初めに
以前執筆したブログで、dltを用いてOpenWeatherMap APIからSnowflakeにデータを格納する方法を紹介しました。今回は、その続編として格納したデータをdbtを用いて整形する方法を紹介します。コードの中身やディレクトリの構成は前回のブログの内容が前提となっているため、そちらもご覧ください。dbtとは
dbt(data build tool)とは、ほぼSQLのみでデータを変換し、データウェアハウスやデータマートを構築するツールであり、ETLパイプラインにおけるT(Transform)を担います。これまでのブログで紹介したdltはE(Extract)やL(Load)を担いますが、dbtはすでに格納されたデータを読み込んで変換することに優れています。詳細は後述しますが、dbtは基本的なデータを変換する機能に加えて、データリネージの自動生成やGitとの連携など保守・管理面でも優れており、データエンジニア領域でのデファクトスタンダードなツールです。また、dbtにはdbt-coreとdbt-cloudの2種類があります。今回紹介するのはdbt-coreでの実装方法であり、これはCLI(Command Line Interface)のため他製品への組み込みがしやすく、かつOSS(Open Source Software)のため無料で使用可能です。一方、dbt-cloudはSaaS製品でありプランによっては有料のものもありますが、GUI(Graphical User Interface)でアプリが提供されるため直感的に操作可能です。
前準備
データの格納
Snowflakeにデータを格納するまでの手順は前回のブログをご覧ください。ここで、APIを実行するだけでは不要なカラムまで取得されるため、dbtを用いて必要なカラムやレコードに絞ったテーブルを作ります。今回は、前回のコードに追記する形で変換処理を実装していきます。プロジェクトの作成
以下のコマンドを実行します。BigQueryなど他のDBを使う場合は適宜コマンドを変えてください。pip install dbt-core dbt-snowflakeインストール後、前回作成したdltのパイプラインと同じディレクトリの直下で以下のコマンドを実行します。
dbt init dbt_weather最終的に、以下のディレクトリ構成となります。
weather_pipeline/ # プロジェクトルートディレクトリ ├── dlt_pipeline/ # dlt関連ファイル (ここで dlt init 実行) │ ├── .dlt/ # secrets.toml等を格納するディレクトリ。ここから認証情報を読み取る │ ├── dlt_weather_test.py # APIを実行しSnowflakeにデータを格納するコード │ └── ... ├── dbt_weather/ # dbt関連ファイル (ここで dbt init 実行) │ ├── dbt_project.yml. # dbtにプロジェクトの操作方法を指示するファイル │ ├── models/ # 整形するSQLクエリを格納するディレクトリ │ └── ...
profiles.yamlの作成
dbtは接続したDBにデータモデルを生成するツールのため、DBへの認証情報を設定する必要があります。ホームディレクトリ直下の.dbt(隠しフォルダ)内に以下のprofiles.yamlを作成します。今回はキーペアで認証しているため11~16行目はその情報を記載していますが、ここは認証方法に合わせて適宜書き換えてください。
dbt_weather: # 任意のプロファイル名(dbt_project.yml の profile: に一致させる)
target: dev
outputs:
dev:
type: snowflake # 固定(Snowflakeの場合)
account: <account_id> # SnowflakeのアカウントID(URLの最初の部分)
user: <user_name> # Snowflake のユーザー名(例: JOHN_SMITH)
role: <role_name> # 使用するロール(権限レベルの高いもの推奨。例: SYSADMIN)
# キーペア認証設定
private_key_path: <key_path> # 秘密鍵ファイルのフルパス(通常は ~/.ssh 配下など)
