さぁ、我が社もAI推進だ!
…と言ってしまえば簡単ですが、AIを組織の戦力にするのは、個人的な旅行の計画をChatGPTに考えてもらうのとは訳が違います。
いざAI活用を全社展開しようとすると多くのプロジェクトが壁にぶつかりがちですよね。
- 部署ごとのデータがバラバラ
- 機密情報のAI利用ルールが未整備
- 業務で使えるほど精度が安定しない
そこでカギになるのが、AI-readyという考え方。ひとことで言えば、「自社のデータと管理体制が、AIを安全かつ正確に動かせる状態に整っているか」 ということです。
実際、調査会社のGartnerは「2026年までに、AI-readyなデータに支えられていないAIプロジェクトの60%が放棄される」と予測している(Gartner, 2025)くらい、重要な概念といえます。
この記事では、AI活用の旗振りを任された推進担当の方・任せる側の経営層の方に向けて、AI-readyという概念を解説します!
こんな方にオススメ
- 個人利用は広がったが、組織での活用をどう進めればいいか分からない事業部門・経営層の方
- AI活用の旗振りを任されたものの、AI-readyの必要性の認識に少し不安がある企画・データ担当・AI推進担当の方
AI-readyが実現すると、組織はどう変わるか

「AI-ready化」というと、データエンジニアやIT部門の話のように聞こえるかもしれません。しかし、その先にある景色は経営・現場すべての人に恩恵をもたらしてくれます。
現場の担当者が、自然言語で分析できるようになる
「先月の受注傾向を教えて」とチャットに入力するだけで、根拠つきの分析が数秒で返ってくる。ExcelやBIツールを何枚も開いて集計する作業が消え、担当者はその時間を「なぜそうなったか」の考察に使えます。
「あの件は田中さんしか知らない」がなくなる
ベテランの判断基準・過去の対応履歴・暗黙のルールがデータとして蓄積され、退職や異動があっても組織の知恵が引き継がれます。新人が即戦力になるスピードも変わることでしょう。
経営判断のサイクルが速くなる
月次報告を待たずに、リアルタイムのデータをもとにAIが「このままだと今月の目標達成は難しい」と予測してくれる。打ち手の検討を早く始められるため、変化への対応速度が上がります。
これがAI-readyな組織の姿です。その分かれ目が、次に説明するデータの整備状態にあります。
何をすべきか
「データをきれいにしたのに、AIの精度が上がらない」。嘘みたいな本当の話です。
実は、クレンジング(データ成形)だけではAI活用には不十分なのです。ここで、データの整備度を3段階に分けて考えてみましょう。
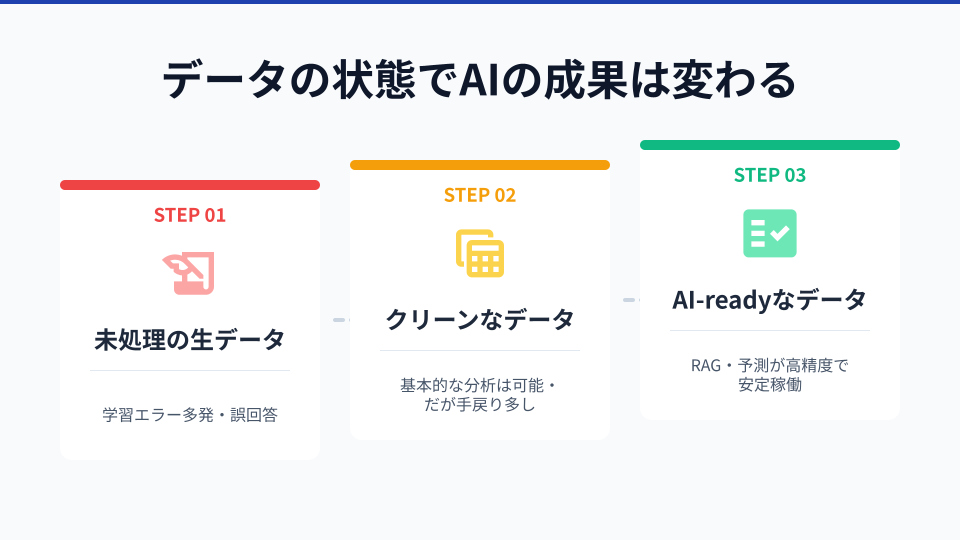
Step1: 生データのまま フォーマットがバラバラで重複・欠損も多い状態。AIに読ませると的外れな回答(ハルシネーション)が頻発し、実務になりません。
