Vanna.AIとは
Vanna.AIは、RAG(Retrieval-Augmented Generation)フレームワークの一つで、データベース上でSQLを生成・実行し、抽出したデータの可視化まで自動で行うことで、自然文での質問に対する応答やレポート作成などのタスクを支援するツールです。
生成AIを活用することで、ユーザーが入力した質問に対して最適な情報を抽出するSQLを生成でき、データの統合やカスタムプロンプトによる柔軟な出力が可能です。
Vanna.AIでできること
Vanna.AIを利用することで、以下のようなタスクが実現できます。
- 文書検索と情報抽出
大量のテキストデータから必要な情報を効率的に検索・抽出できます。 - 自然言語質問応答
ユーザーの質問に対して、背景知識や学習済みデータに基づいた回答を生成します。 - 自動クエリ生成
データベースの構造を学習し、ユーザーの意図に沿ったSQLクエリなどの自動生成が可能です。 - 多様なデータ統合
複数のデータソースや形式を統合し、分析やレポート作成に活用できます。 - カスタムプロンプトによるレポート生成
特定のニーズに合わせたカスタマイズ可能なレポートを自動生成します。
Vanna.AI + Geminiを使う準備
Vanna.AIでは様々なOpenAIやAnthropicなど、多種多様なLLMとの連携をサポートしています。
本ブログではGoogleのLLMであるGeminiを使用するので、その手順を以下に記載します。
Gemini APIキーの取得
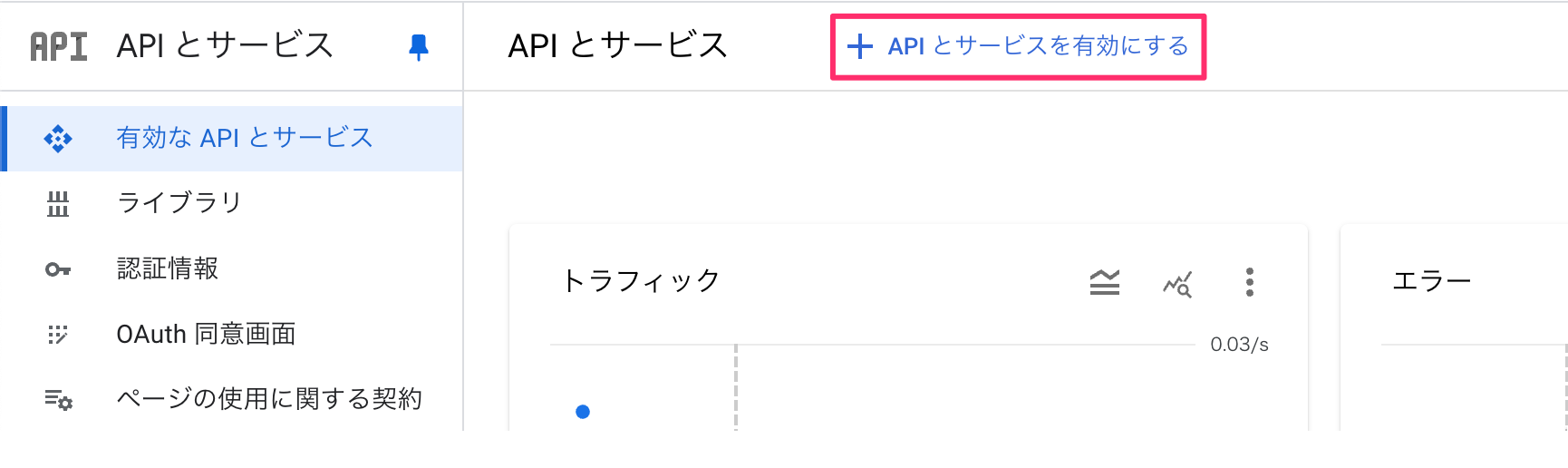
