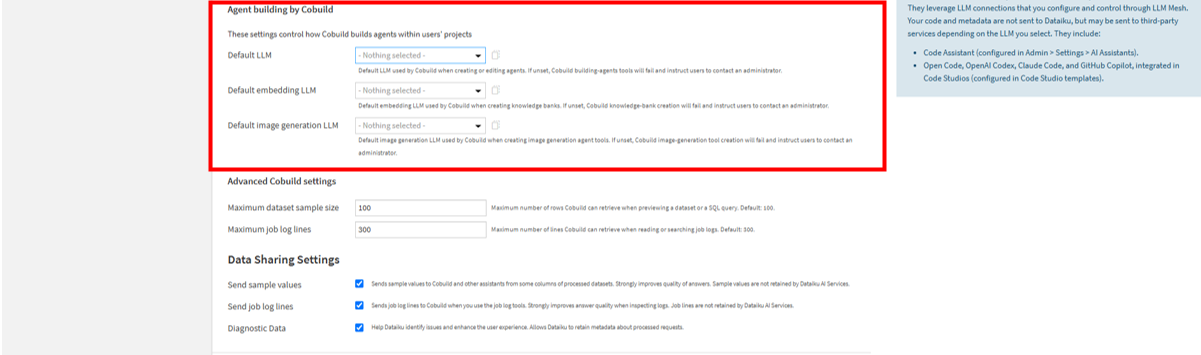
同設定内の「Agent building by Cobuild」で「Default LLM」、「Default embedding LLM]、「Default image generation LLM」からAIエージェント作成時に使う場合、埋め込みを行う場合、画像生成を行う場合それぞれのLLMを設定しておくことができます。
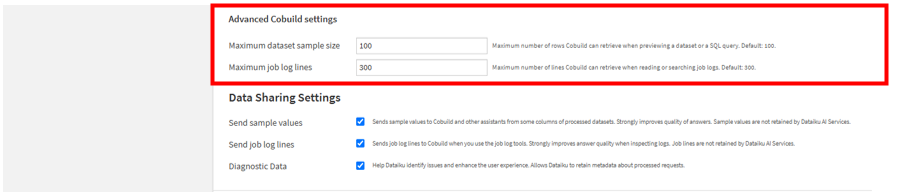
同設定内の「Maximum dataset sample size」でAIが一度に読み込んでいいデータの最大行数を指定します。また、「Maximum job log lines」でDataikuのジョブがエラーで落ちた際、AIがジョブログのファイルを下から何行まで遡って読んでいいかの最大値を決めます。

同設定内の「Send sample values」で処理対象のデータセットから、いくつかのカラムの実際のデータのサンプル値をCobuildに送信する設定を行えます。また「Send job log lines」でジョブログツールを使用する際、ジョブの実行ログをCobuildに送信する設定を行えます。