はじめに
先日 5/22〜5/27 にアイルランドのダブリン(およびオンラインのハイブリッド)にて、自然言語処理のトップ国際会議 The 60th Annual Meeting of the Association for Computational Linguistics (ACL2022) が開催されました。
弊社からはデータサイエンス部の宮脇峻平が、大学時代に取り組んでいた研究* で、ACL Student Research Workshop (ACL-SRW) にてポスター発表(オンライン)を行いました。
* NTT人間情報研究所の長谷川拓氏・西田京介氏、および東北大学(乾研究室, 鈴木研究室)の加藤拓真氏・鈴木潤氏と執筆いたしました。
Scene-Text Aware Image and Text Retrieval with Dual-Encoder
Shumpei Miyawaki, Taku Hasegawa, Kyosuke Nishida, Takuma Kato, Jun Suzuki [paper]
本記事では、自然言語処理プラットフォーム sente 開発チームとしての視点から、 現在取り組んでいる固有表現抽出、レビュー分析などの分野について、注目した論文を紹介したいと思います。
筆者自身まだまだ勉強不足ですが、自然言語処理を研究・開発対象にしている方々の参考になれば幸いです。
1. 固有表現抽出(NER: Named Entity Recognition)
文書内から地名や商品名などを特定する固有表現抽出は、金融[1]・生物医学[2]・化学[3] など多様な分野で必要とされる基盤技術であり、機械翻訳や画像検索[4] などの応用分野でも重要な役割を果たしています。
近年では、GiNZA NLP Library[5] のような素晴らしいライブラリが公開されている一方で、下図のような拡張固有表現[6] などに対する取り組み[7] や、タイポ・out-of-vocabulary に対する頑健性向上などについては、今後の課題とされています。

Zhu+’22 – Boundary Smoothing for Named Entity Recognition (ACL)
https://aclanthology.org/2022.acl-long.490/
固有表現抽出に限らず、機械学習モデルの予測結果に対するキャリブレーションの課題(出力スコア∝確信度になるとは限らない)は、実応用でも非常に重要な課題となります。
本研究では、エンティティの境界値に対してスムージングを行うことでこの課題に取り組んでおり、 モデルの予測性能に対する効果だけでなく、シンプルな設計から高い汎用性を担保している点で、非常に興味深い内容だと感じました。

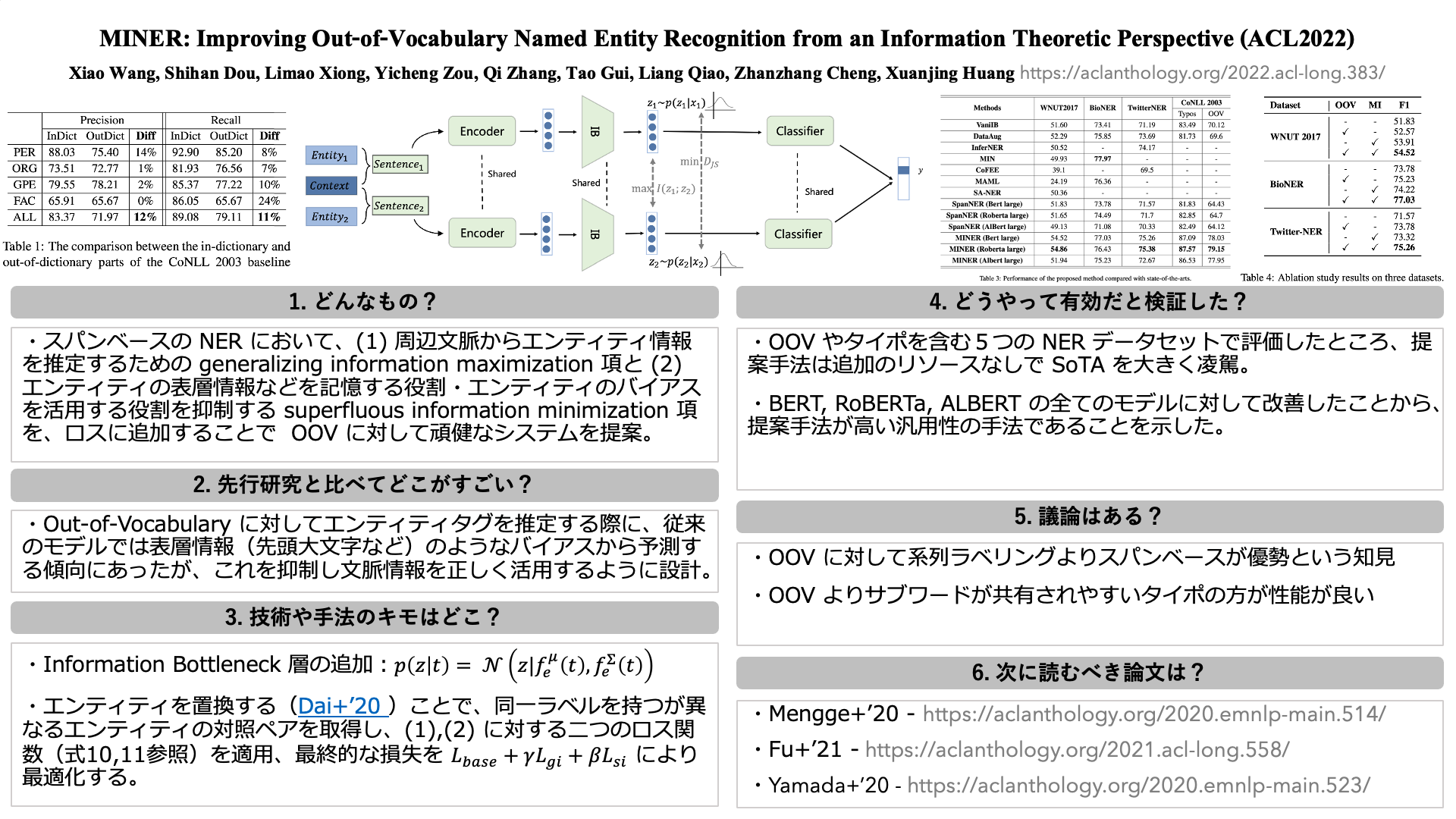
Wang+’22 – MINER: Improving Out-of-Vocabulary Named Entity Recognition from an Information Theoretic Perspective (ACL)
https://aclanthology.org/2022.acl-long.383
先にも述べたように固有表現抽出では、タイポや out-of-vocabulary に対する頑健性向上が今後の課題とされています。
本研究ではスパンベースの手法を対象に、固有表現の推定を (1) 周辺文脈からの予測 (2) エンティティ自身からの予測、の二パターンに分けて考えています。
out-of-vocabulary のエンティティに対して、表層情報を安易に過信せず周辺文脈からの情報を用いて推定するという直感をうまく定式化していることから、 提案法に対して納得感ある結果で、とても面白い内容だと感じました。