- GCPのAPIとサービス画面を開く
- 「API とサービスを有効にする」をクリック
- 「gemini api」を選択
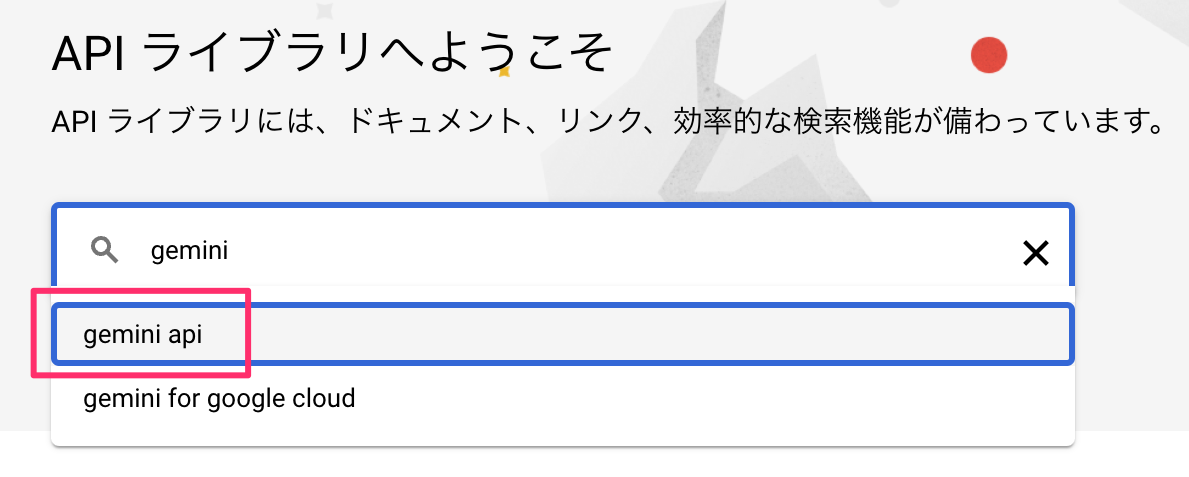
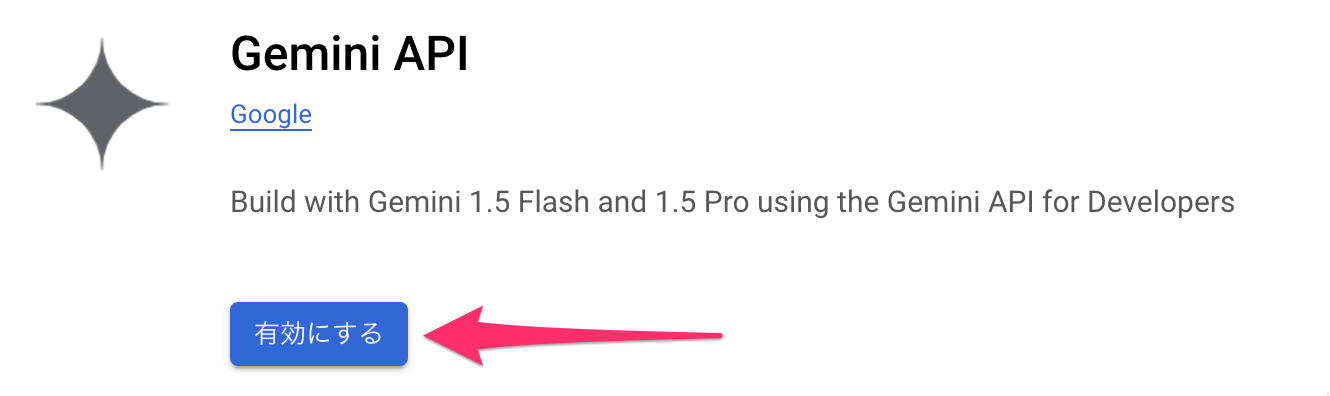
- 「Gemini API」を選択

- 「有効にする」をクリック
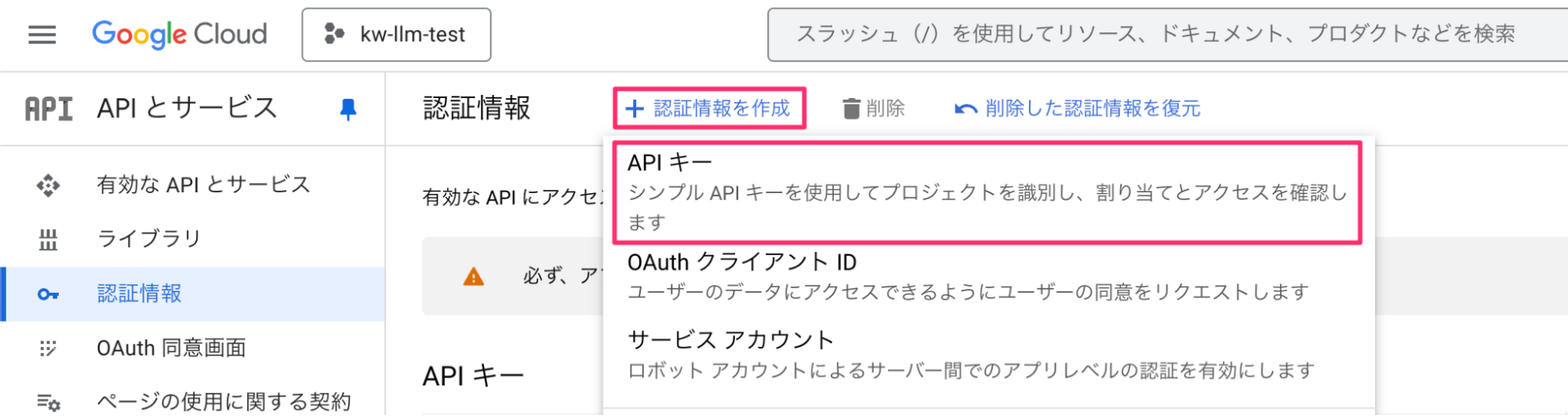
- 「APIとサービス」から「認証情報を作成」をクリック。「APIキー」を選択
- キーに名前(Gemini API Key)をつけ、「APIの制限(Generative Language API)」し、保存をクリック
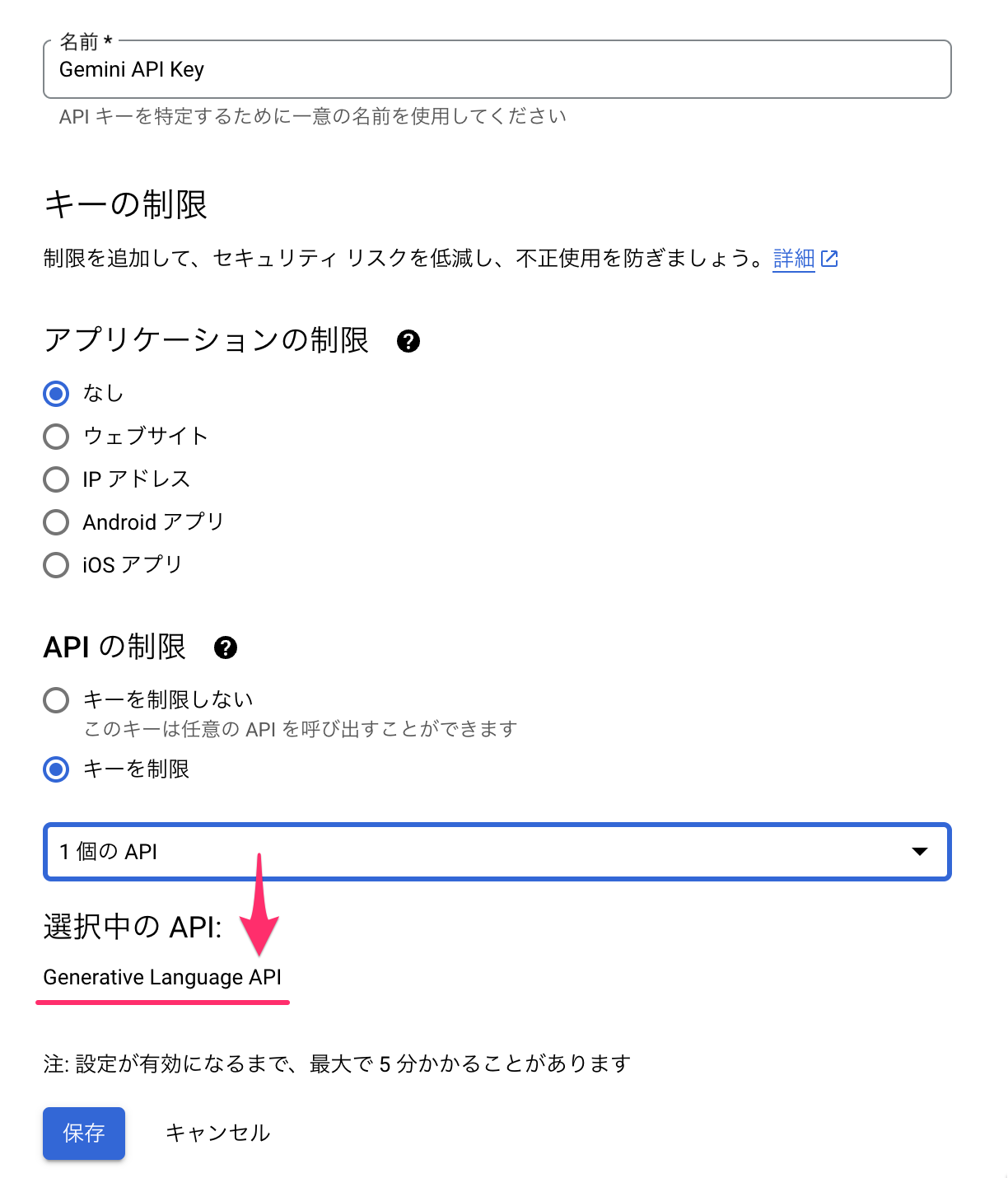
- 「鍵を表示します」をクリックし、APIキーを取得(CTRL + C でコピーしておく)

サンプルデータを作成する
今回はVanna.AIに読み込ませるデータとして国勢調査 / 時系列データ / CSV形式による主要時系列データを使用します。
また、BigQuery等のデータソースに接続することもできますが、今回は簡易的にCSVデータを基に手元でSQLiteを用意しています。
- CSVデータをダウンロードします
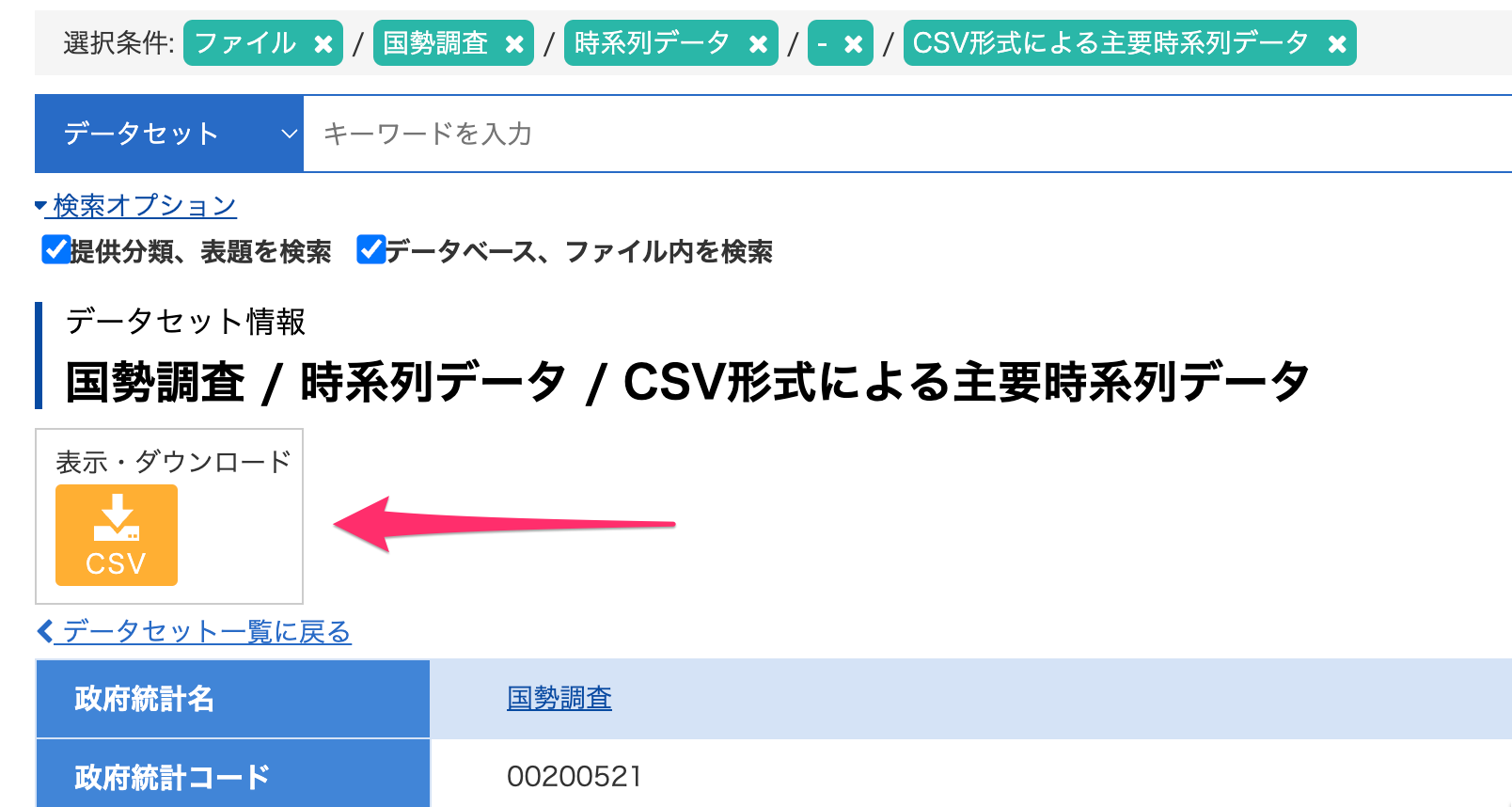
- CSVファイルを開きカラム構造とデータ内容を確認します