「Diagnostic Data」でリクエストに関するメタデータをDataiku側が保持することを許可するかどうかの設定を行えます。これらはデフォルトでチェックが入っています。

保存を忘れずにしてください。
使用手順
準備が整えば、非常に直感的に操作できます。
Dataikuのプロジェクト画面を開き、ヘッダー右上にある「Cobuildマーク」をクリックします。
すると、画面右側にチャットウィンドウが展開されます。
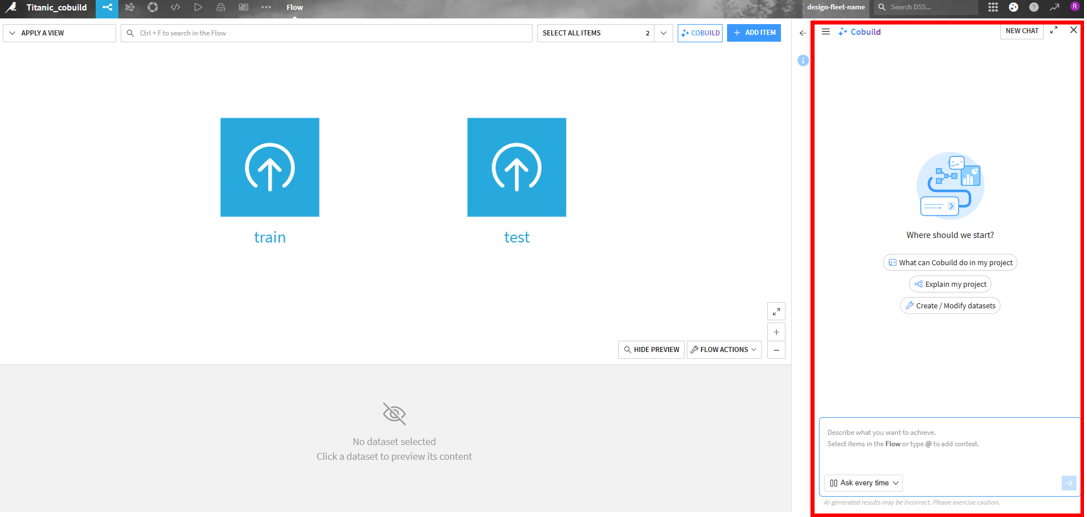
「適当なフローを作って」「機械学習を利用したものを作りたい」など、達成したいことを自然言語で入力します。以下の機能を活用すると、より正確な指示が可能です。
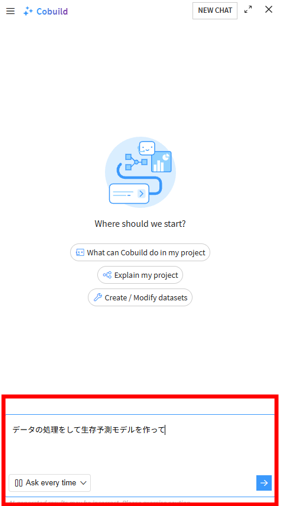
コンテキスト(文脈)の自動認識
現在開いているページや、フロー上で選択しているオブジェクトをAIが自動的に把握するため、「このデータセットを〜」といった会話的な指示が通じます。
「@」メンション
チャット内で「@」を入力すると、Dataiku内の特定のオブジェクト(データセットやレシピなど)を明示的に指定できます。
