1. はじめに
社内に蓄積されたデータを有効活用しようとする際、大きく分けて2つの課題があります。
一つ目は、「数値データ分析におけるスキル」の課題です。売上の集計表などの構造化データを深く分析するにはSQL等の専門知識が必要となることが多く、現場の担当者が自ら、タイムリーにインサイトを得るにはハードルがありました。
二つ目は、「テキストデータの取り扱い」の難しさです。商談メモや日報といった非構造化データには、数値だけでは見えない顧客の反応や失注の予兆が含まれています。しかし、これらは「人が読み解く」必要があるため、膨大な量を効率的に集計・分析することが困難でした。
Snowflake Cortex AIは、これらの課題を解消するツールです。
最大の特徴は、データに対して自然言語で問い合わせが可能になる点です。専門的なコードを書くことなく、日常的な言葉で問いかけるだけで、AIが数値とテキストの両面から必要な情報を抽出します。
今回は、実際に弊社が保持する営業データを用いて、Snowflake Cortex AIでデータを分析し意思決定に繋げる仕組みを構築します。
2. Snowflake Cortex AIとは
Snowflake Cortex AIとは、Snowflakeのプラットフォーム内でNLP(自然言語処理)やML(機械学習)などのAIを活用するための機能群です。さまざまな機能が備わっておりますが、その中でも今回は以下の4つを用いて構築します。
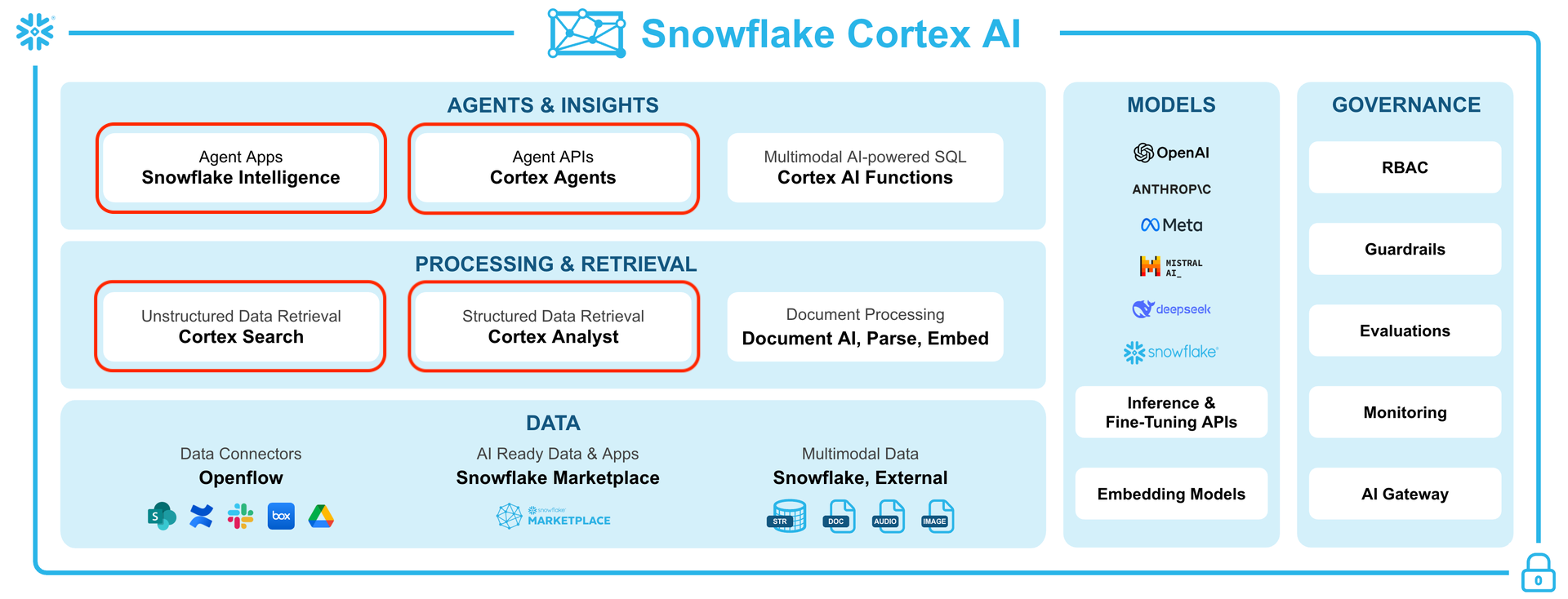
Cortex AI機能群[1]
2-1. Cortex Analyst
Cortex Analystとは、構造化データに対して自然言語(日常的な言葉)で質問を投げると、AIが意図を汲み取り、SQLに変換してデータを分析することで回答を生成する機能です。