都道府県コード 都道府県名 年齢5歳階級 元号 和暦(年) 西暦(年) 人口(総数) 人口(男) 人口(女) 1 北海道 総数 大正 9 1920 2359183 1244322 1114861 1 北海道 0~4歳 大正 9 1920 376676 190044 186632 1 北海道 5~9歳 大正 9 1920 319370 161814 157556 1 北海道 10~14歳 大正 9 1920 270012 138018 131994 1 北海道 15~19歳 大正 9 1920 239092 125670 113422 1 北海道 20~24歳 大正 9 1920 208337 109351 98986 - CSVファイルをsqliteに変換します
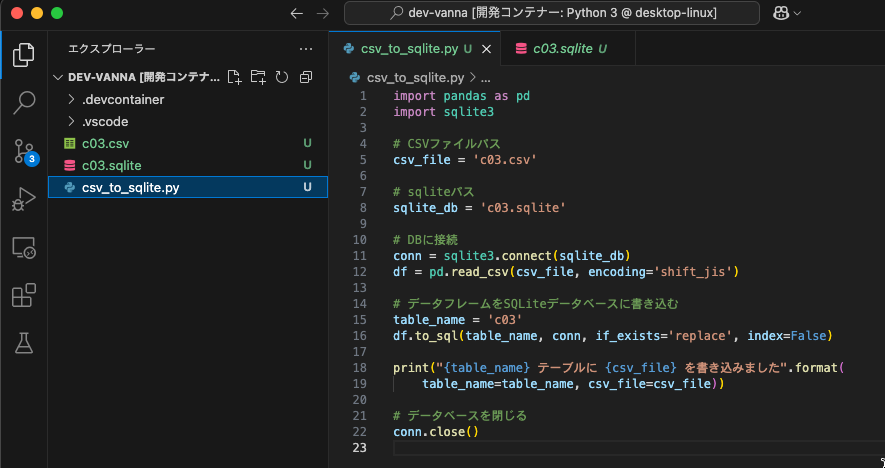
csv_to_sqlite.pyを作成
※ SQLのカラム名はマルチバイト指定ができないので、日本語を英語に変換してます。import pandas as pd import sqlite3 # CSVファイルパス csv_file = 'c03.csv' # sqliteファイルパス sqlite_db = 'c03.sqlite' # DBに接続 conn = sqlite3.connect(sqlite_db) # CSVファイルを読み込む df = pd.read_csv(csv_file, encoding='shift_jis') # カラム名の日本語から英語への変換マッピング rename_dict = { '都道府県コード': 