Ma+’22 – Label Semantics for Few Shot Named Entity Recognition (ACL)
https://aclanthology.org/2022.findings-acl.155/
固有表現抽出タスクにおける近年のトレンドとして、系列ラベリングからスパンベースの手法[8,9] へとシフト傾向にあるかと思います。
本研究ではテキストエンコーダとラベルエンコーダから構成されたデュアルエンコーダ型の新しい枠組みを提案しており、具体的には “PER” ラベルを “begin person” のような自然言語に変換し、ラベルとトークンの意味表現間で内積値による類似度を最大化する枠組みを用いています。
デュアルエンコーダは、エンコードと推論が分離可能(オフライン検索)であることから、検索対象が大規模かつ高速な推論が要求される文書検索やマルチモーダル検索などの分野で注目されています。
文書検索などでは DPR [10,11] のような文書全体を扱うモデルが一般的で、文レベル[12,13] やフレーズレベル[14] に落とし込む話も研究されていますが、系列ラベリングに落とし込む手法として新たな可能性を感じました。

参考
[1] Loukas+’22 – FiNER: Financial Numeric Entity Recognition for XBRL Tagging (ACL) [ACL]
[2] GENIA [project]
[3] He+’20 – ChEMU: Named Entity Recognition and Event Extraction of Chemical Reactions from Patents (ECIR) [project]
[4] Wang+’22 – ITA: Image-Text Alignments for Multi-Modal Named Entity Recognition (NAACL) [arXiv]
[5] GiNZA – Japanese NLP Library [project][GitHub]
[6] Sekine+’02 – Extended Named Entity Hierarchy (LREC) [LREC][project]
[7] 森羅2022 Wikipedia構造化プロジェクト [project]
[8] Fu+’21 – SpanNER: Named Entity Re-/Recognition as Span Prediction (ACL) [ACL]
[9] Yamada+’20 – LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention (EMNLP) [LUKE (EMNLP)][mLUKE (ACL)][NLPコロキウム]
[10] Karpukhin+’20 – Dense Passage Retrieval for Open-Domain Question Answering (EMNLP) [EMNLP]
[11] 加藤拓真, 宮脇峻平, 第二回AI王最終報告会 – DPR ベースラインによる オープンドメイン質問応答の取り組み(第2回AI王 2022) [slide]
[12] Hong+’22 – Sentence-aware Contrastive Learning for Open-Domain Passage Retrieval (ACL) [ACL]
[13] Zhang+’22 – Multi-View Document Representation Learning for Open-Domain Dense Retrieval (ACL) [ACL]
[14] Lee+’21 – Phrase Retrieval and Beyond [page]