例えば、毎月の売上を集計したデータに対して「2025年12月の部署別の売上は?」とプロンプトを投げることで、AIが自動的に売上を集計し回答を生成します。これにより、ユーザーにSQLのスキルがなくても見たいデータの抽出・集計が可能になります。
2-2. Cortex Search
Cortex Searchとは、ドキュメントなどの非構造化データに対して、検索キーワードの意味を捉えて情報を検索する機能です。最大の特徴は、キーワードによる検索と文脈や意味による検索(ベクトル検索)のハイブリッドでデータを検索することです。
例えば、営業提案の商談メモに対して「受注確度が高い営業提案の一覧を教えて」とプロンプトを投げることで、文章中に文字通りの「受注」というキーワードが無くても文脈から該当する営業提案を検索します。
2-3. Cortex Agents
Cortex Agentsとは、ユーザーからの質問に対してAIが課題の分解、ツールの選択、回答までの一連の流れを自律的に行うAIエージェントです。
例えば、「2025年12月の売上が低い部署の原因を分析して」とプロンプトを投げた際に、Cortex Analystで売上額を集計した後にCortex Searchで商談メモから失注理由を分析する、といった様に、AIが課題を分解して場面に応じて最適なツールを自動的に使い分けます。また、分析結果がプロンプトの意図を汲み取れているかをAIが自分で評価し、次のステップ(結果を出力する、分析を深掘りする、ユーザー側に確認の問いを投げる、etc.)を決めます。
このように、解決したい課題(ゴール)を与えれば、解決までのプロセス(ツールの使い分け、結果の自己判断、修正、etc.)を自ら進められることが、Cortex Agentsの特徴です。