Step2: クレンジング済みデータ 入力ミスや重複は除去済み。単純な集計・検索は動きますが、「この売上は税込?税抜?」「どの客層を想定した数字?」といった「意味」を問うと、AIは答えられません。判断・提案系のタスクでは依然として不正確なままです。
Step3: AI-readyなデータ クレンジングに加え、データの意味づけ・ガバナンス・自動連携まで整った状態。AIは自信を持って回答でき、業務の判断まで任せられるようになります。
AI-readyとは、クレンジングの先にある「意味・ルール・連携」まで整えること。それを実現する4つの要素が、下の図です。
料理に例えるなら、「最新の調理器具(=AI)をそろえる前に、食材(=データ)が新鮮で、レシピ(=社内ルール)が整っているか」 を確かめる話だと考えると分かりやすいかもしれません。

データを記録・収集してからAIに読み込ませるまでの流れを、次の4つの要素で整理してみましょう。

1. データを1か所に集めて、きれいにする(データ統合・整備)
基幹システム・各種ソフトウェア・PDFなど部署ごとに様々な媒体に散らばるデータを1か所に集め(集約先をデータレイク/DWHと呼びます)、欠損値の除去や名寄せを行って”きれいなデータ”にする段階です。
2. データの「意味」をそろえる(ビジネスルールの定義)
「売上が税込か税抜か」など部署ごとの定義のズレをなくす段階です。曖昧なままだとAIは計算を間違えるため、データの意味と計算ルールをメタデータとして共通化します。
3. データとAIを自動でつなぐ(連携・自動化)
AIの予測・分析結果をSalesforceなどの業務システムへ自動連携する仕組みです。手作業のコピペをなくし、現場で”使われるAI”にします。
4. ガバナンス・セキュリティ
機密・個人情報をAIに渡さないためのルール整備です。アクセス権限の設定・学習禁止データの隔離・データ来歴の管理、の3点が柱でコンプライアンス上も必須です。
じゃ、我が社は何をすればいいんだ?
いきなり完璧を目指す必要はありません。目標は「AIが正確に動けるデータ基盤を段階的に整えること」。さきほどの4つの要素を、次のステップとして踏んでいきます。
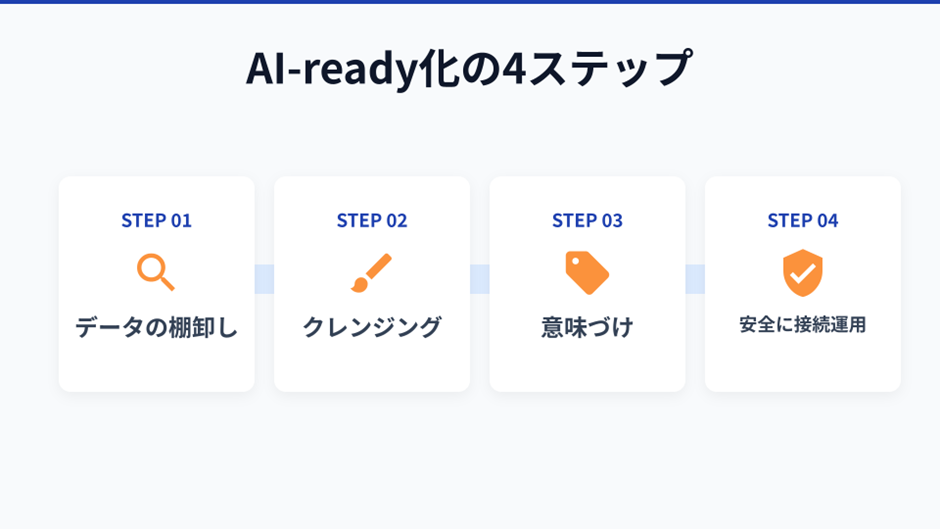
Step1: 今あるデータを棚卸しする
まず「社内にどんなデータが、どこに、誰の管理であるか」を一覧化するデータカタログを整備します。どこに何があるかが見えていないと、後のすべての工程で必ず手戻りが発生します。データ基盤整備の起点です。
Step2: データをきれいに整える
表記のゆれ(例:「株式会社○○」と「(株)○○」)の統一、異常な数値の検知、日時の基準合わせなどを行い、AIが扱える形に整えます。