2. アスペクトベース感情分析(ABSA: Aspect-Based Sentiment Analysis)
入力文に対して感情極性の分類を行う感情分析(SA, coarse-grained sentiment analysis)は、有害文検出 [1,2] や dialogue safety [3]、商品レビュー解析 [4]など、多くの分野で重要な役割を示しています。
特に近年では、分類モデルの頑健性を高めるための取り組みが注目されています [5,6]。
アスペクトベース感情分析(ABSA, fine-grained sentiment analysis)[7, 8] は、入力文に対してアスペクト用語・カテゴリや意見語検出、感情極性分類など(下図参照)、細かな粒度で極性因子を特定することで高い説明性・頑健性を確保するタスクとして注目されています。
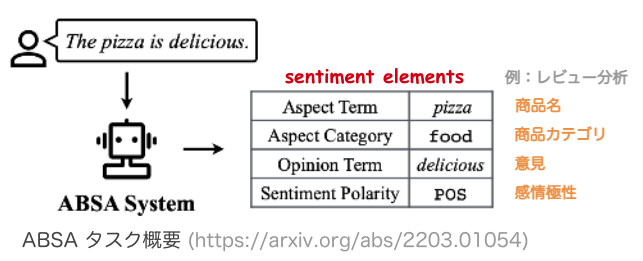
Zhang+’22 – Towards Unifying the Label Space for Aspect- and Sentence-based Sentiment Analysis (ACL)
https://aclanthology.org/2022.findings-acl.3/
日本語を対象にしたアスペクトベース感情分析の公開データセット [9,10,11] は少なく、ドメインが異なる場合のモデルの予測性能については明らかになっていません。
本研究では、(アスペクトベースにアノテーションする必要がある)アスペクトベース感情分析に対してアノテーションコストが低い文レベルの感情分析データセットを活用した、アスペクトベースの擬似データセットの効果について検証しており、アノテーション支援の観点から非常に価値のある手法だと感じました。

参考
[1] Jigsaw Rate Severity of Toxic Comments (2021) [kaggle]
[2] Toxic Comment Classification Challenge (2017-18) [kaggle]
[3] Dinan+’19 – Build it Break it Fix it for Dialogue Safety: Robustness from Adversarial Human Attack (EMNLP) [arXiv][ParlAI]
[4] 10 Sentiment Analysis Examples That Will Help Improve Your Products – WONDERFLOW [blog]
[5] Singh+’20 – Model Robustness with Text Classification: Semantic-preserving adversarial attacks [arXiv]
[6] Ribeiro+’20 – Beyond Accuracy: Behavioral Testing of NLP Models with CheckList [ACL][arXiv]
[7] A Survey on Aspect-Based Sentiment Analysis: Tasks, Methods, and Challenges [arXiv]
[8] 言語処理学会第28回年次大会 併設ワークショップ JED2022(日本語における評価用データセットの構築と利用性の向上)[slide]
[9] 栗原ら+’18 – 評価対象-評価表現抽出用 日本語Twitterデータセット (NLP) [NLP][doc]
[10] chakki’s Aspect-Based Sentiment Analysis dataset (chABSA) [GitHub]