2-4. Snowflake Intelligence
Snowflake Intelligenceとは、上記3つの機能を一つに統合したUIです。ユーザーはChatGPTやGeminiなどと同じように、質問を投げれば以降はAIエージェントが自動的に回答を生成します。
3. 実装方法
3-1. Cortex Analyst
前提
セマンティックビュー
Cortex Analystを実装する上で、「セマンティックビュー」は非常に重要な要素です。セマンティックビューとは、データベース上の物理的なデータに対してビジネス上の意味を定義するオブジェクトで、各テーブルのカラムの意味やテーブル間の関係、ビジネス指標の計算式などを定義します。
セマンティックビューはAIの回答の精度を高める上で必須です。例えば、「金額」という名前の列を持つデータに「毎月の売上を集計して」とプロンプトを投げても、AIからすれば「売上」という列はないため何を参照すれば良いかが分かりません。勿論、ある程度推測もできますが、列数が多かったり似た名前の列が複数存在すると解釈にブレが生じます。
この時にセマンティックビュー内で列名の同義語を定義することで、データとプロンプトで異なる言い回しでも共通認識を得ることができます。
データ整備の必要性
Cortex Analystは自然言語による質問文をSQLに変換し、それをデータに投げることで分析や集計を行う機能です。
ここで、SQLとはリレーショナルデータベース(データが行と列の表形式で保存された形式)を操作するための言語です。つまり、分析対象のデータが綺麗な表形式に整えられていない状態で実装しても、有効な回答は得られません。また、データの表記揺れや欠損など細かい不備も回答の精度に悪影響を及ぼします。