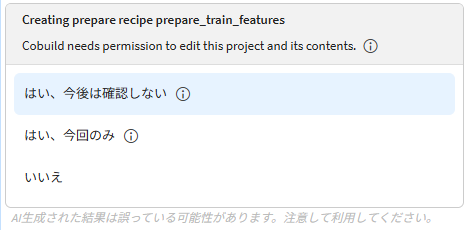
Cobuildが関連データを自ら探し出し、処理の計画(プラン)をチャット上に提示します。

特にデータの削除など重要なアクションを実行する前には明示的な確認(Approve Plan)が求められるため、 人間が意図をチェックしてから安全に構築を進めることができます。
知っておきたいTips・注意点
プロジェクト画面左上のビュー機能で「Cobuildにより作成」を選択すると、Cobuildが自動生成したオブジェクトがフロー上で緑色にハイライトされ、どこをAIが作ったのか一目で識別できます。
日本語で利用可能です。右上のプロファイル設定から、Cobuildの応答言語を「自動検出」や「日本語」に変更できます。

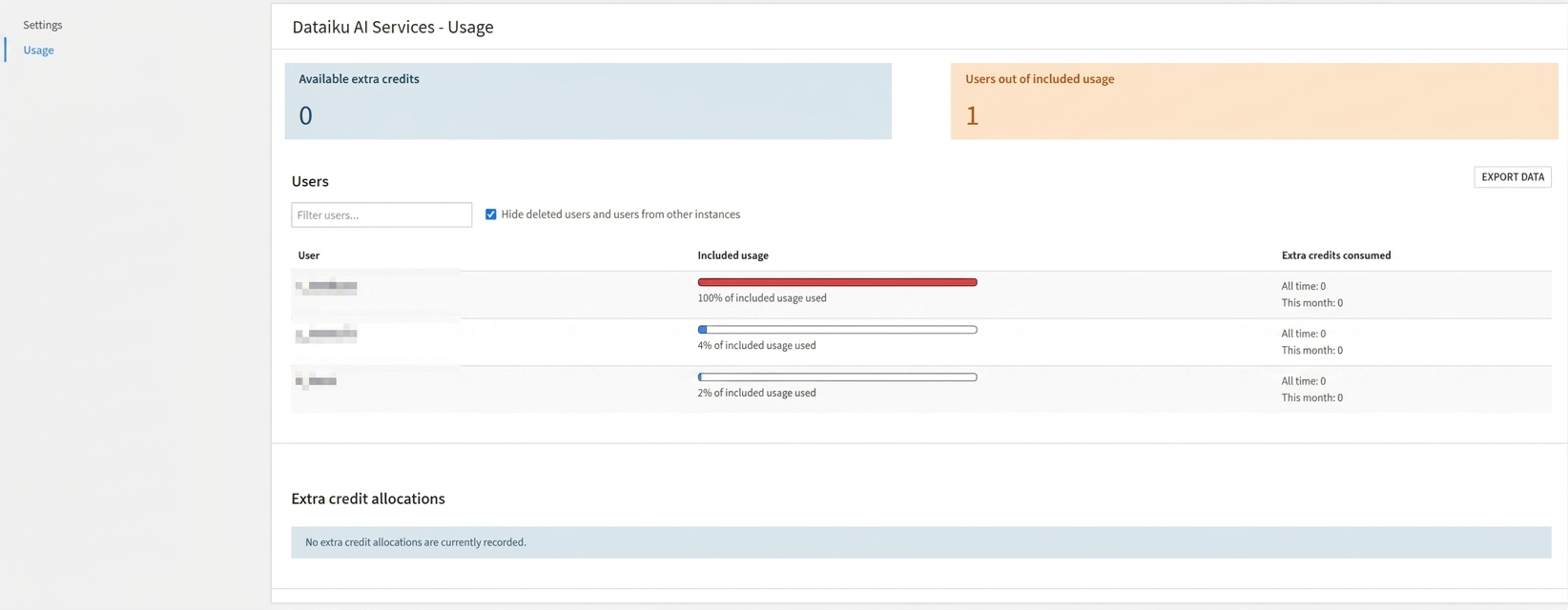
Cobuildの利用には、ユーザー単位(Designerプロファイル)で月毎に割り当てられる「クレジット」を消費します。このクレジットは、Cobuildだけではなく、すべての「AIサービス」で共通して利用され、枯渇すると新規の構築処理が停止します。