# または下記のように文字列を直接指定も可能(非推奨・セキュリティ上注意):
# private_key: "-----BEGIN PRIVATE KEY-----\nMIIEvQIBADANBgkqh..."
private_key_passphrase: <key_passphrase> # 鍵作成時に設定したパスフレーズ。未設定なら省略可能
database: DLT_WEATHER # 使用するデータベース名(例: ANALYTICS)
warehouse: COMPUTE_WH # 使用するウェアハウス(例: COMPUTE_WH)
schema: DBT_WEATHER_TEST # 使用するスキーマ(例: PUBLIC)
threads: 1 # 並列実行数。1〜4程度で始めればOK
client_session_keep_alive: False # 接続の維持(長時間処理がある場合 True にすることも)
query_tag: dbt_weather_run # 任意のクエリ識別タグ(監査・ログ用途)
# ⏱️ 以下はオプション(必要に応じて設定)
connect_retries: 0 # 接続リトライ回数
connect_timeout: 10 # タイムアウト秒数
retry_on_database_errors: False # データベースエラーでの自動再試行を有効にするか
retry_all: False # すべての失敗で再試行を行うか
reuse_connections: True # 接続の再利用を行うか
モデルの作成
dbtでは、SQLクエリを実行しデータを変換、テーブルを作るまでの一連の処理を「モデル」と呼びます。weather_pipeline/dbt_weather/models 内にSQLクエリを格納します。
//WordPressのエラー解消のために全文コメントアウトしています。
/*
WITH source_data AS (
SELECT
MAIN__TEMP_MAX AS max_temp,
MAIN__TEMP_MIN AS min_temp,
name AS prefectures
FROM {{ source('DBT_WEATHER_TEST', 'weather') }}
WHERE name IN ('Tokyo', 'Aichi', 'Fukuoka')
)
SELECT *
FROM source_data
*/
カラムを最高・最低気温、都道府県名の3つだけ取得し、さらに取得するレコードを東京都、愛知県、福岡県の3つに絞っています。
また、同じフォルダ内に以下のファイルを格納します。
version: 2
sources:
- name: DBT_WEATHER_TEST # dbt上でのschema名(任意の別名ではなく、Snowflake上のスキーマ名に合わせる)
database: DLT_WEATHER # ← DLTが書き込んだSnowflakeのDB名(例: WEATHER_DB)
schema: DBT_WEATHER_TEST
tables:
- name: weather
そして、dbt_project.ymlのmodels:以降を以下のように書き換えます。
models:
dbt_weather:
# Config indicated by + and applies to all files under models/example/
+materialized: view
dbt_project.ymlは最初にdbt init を実行した時に作成されるファイルで、上記はmodels/直下の全てのSQLクエリをviewとしてmaterializedすることを意味します。materializationとはモデルを格納する際の形式のことで、全部で4種類あります。詳しくはこちらの記事をご覧ください。
前準備はこれで以上です。
データの取得・格納・変換
以下のコード(dlt_weather_test.py)を実行します。37行目のtry以降が前回のコードから追加した部分で、dltでのロード後に自動でdbtによる変換を実行します。dbt run はdbtを実行するコマンドで、通常はターミナル上で直接コマンドを実行しますが、今回はsubprocessを用いてPythonのコードから実行します。この際に、相対パスでdbt_weatherのプロジェクトフォルダを指定します。
import dlt
import pandas as pd
from dlt.sources.helpers import requests
import subprocess
API_key = dlt.secrets["openweathermap"]["API_key"]
df = pd.read_excel("prefecture.xlsx") # A列にidがある
city_list = df["City_id"].tolist() # "City_id"列をリスト化
weather_data = []
# 各都道府県についてAPIを実行
for city in city_list:
url = f"https://api.openweathermap.org/data/2.5/weather?id={city}&appid={API_key}"
response = requests.get(url)
if response.status_code == 200:
weather_data.append(response.json()) # JSONデータをリストに追加
else:
print(f"Error fetching data for {city}: {response.status_code}")
weather_df = pd.DataFrame(weather_data)
pipeline = dlt.pipeline(
pipeline_name="weather_snowflake",
destination="snowflake",
dataset_name="DBT_WEATHER_TEST",
)
#実際のコードでは@を_に変えてください
load_info = pipeline.run(weather_data, table@name="weather")
try:
subprocess.run(
["dbt", "run", "--project-dir", "../dbt_weather"],
check=True
)
print("dbt run completed successfully.")
except subprocess.CalledProcessError as e:
print("dbt run failed:", e)
実行結果
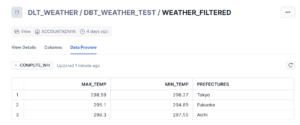
整形したテーブル
最初にDBT_WEATHER_TEST.WEATHERへRAWデータを格納した後に、それを整形したテーブルをDBT_WEATHER_TEST.WEATHER_FILTERED へ格納しています(WEATHER_FILTEREDは前準備で作成したSQLクエリのファイル名です)。
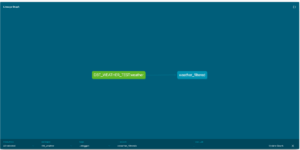
データリネージ
source 関数を用いて実装しているため、dbtのドキュメント機能でデータリネージを追うことができます。以下のコマンドを実行することでブラウザが立ち上がります。
dbt docs generate dbt docs serve今回は元テーブルもSQLクエリも一つしかないためデータリネージ図を作るメリットが薄いですが、数が増えてくるとこの機能を用いて依存関係を分かりやすく可視化できます。また、この機能はdbtを実行する際にも関わっており、クエリが複数存在していてもそれらの実行順序をユーザーが手動で設定する必要はなく、dbt側で自動的に考慮されます。
最後に
今回はdltを用いてSnowflakeにデータを格納し、さらにそれをdbtを用いて整形するまでの流れを紹介しました。記事で紹介したように、dbtはただデータを整形するだけではなく、整形の流れやモデル間の依存関係も自動で可視化できます。さらに、今回紹介した以外にも、dbtプロジェクトをGitHubにPushする事でバージョン管理が容易にできるなどの様々なメリットがあります。参考
- dbtのCLI版をインストールして使ってみた
- dbtで始めるデータパイプライン構築〜入門から実践〜
- Snowflake setup
- DuckDBにdltでロードしたデータをdbtで整形してevidenceで可視化した