[11] 中山ら+’21 – 楽天トラベルレビュー:アスペクト・センチメントタグ付きコーパス (NLP) [NLP][doc]
3. 機械読解(質問応答)
機械読解・質問応答は、与えられた質問や問い合わせに対して、関連する文書を検索し、過去の類似事例や文書から答えを推定するタスクとして広く関心を集めています。
特に近年では、文書だけでなく、シーン画像[1,2]や文書画像[3,4]、インフォグラフィック[5]、アイコン[6]など、マルチモーダル分野の読解タスクについても関心が高まっています[7,8]。
本ページでは質問応答タスクについて言及はしませんが、著者のブログでも今後まとめていきたいと思っています。
Li+’22 – MarkupLM: Pre-training of Text and Markup Language for Visually Rich Document Understanding
paperhttps://aclanthology.org/2022.acl-long.420/
第2回AI王の招待公演[9]でも紹介されていましたが、近年では Web 画面に対する機械読解研究も盛んに取り組まれています[10]。
本研究では、HTML/XML の DOM 構造を BERT ベースのモデルに組み込んだモデルを提案しており、Xpath 情報をモデル化するための学習目的を導入することで、視覚情報を入力とする既存手法の読解モデルを凌駕する性能を示しています。
クローラ技術を商品化している弊社にとって、とても興味深い内容で、ぜひ本モデルを応用した取り組みを今後行なってみたいと思っています。

参考
[1] Antol+’15 – VQA: Visual Question Answering (ICCV) [project][ICCV]
[2] Singh+’19 – Towards VQA Models That Can Read (CVPR) [project][CVPR]
[3] Mathew+’21 – DocVQA: A Dataset for VQA on Document Images (WACV) [project][WACV]
[4] Tanaka+’21 – VisualMRC: Machine Reading Comprehension on Document Images (AAAI) [arXiv][GitHub]
[5] Mathew+’21 – InfographicVQA [arXiv]
[6] Lu+’21 – IconQA: A New Benchmark for Abstract Diagram Understanding and Visual Language Reasoning (NeurIPS) [project][arXiv]
[7] 西田京介氏(NTT人間情報研究所) – 言語と視覚に基づく質問応答の最新動向(第1回AI王 2021)[slide]
[8] Vision-Language Pretraining: Current Trends and the Future (ACL2022 Tutorial) [project]
[9] 田中涼太氏(NTT人間情報研究所) – 文書画像に対する質問応答技術の最新動向(第2回AI王 2022)[slide]
[10] Chen+’21 – WebSRC: A Dataset for Web-Based Structural Reading Comprehension (EMNLP) [EMNLP]
おわりに
最後になりますが、弊社では自然言語処理エンジニアを募集しております。
ご興味のある方は、こちらからご応募下さい!
https://recruit.keywalker.co.jp
著者:宮脇峻平(データサイエンス部) [プロフィール]
最終更新日:2022.06.01