さらに利用したい場合にはクレジットの追加が必要になります。また、CobuildのデフォルトではDataikuが提供するLLMを利用していますが、管理者画面の設定にて、自社利用のLLMをフロー生成エンジンに指定することが可能で、これを利用する方法があります。
利用状況は管理者設定の 「Usage」 から確認可能です。
Ver. 14.7ではDataikuとのネットワーク接続が可能な環境でのみ利用可能です。
閉鎖環境でのご利用については今後サポート予定です。
3. 実践
データ分析でおなじみのTitanicデータを用いて簡単な検証をしてみました。
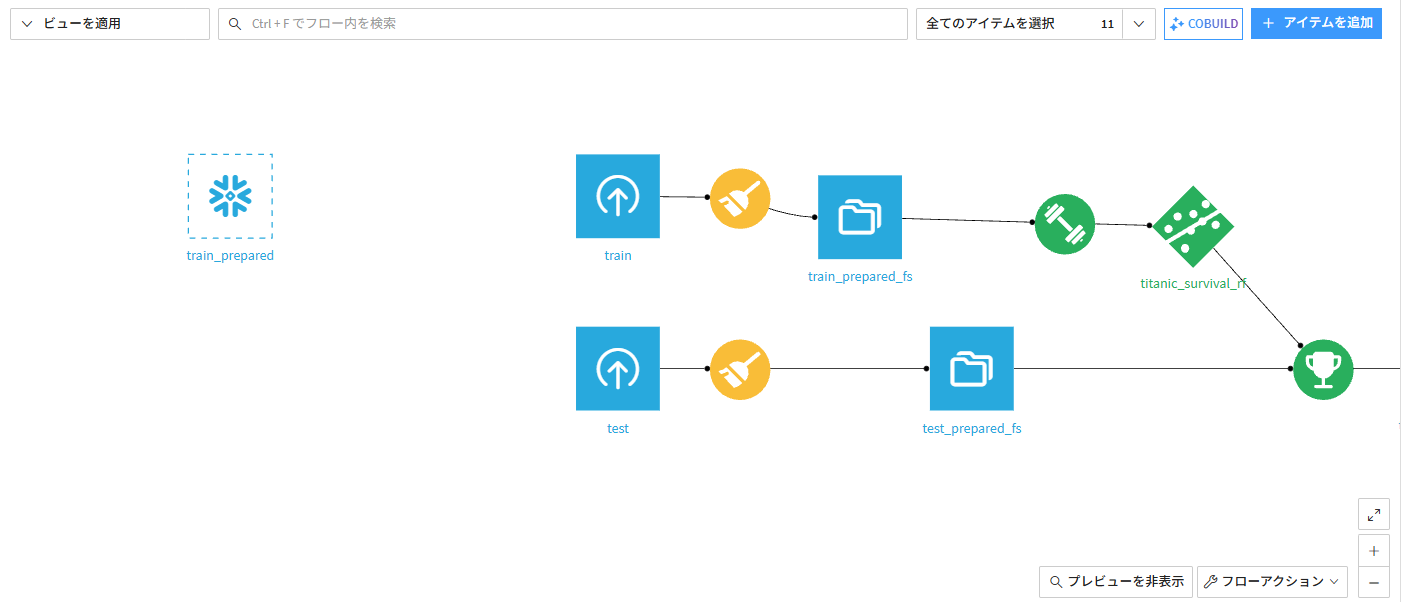
5分ほど待つと以下のようなフローが出来上がりました。
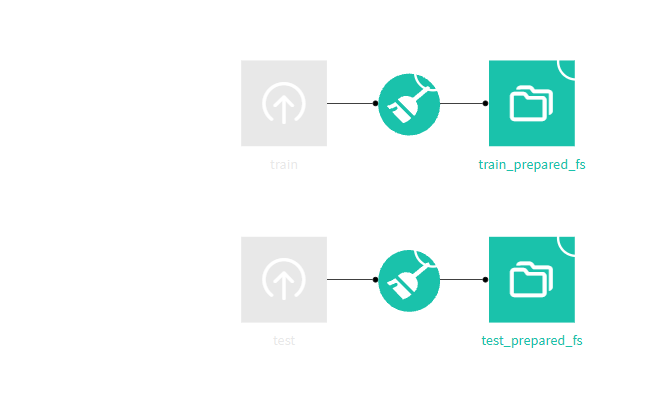
Snowflake接続が「トライアル終了でWarehouse停止」になっていたため、出力先をファイルシステム(managed)に切り替えてビルドしてくれました。
Prepareレシピによる前処理を行い、生存予測モデルを作成してくれました。
行った内容と次にやるべきことをわかりやすく提示してくれます。
行った内容をさらに詳しく知るにはアクティビティを表示させます。