よって、Cortex Analystの力を最大限に発揮するには、大元となるデータを整備する必要があります。
実装手順
分析対象のデータをSnowflake上の任意のデータベース・スキーマに格納します。今回は、HubSpotに記録している取引データと、3種類の予算データ(月別、サービス別、営業担当者別)および従業員マスタを対象とします。(個人名や企業名などの個人情報はマスク化しています)
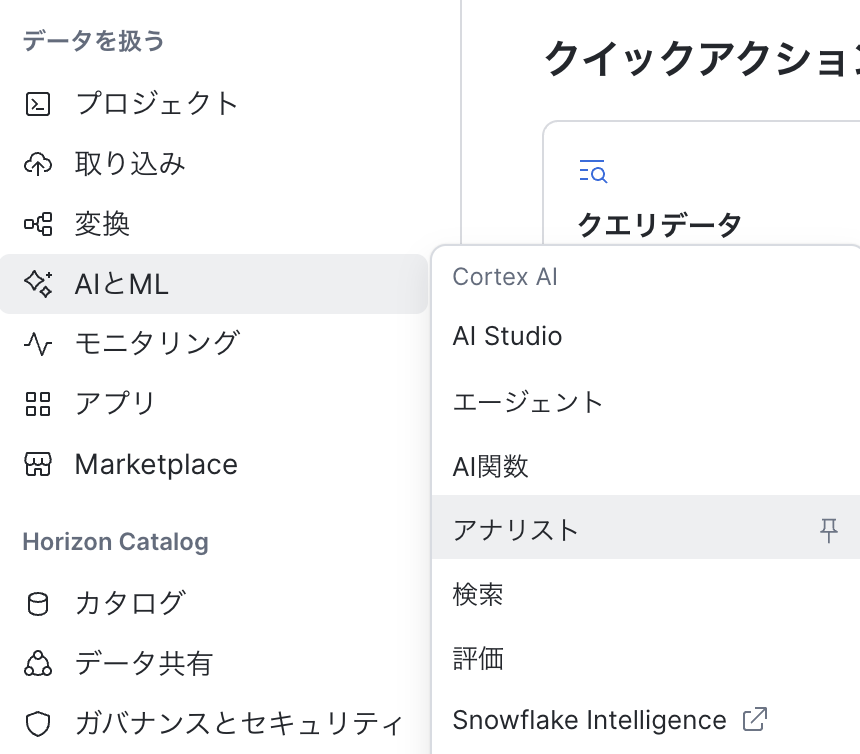
画面左端の「AIとML」→「アナリスト」を選択し、遷移先の右上の「自動パイロットで作成」を選択します。
セマンティックビューの名前や保管場所、セマンティックビューを定義する(分析対象の)テーブルや列を選択します。
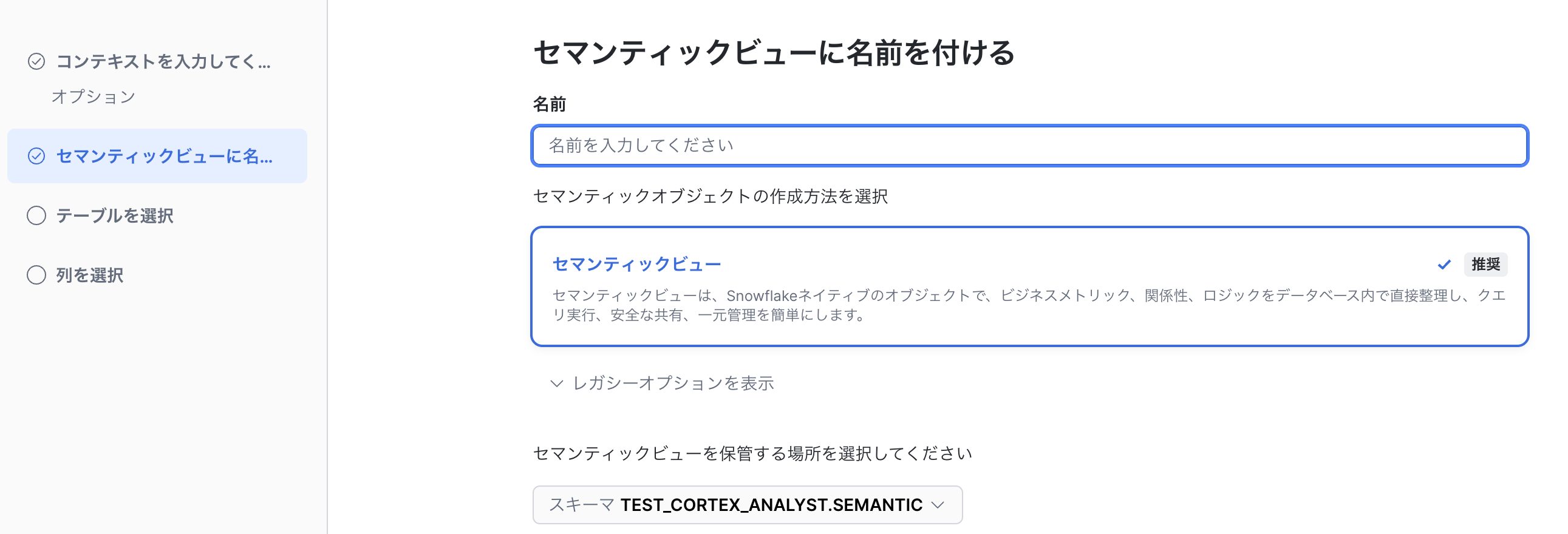
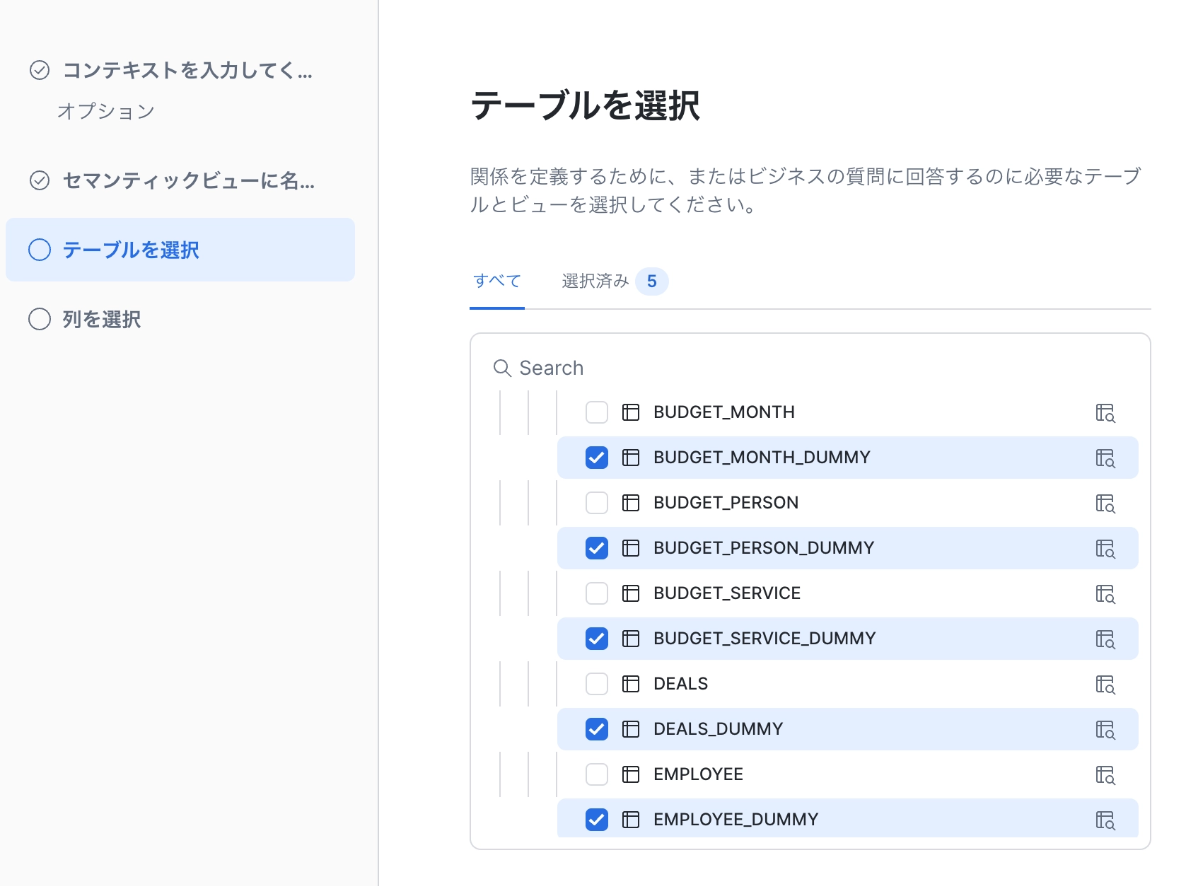
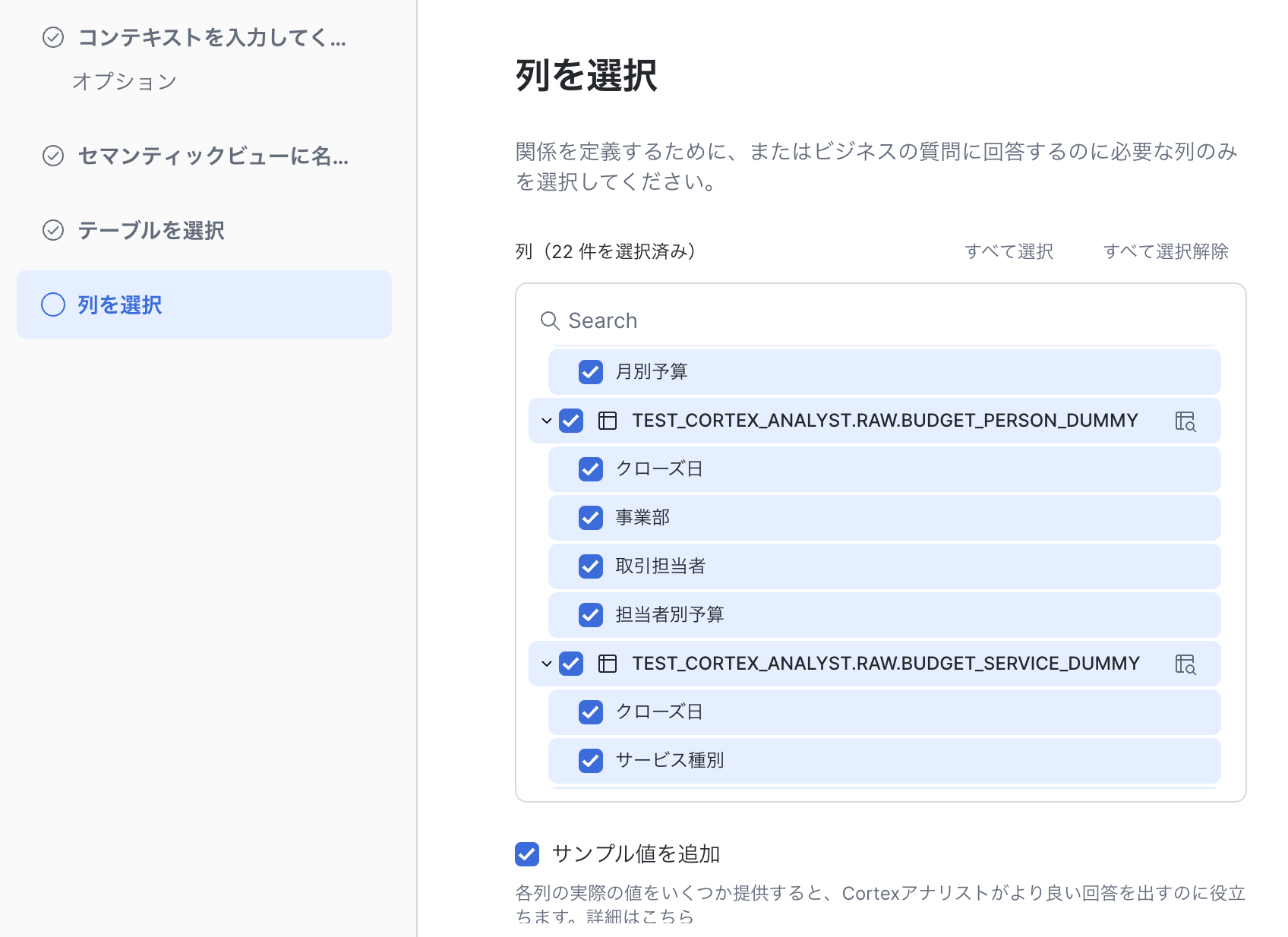
選択後、セマンティックビューの大枠はAIで自動的に作られますが、さらに精度を上げるための細かい部分も手動で設定できます。具体的には以下の5つの要素があります。
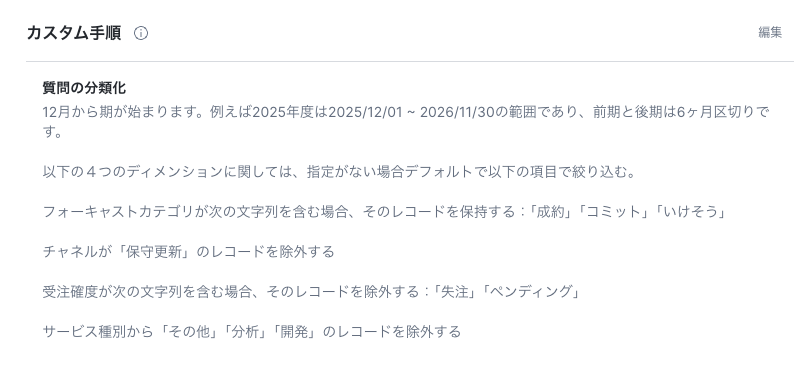
カスタム手順
年度の変わり目や定型的な絞り込み条件など、分析の前提となるビジネスルールを定義します。
論理テーブル
テーブルの各カラムに対して式や説明、同義語、ディメンションとファクトの分類など細かな設定をします。
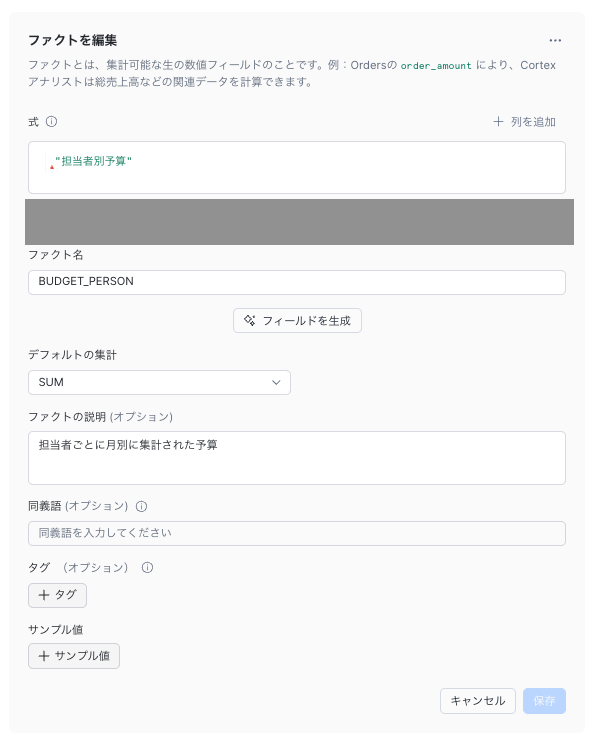