'pref_code', '都道府県名': 'pref_name', '年齢5歳階級': 'age_group', '元号': 'era', '和暦(年)': 'jp_year', '西暦(年)': 'western_year', '人口(総数)': 'total_population', '人口(男)': 'male_population', '人口(女)': 'female_population' } # カラム名を英語に変更 df.rename(columns=rename_dict, inplace=True) # テーブル名を変更してSQLiteに書き込む table = 'c03' df.to_sql(table, conn, if_exists='replace', index=False) print(f"{table} テーブルに {csv_file} を書き込みました") # データベースを閉じる conn.close()
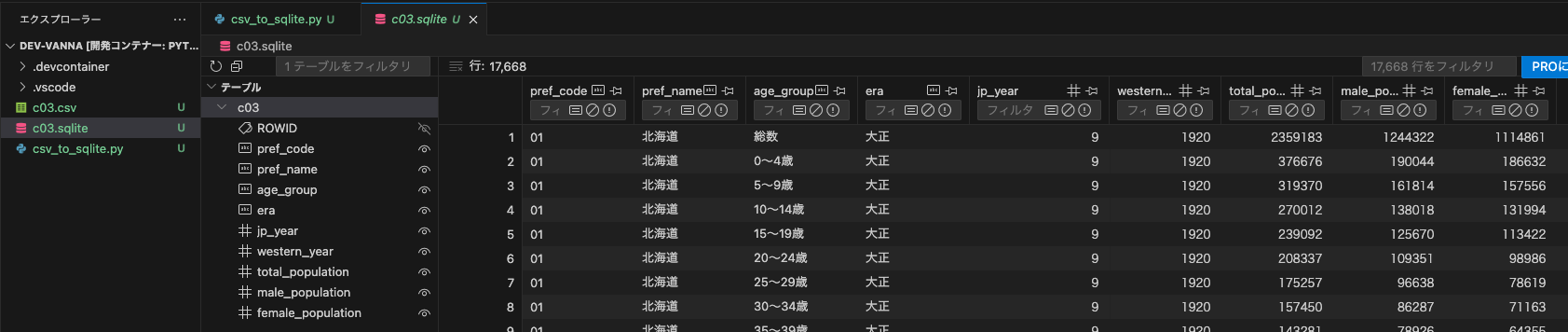
ルートディレクトリにダウンロードしたCSVファイル(c03.csv)を移動し、csv_to_sqlite.pyを実行すると、c03.sqliteが出力される
c03.sqliteを開くと、テーブルが参照できる。参照できない場合はSQLite Viewerをインストールする
Vanna.AIをローカルで動かす
モジュールをインストールする
以下の組み合わせでVannaのインスタンスを作成します。
※ 公式ドキュメント
- LLM:Gemini