1分ほどでフローが更新されました。
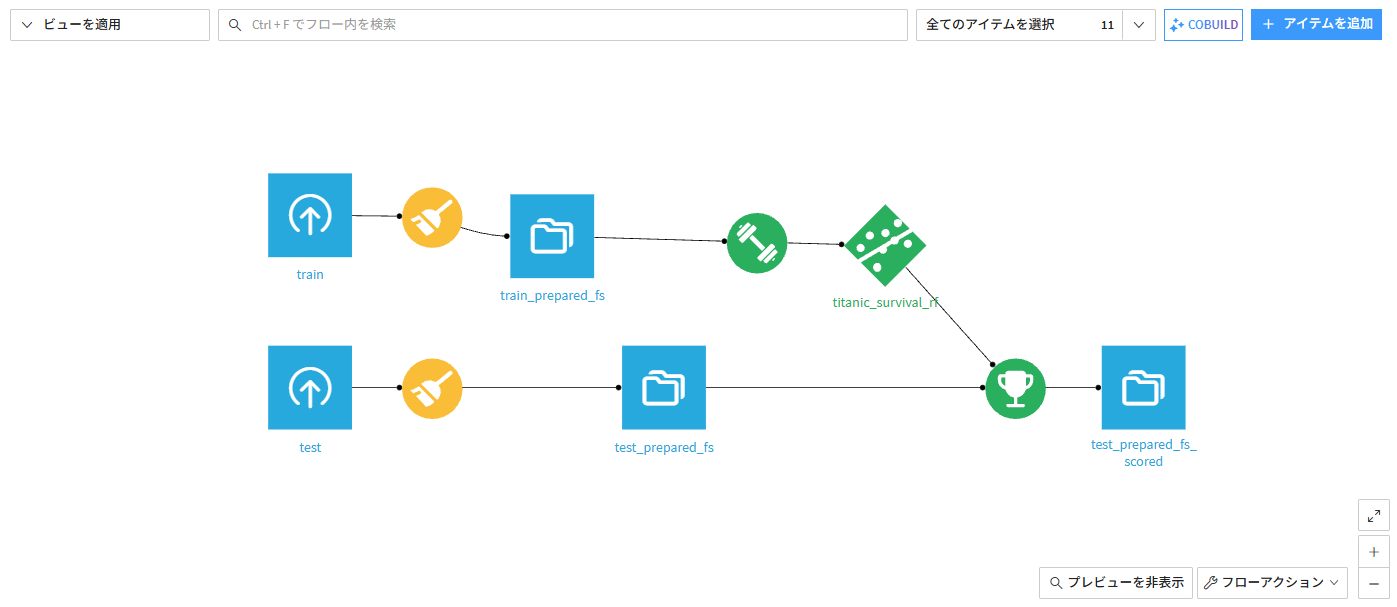
デプロイされたモデルはRandom forestが選ばれていました。
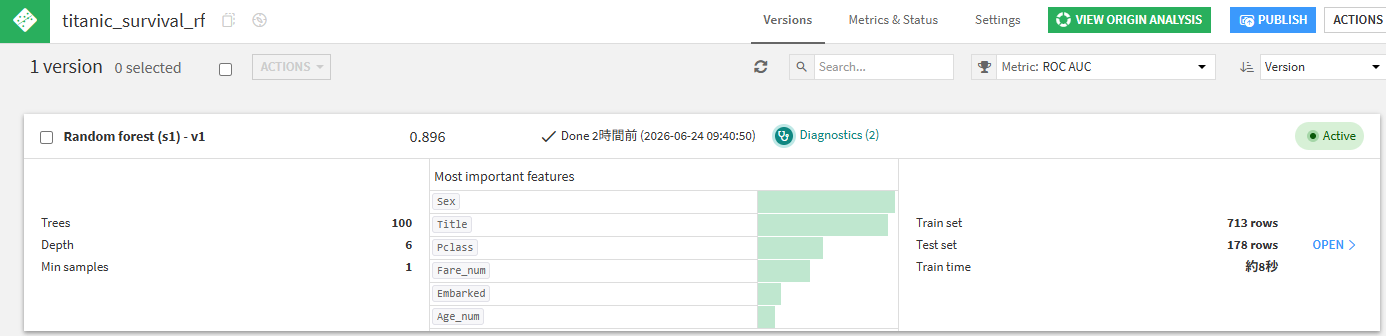
MLレシピにも対応していることが確認できました。
提出用にPassengerID, Survivedの2列に整形したデータセットをKaggleで提出します。
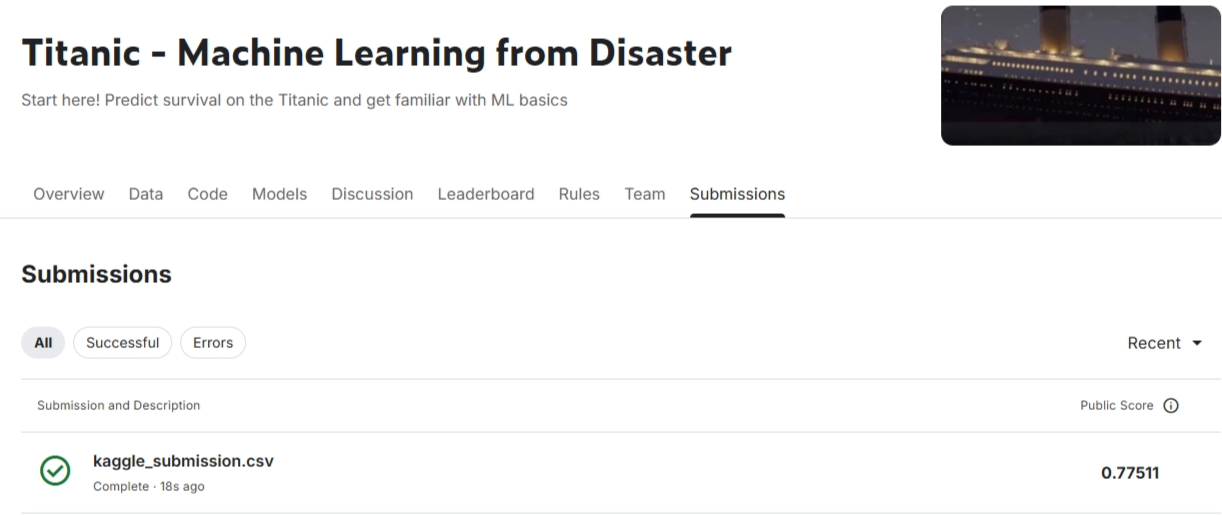
結果をみると、初回の自動構築でスコア0.77511をマークしました。Cobuildにおける自然言語の指示だけで数分である程度のクオリティの予測モデルを作ることができました。データの中身を解釈してモデルを構築していることが実証されました。
4. ほかのAIエージェントとの比較
Cobuildがなぜエンタープライズ環境において実用的なのか、他のAIツールと比較してみます。
-
vs AIコーディングエージェント(GitHub Copilotなど)
一般的なツールはコードを生成しますが、専門知識がないとレビューできず属人化を招きます。Cobuildは「ビジュアルフロー」を生成するため、ビジネス部門でも処理の意図がわかり、ガバナンス管理が容易です。
-
vs スタンドアロン型エージェント
外部で動くエージェントは、本番環境への接続が難しくプロトタイプ止まりになりがちです。Cobuildは「企業インフラの上」で動き、既存のエンタープライズデータ基盤やLLMと安全に直結した状態でプロジェクトを生成するため、作った瞬間から本番環境に耐えうる(Production-readyな)クオリティを持ちます。
-
vs 一般的なAutoML
多くのAutoMLツールはモデルを構築して終わりですが、Cobuildは「既存のデータパイプラインのリファクタリング(綺麗に修正)」や「ジョブログを監査してエラー原因を提示する」など、運用・保守フェーズの相棒としても機能します。
5. まとめ
Dataiku Cobuildは、自然言語の指示からデータパイプライン、機械学習、Webアプリまでを一気通貫で構築し、プロトタイプ作成の速度を劇的に向上させる革新的なツールです。対応しているレシピやモデルの幅も広く、コンテキストを理解した直感的な操作が可能です。
ただ作業を自動化するだけでなく、ブラックボックス化を防ぎ、運用・保守までをガバナンスの効いた状態でサポートしてくれます。