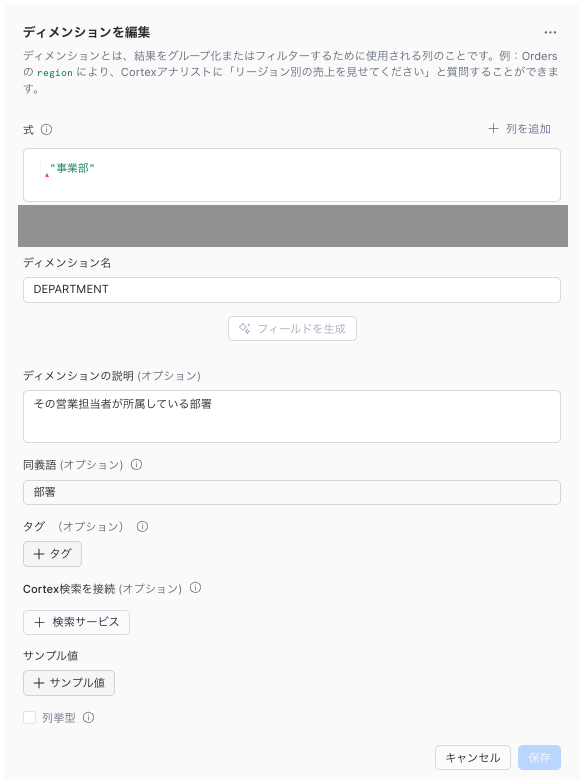
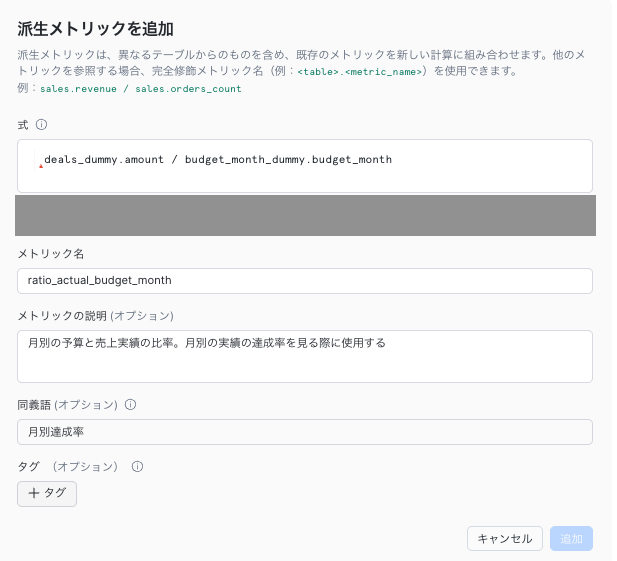
派生メトリック
異なるテーブルを跨いで指標を集計したり計算をする場合のロジックを定義します。今回は売上実績と予算が異なるテーブルに保持されておりそれらを組み合わせて予算達成率を見るため、そのロジックを定義します。
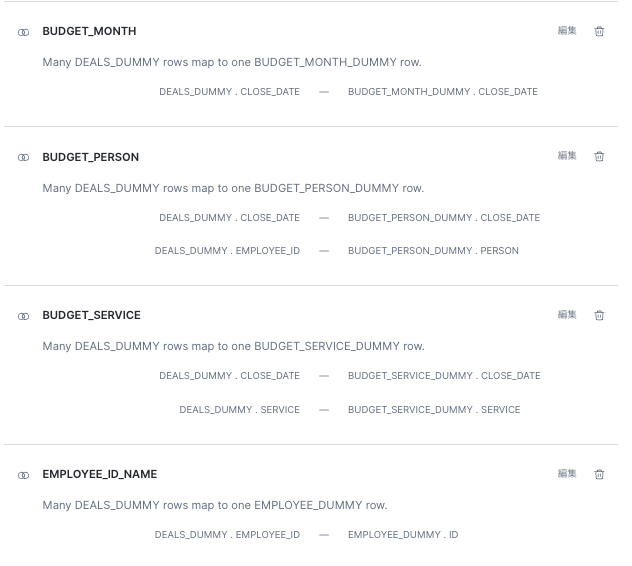
リレーションシップ
複数のテーブルを組み合わせる際の結合キーを指定します。
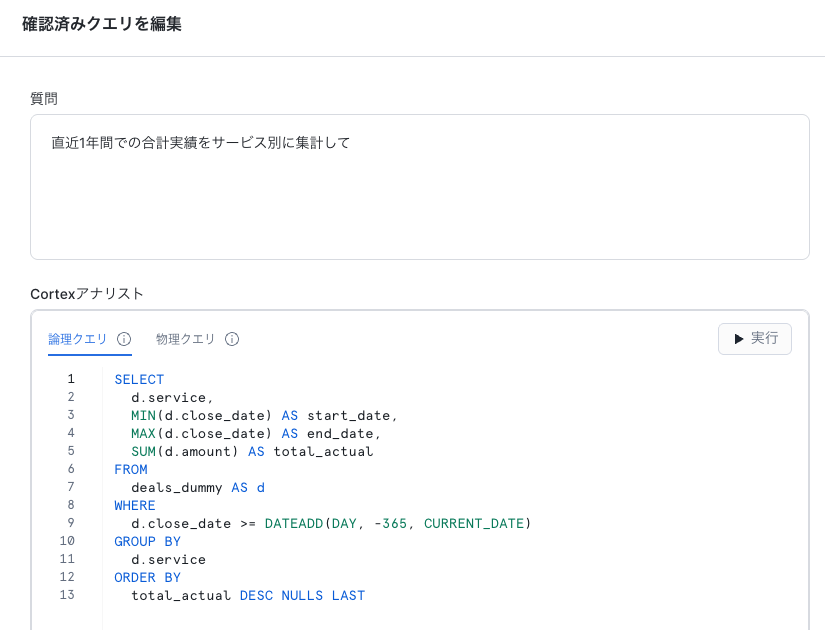
確認済みクエリ
自然言語での質問文と、それに対応するSQLのクエリの模範例を定義します。ユーザーが同様の質問をした場合にここで定義したクエリを参照することで、自然言語からSQLへの変換精度を高めることができます。
各種設定が完了したらセマンティックビューを保存します。これでCortex Analystの実装は完了です。
3-2. Cortex Search
前提
テキストの抽出と加工
Cortex SearchはPDFやドキュメントなどの非構造化データを検索する機能ですが、文字通りPDFをSnowflakeに取り込んでそのまま分析に掛けられるわけではありません。実装手順でも実物をお見せしますが、ドキュメントからテキストを抽出した上でタグをつけて半構造化データの形で保持する必要があります。
実装手順
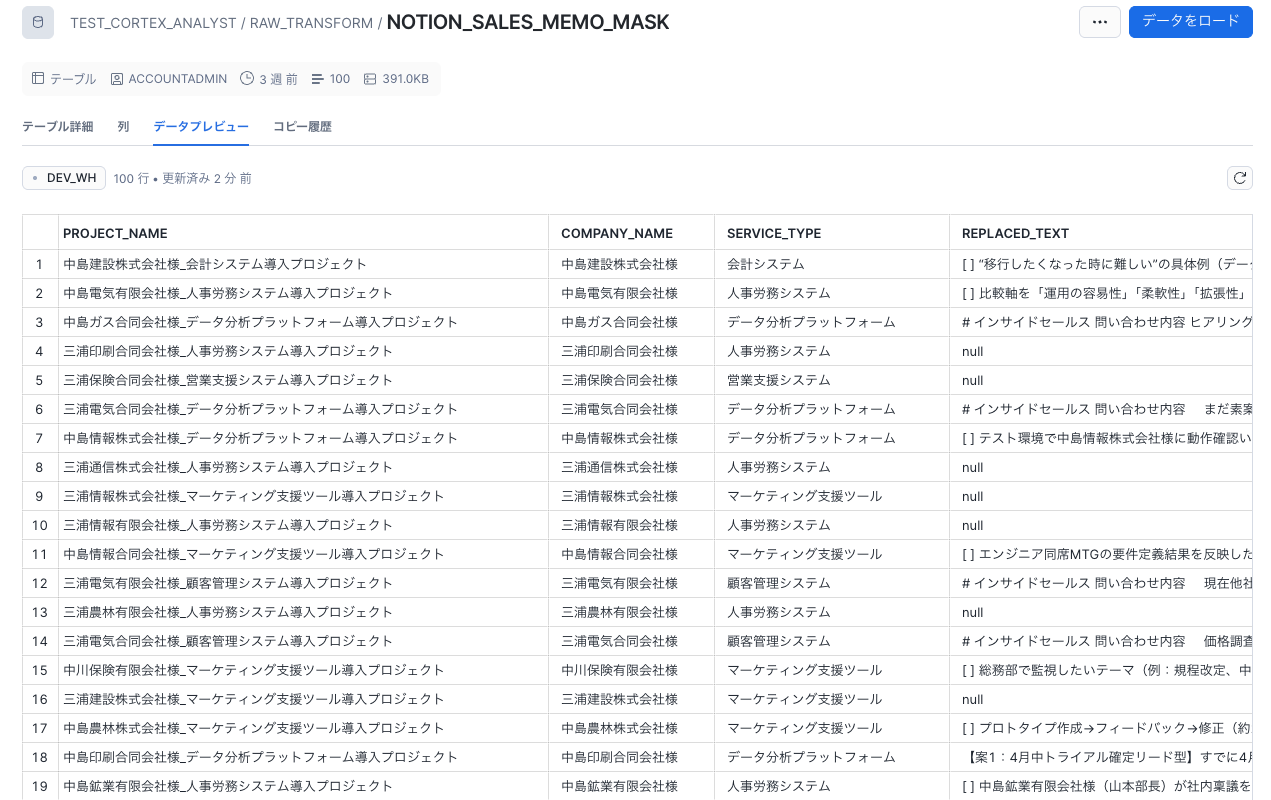