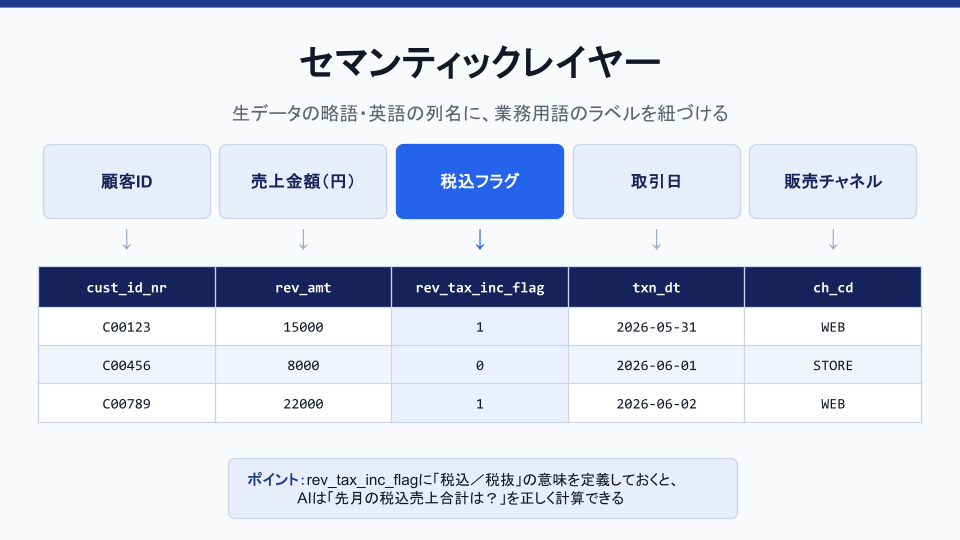
Step3: データの意味づけをする
整えたデータに「これは何を表す数字か」という意味を付与し、業務用語とデータを橋渡しする層を作ります。これをセマンティックレイヤーと呼びます(下図)。ここが整うと、AIが「売上」「顧客数」といった業務用語を正しく解釈して答えられるようになります。
Step4: 安全につなぎ、運用しながら改善する
データの活用と保護のルール・体制を整えるガバナンスの段階です。アクセス権限の管理・学習禁止データの隔離・データがどこからどう流れているかの管理を仕組み化し、コンプライアンス上のリスクを排除します。稼働後もデータの傾向変化を監視し、精度を改善し続ける運用体制までをセットに整えます。
できることから
AI-readyな組織づくりは、推進者だけで完成するものではありません。現場一人ひとりのデータへの向き合い方が積み重なって初めて実現します。「自分は現場の一利用者だ」という方にも、すぐ動けることがあります。ここまでお読みいただいた方に、早速できることをご案内いたしましょう!
- 自分が扱うデータの命名・定義をそろえる:「売上」「顧客名」など、自分が入力・管理する項目の書き方を一貫させるだけで、組織のAI精度に貢献できます。
- 「なぜこのデータが必要か」を一言メモする:数字や情報の”意味”を残しておくことが、AIが正しく読み解くためのメタデータになります。
- 推進担当に「うちの部署はこんなデータを持っている」と知らせる:データカタログの整備は、現場の声があって初めて前に進みます。
小さな一歩に見えますが、これが積み重なると組織のAI-ready度は確実に上がります。
Ready for AI-ready?
「自社はどの段階にいるのか」「何から手をつければいいか」――そんな方に、キーウォーカーはデータ基盤からAI活用まで、一気通貫でサポートしています。
- データカタログの整備 「自社のデータ資産の全容が見えていない」ところから、現状把握と優先順位づけを支援します。
- データ基盤・DWHの構築 散らばるデータを集約・整備し、AIが正確に動けるデータ基盤を設計・構築します。
- セマンティックレイヤー・BIの整備 業務用語の定義統一から、経営・現場が自然言語で分析できるデータ活用環境を構築します。
- AI/RAGアプリの開発 Dataiku・Difyを活用し、社内データを安全に活用するAIアプリをセキュアに開発・導入します。
- ガバナンス設計 機密情報の保護ルール・アクセス権限設計・コンプライアンス対応を含むガバナンス体制の整備を支援します。
「まず自社の現状を診断したい」「導入したツールが活かしきれない理由を知りたい」といったご相談レベルから、お気軽にお声がけください。