- トレーニングデータ:ChromaDB
- DB:SQLite
pip install 'vanna[chromadb,gemini]'
Vannaインスタンスを作成する
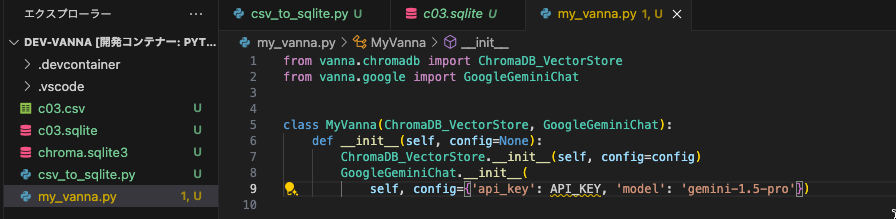
from vanna.chromadb import ChromaDB_VectorStore
from vanna.google import GoogleGeminiChat
class MyVanna(ChromaDB_VectorStore, GoogleGeminiChat):
def __init__(self, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
GoogleGeminiChat.__init__(self, config={'api_key': API_KEY, 'model': 'gemini-1.5-pro'})
トレーニングする
Vanna.AIを利用するためには事前にトレーニングデータが必要となります。
トレーニングデータが必要な理由
トレーニングを行っていない状態でVanna.AIを使うと以下のような結果になります。
- 質問:「青森県の各年代における総人口の変化を、年齢区分と共に表示してください」
- 回答のSQL:
SELECT 年齢区分, SUM(人口総数) FROM 人口構成 WHERE 都道府県 = '青森県' GROUP BY 年齢区分;
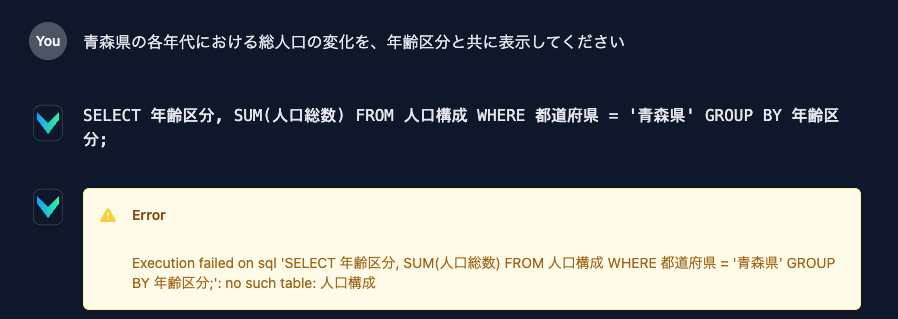 テーブル名やカラム名がチグハグで使い物になりません。