分析対象のデータをSnowflake上の任意のデータベース・スキーマに格納します。今回はNotionに蓄積している営業提案メモや商談の議事録を対象とします(個人名や企業名などの個人情報はマスク化しています)。NotionとSnowflakeを連携してテキストを格納した後に、以下のように会社名や商談名などのタグをつけて半構造化データに加工します。このデータの1レコードが1つの商談に対応しており、4列目(REPLACED_TEXT)の各行に対応する商談に関する全てのドキュメントをまとめております。
左端の「AIとML」→「検索」を選択し、遷移先の右上の「作成」を選択します。
検索サービスの名前や保管場所、分析対象のテーブルを設定します。
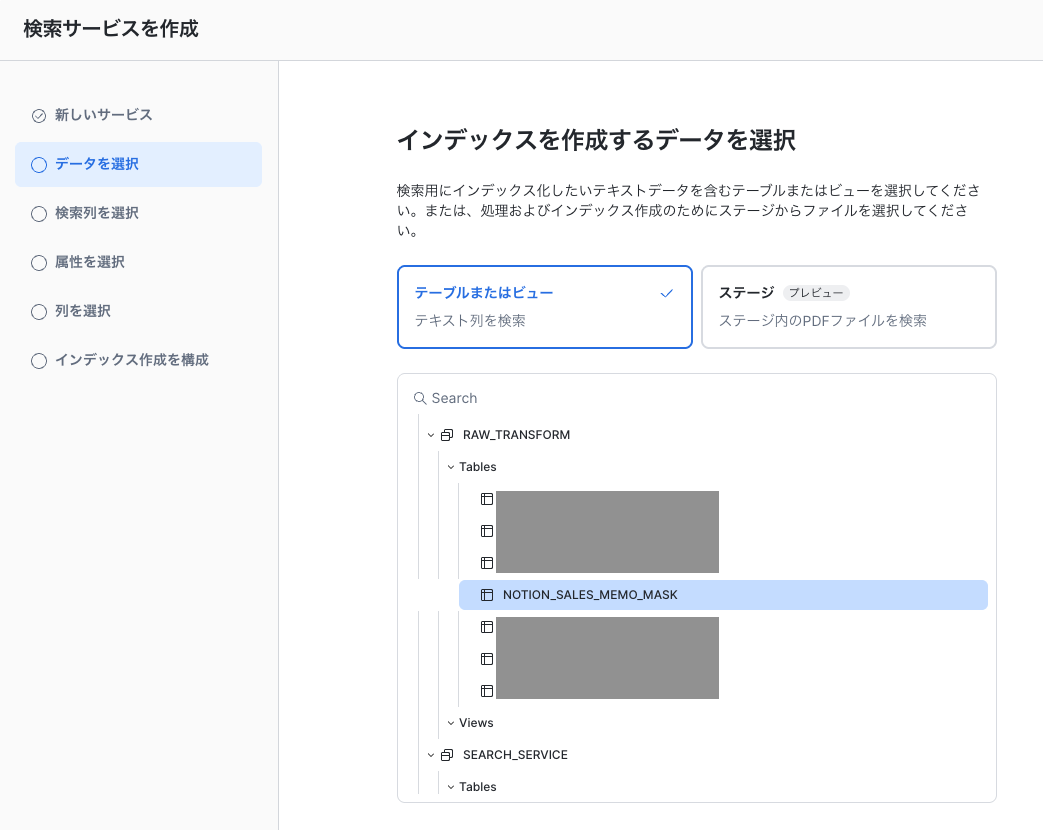
分析対象のデータから、「検索列」「属性列」「サービスに含む列」の3つを選択します。それぞれの役割は以下のとおりです。
- 検索列:テキスト検索の対象となるメインの列。ここで指定した列の内容に対して検索をかける。
- 属性列:フィルタリングに用いる列。「〇〇会社への営業提案のみ」といった、条件付きの検索をする際にこの列で絞り込む。
- サービスに含む列:検索やフィルターには用いられないが、検索結果の付随情報としてUI上に表示される列。



その他検索サービスの詳細を設定します。
これでCortex Searchの実装は完了です。
3-3. Cortex Agents
実装手順
左端の「AIとML」→「検索」を選択し、遷移先の右上の「エージェントを作成」を選択します。
エージェントの名前と保管先を設定します。
画面上部の「ツール」から、先ほど作成したCortex AnalystとCortex Searchを追加します。

これだけでも最低限の準備は完了ですが、Cortex AnalystとCortex Searchを両方追加した場合はオーケストレーション手順(タスクによってツールを使い分けるルール)を設定することで、より精度の高い回答が可能になります。
応答手順はエージェントが最終回答を生成する際のフォーマット(回答のトーン、口調、スタイルなど)を設定するもので、基本的に回答の精度には影響を与えませんが、以下のように間接的に影響を与えるケースもあります。
- 「不明な場合は”分かりません”と答えよ」→誤回答を防止
- 「SQLの結果をそのまま提示せよ」→AI側が自己判断で要約することでの情報の欠落を防止
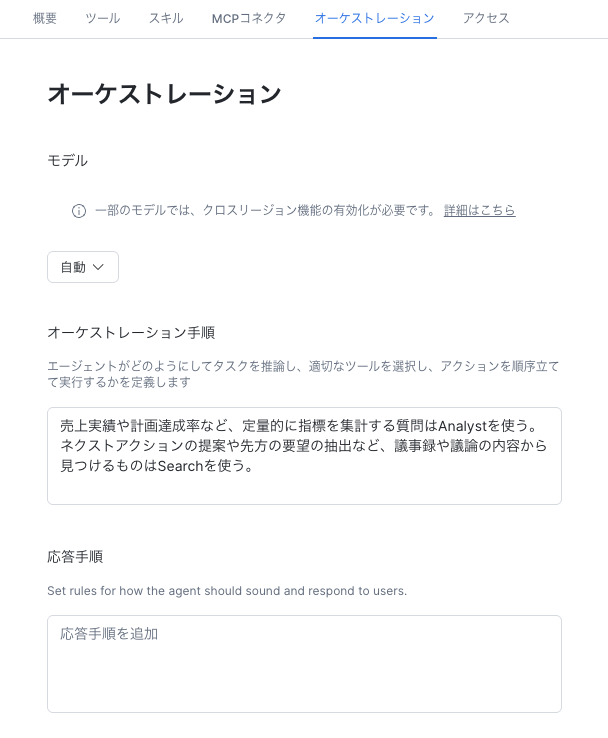
これでCortex Agentsの実装は完了です。
3-4. Snowflake Intelligence
実装手順
左端の「AIとML」→「Snowflake Intelligence」を選択します。
左端の「エージェント」から、先ほど作成したAgentsを選択します。
これで全ての準備が完了です。
4. 実演
いくつか質問を投げて、エージェントがどのように回答するかを確認してみます
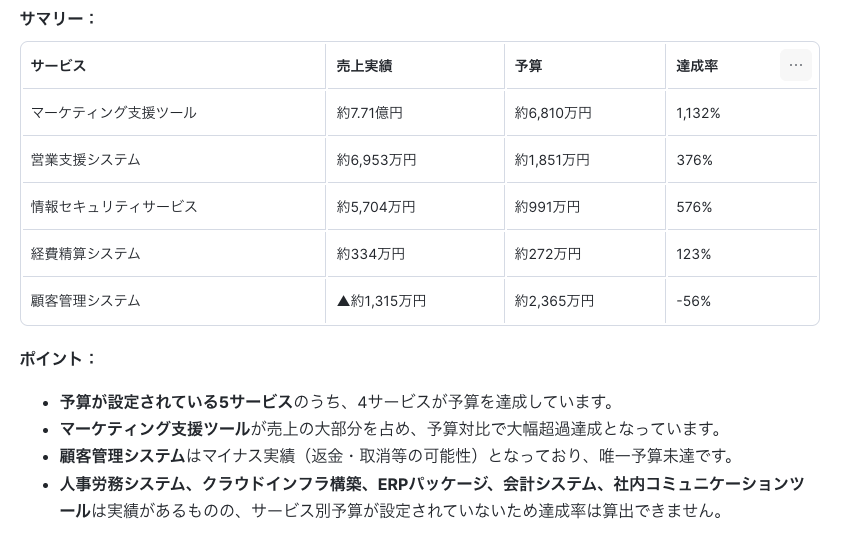
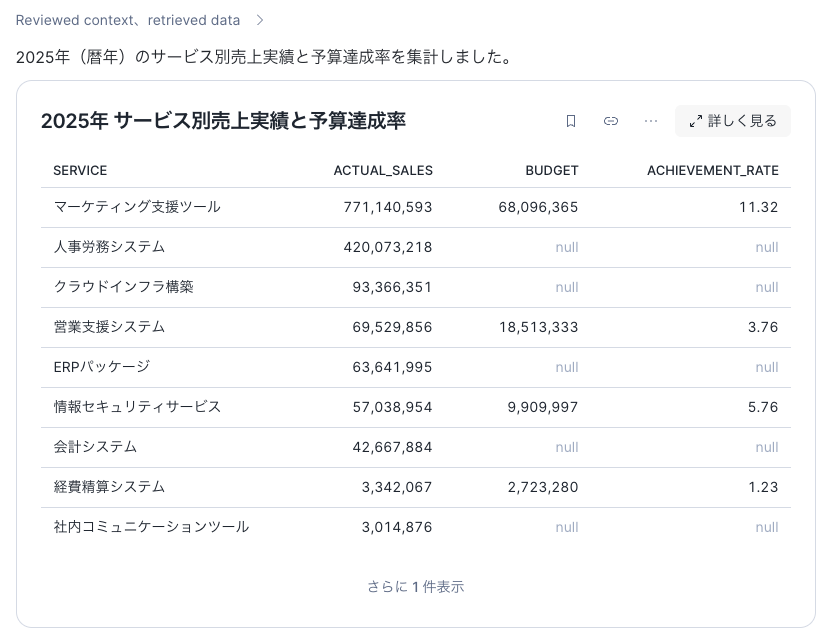
Q. 2025年全体の売り上げをサービスごとに集計して、併せて予算達成率も表示して
定量的な質問に対しては、意図通りにCortex Analystがデータから集計して回答します。
Q. サービスによって予算達成率に大差がある原因を分析して
オープンクエスチョンであっても、AIが分析の観点を自己判断して回答します。
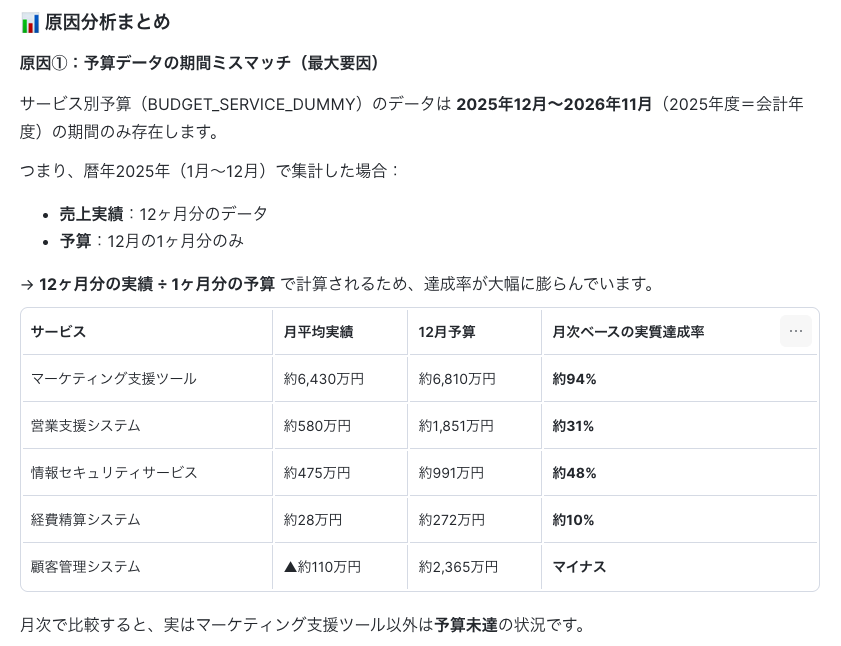