テーブル名やカラム名がチグハグで使い物になりません。
トレーニング方法
トレーニングはいくつか方法がありますが、最も手軽で効果的な方法はdocumentationを使うことです。
documentationを使うことで以下の情報をプロンプトとしてVannaに学習させることができます。
- データ概要
- テーブル名
- カラム名
- データ型
- データの説明
- データサンプル
コードの例
# train_documentation.py
from my_vanna import MyVanna
vn = MyVanna()
vn.connect_to_sqlite('c03.sqlite')
vn.train(documentation="""
# テーブル名: c03
## 説明
このテーブルは、日本の各都道府県の人口統計データを記録しています。
各レコードは以下の情報を含みます:
- 都道府県コード (pref_code)
- 都道府県名 (pref_name)
- 5歳刻みの年齢区分 (age_group) ※「総数」も含む
- 元号 (era)
- 和暦 (jp_year)
- 西暦 (western_year)
- 総人口 (total_population)
- 男人口 (male_population)
- 女人口 (female_population)
## カラム詳細
- **pref_code** (INTEGER)
各都道府県を一意に識別するコード
*例*: 01(北海道)、13(東京)、27(大阪)
- **pref_name** (TEXT)
都道府県の名称
*例*: "東京都", "大阪府", "北海道"
- **age_group** (TEXT)
5歳ごとの年齢区分、または「総数」
*例*: "0〜4歳", "5〜9歳", "総数"
- **era** (TEXT)
データ記録時の元号
*例*: "大正", "昭和", "平成", "令和"
- **jp_year** (INTEGER)
元号に対応する和暦年
*例*: 50(昭和50年)
- **western_year** (INTEGER)
和暦に対応する西暦年
*例*: 1975
- **total_population** (INTEGER)
該当年の総人口
*例*: 13515271
- **male_population** (INTEGER)
該当年の男性人口
*例*: 6685539
- **female_population** (INTEGER)
該当年の女性人口
*例*: 6829742
""")
学習後、もう一度同じ質問をしてみます。
- 質問:「青森県の各年代における総人口の変化を、年齢区分と共に表示してください」
- 回答のSQL:SELECT age_group, total_population FROM c03 WHERE pref_name = ‘青森県’ ORDER BY age_group;
このように、正しくテーブル名やカラムが正しく指定できます。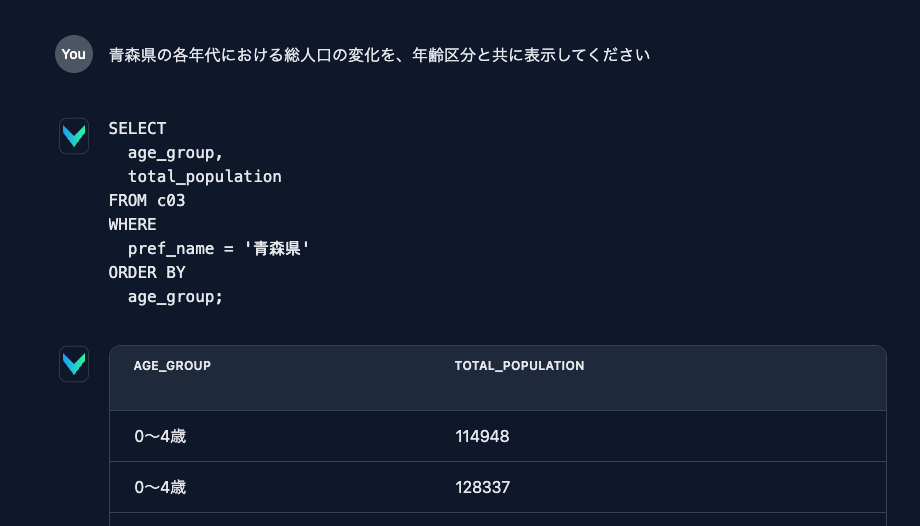