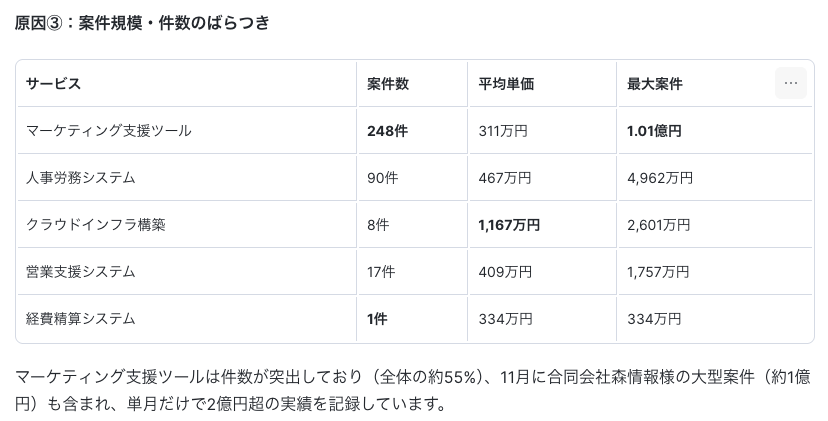
Q. サービスを問わず、失注している案件では先方が何に懸念を示しているのか、受注できている案件では先方が何に価値を見出しているのかを分析して。
テキストの文脈からポジティブ / ネガティブを分類し回答します。


Q. 1番売上実績が低いサービスが改善すべきアクションを、売上実績が高いサービスを参考に考えて。
データの分析のみならず、そこからのアクションの提案や意思決定の支援も可能です。




5. まとめ
今回は、Snowflake Cortex AIを活用し、構造化・非構造化データを横断して分析する仕組みをご紹介しました。
これまではSQLなどの専門スキルが必要だったデータ分析も、Snowflake Cortex AIを活用することで、誰もが「日常の言葉」で即座にインサイトを得られるようになります。これは単なる効率化にとどまらず、現場の「気づき」を意思決定のスピードへ直結させることに繋がります。
Snowflake Cortex AIの価値を最大限に発揮するには、本記事でもご説明したようにセマンティックビューやデータ基盤の構築を始めとしたデータ整備が必要不可欠です。
キーウォーカーでは、今回ご紹介したSnowflake Cortex AIの導入はもちろん、その前段階となるデータ基盤の構築から、実際のビジネスに即した活用支援まで、トータルでサポートしております。「自社のデータで、どのような分析が可能なのか」「まずはスモールスタートで試してみたい」といったご相談も大歓迎です。データ活用でお困りの際は、ぜひお気軽に弊社までお問い合わせください。
参考
[1]https://www.snowflake.com/en/product/features/cortex/