チャートや分析結果も表示されます。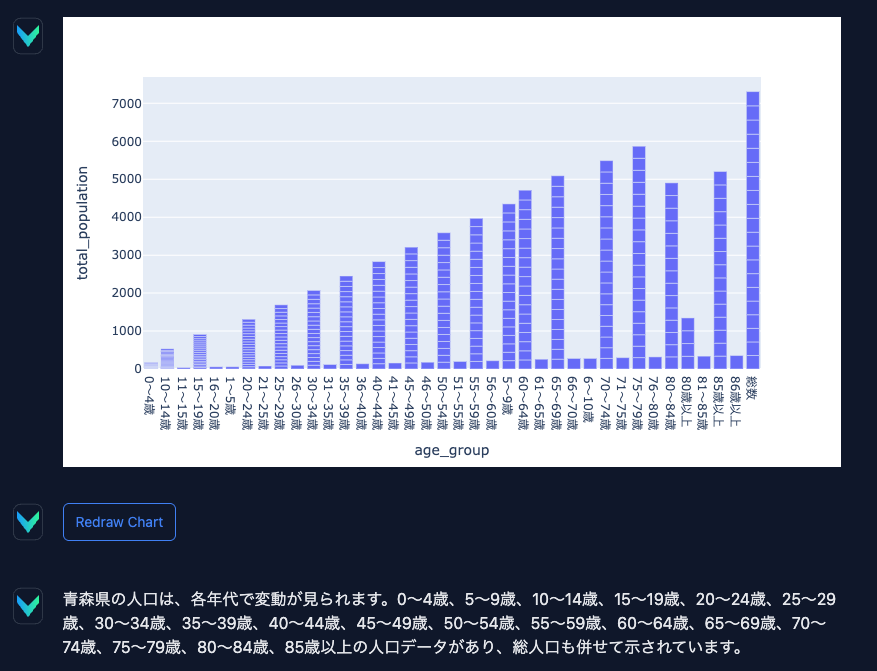
Were the results correct?に対して、出力されたデータの正誤を回答することで更に生成するSQLの精度を高めることができます。
クエリが間違っていた場合は、Noをクリックします。
今回はwestern_year(西暦)が抜けていたので生成されたクエリに付け足します。
クエリの修正が終わったら「Run SQL」をクリックします。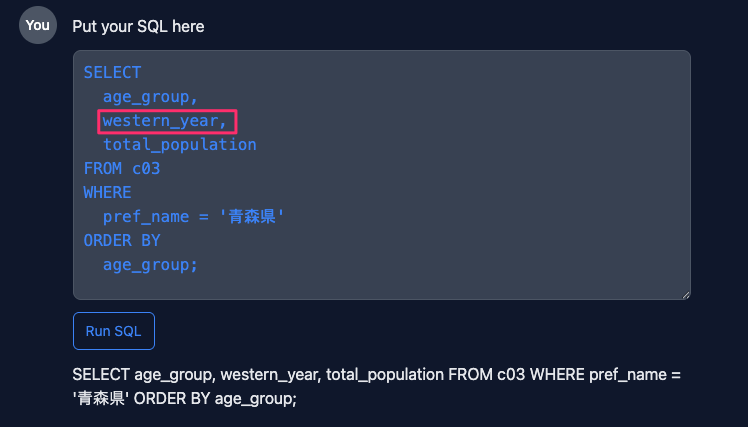
正しいクエリ結果が出力されました。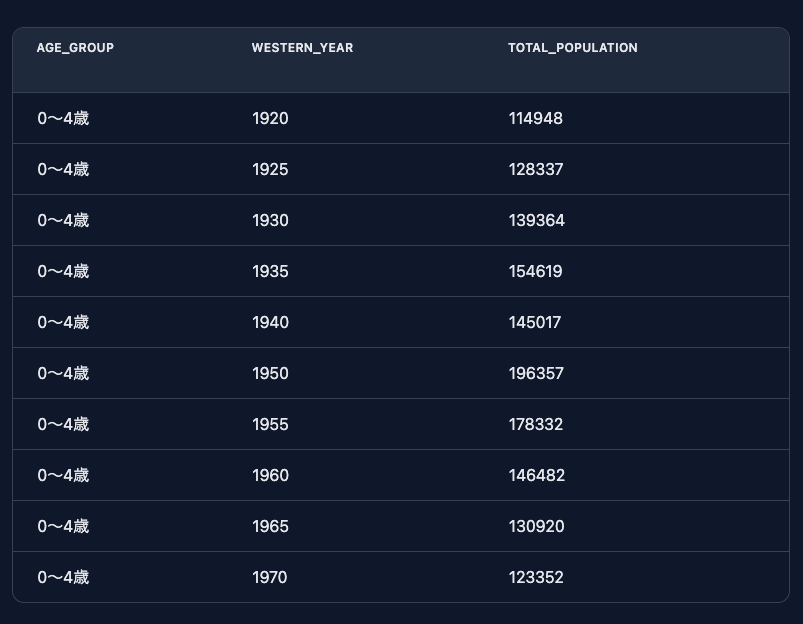
まとめ
Vanna.AIを手元で動かし、簡単にデータ分析を行うことができました。
Vanna.AIには以下のようなメリットがあるので、データ分析を簡単に試してみたい方にはぜひおすすめです。
- 直感的なインターフェース
ユーザーが迷うことなく操作でき、初めてでもすぐに利用を開始できます。 - 高速な検索・回答生成
大量のデータから必要な情報を迅速に抽出し、実用的な回答を提供できます。 - 柔軟なカスタマイズ性
トレーニングデータの設定やプロンプトの調整が容易で、さまざまなユースケースに対応可能です。 - 豊富な機能群
文書検索、クエリ生成、データ統合など、複数の機能が統合されており、業務効率の向上に寄与できます。 - API連携のスムーズさ
外部システムとの連携が容易で、他のツールやサービスとの統合もスムーズに実装できます。
