この記事では、前回の記事で触れたGoogleの自然言語処理モデル「BERT」を用いた感情分析(ネガポジ分析)について、詳細を報告します。
ソース・実行環境
siny氏が公開しているchABSA datasetネガポジ分析器をベースに使用しました。このプログラムは、書籍「つくりながら学ぶ! PyTorchによる発展ディープラーニング」(小川雄太郎・マイナビ出版)に記載のIMDbネガポジ分析器を元にしており、書籍の英語実装を日本語実装に変えたものです。
BERT日本語事前学習モデルは京都大学黒橋研究室のものを、形態素解析器はJuman++を使用しました。学習は特記がなければGoogle Colaboratory上でGPUで実行しました。余談ですが、Juman++はWindows環境へのインストールが大変で、ローカル環境ではUbuntu経由で実行しました。
BERTのミニバッチサイズは32としました。
データ
キーウォーカーが2018年に取得したAmazon.co.jpのレビューデータを用いました。全データは重複を除いて163,966レコードです。
☆1をネガティブ、☆5をポジティブとし、学習データ・テストデータにおいては、ネガティブとポジティブの割合が等しく(半々に)なるようにしました。次節で述べる人力分類データを除き、学習データ数は1000, 5000, 10000, テストデータ数は1000としました。
ネガティブな文章の例
- 1ヶ月で壊れた。
- 品質管理の問題があります!プラスチックの蓋に焼けたゴミが混ざってたり、新品なのに、傷が最初から入っているものがありました!検品の徹底をきちんとしてください!
ポジティブな文章の例
- 簡単に組み立てできて、座り心地もいいです。
- この価格でこの音質ならば大変満足です。久々にいい買い物をしました。デザインも気にいりました。今後もこのメーカーに注目していきたいと思います。
文章の長さのメディアンは78文字、最大は15035文字、最小は1文字、平均±標準偏差は121.3±317.6文字でした。トークン数で見ると、メディアン40トークン、最大5529トークン、最小0トークン、平均±標準偏差61.9±118.2トークンとなりました。文字数の分布を図1に、トークン数の分布を図2に示します。
図1: 使用したデータの文字数分布
図2: 使用したデータのトークン数分布
人力分類・クレンジング
☆の数とレビューの内容が必ずしも一致しない、レビューの内容が曖昧である等の事態が考えられたため、Amazonレビューデータのうち、1400レコードを人力でネガティブ(0)・ポジティブ(1)・分類不能(2)に分類しました。この時、他製品に関する記述の削除も同時に行いました。分類したデータから分類不能(2)を削除し、残りの1307レコードを人力分類データとして学習に用いました。このとき学習データ942レコード、テストデータ365レコードとしました。人力で付与したラベルは92.6%が☆による元のラベルと一致しました。全体に占めるネガティブ(0)の割合は48.4%、ポジティブ(1)の割合は51.6%でした。
従来手法
まず、BERTとの比較のために、従来手法であるword2vecにて解析を行いました。この時、分かち書きにはsentencepieceを用いています。GBT(勾配ブースティング木)でネガポジ分類を行ったところ、学習データ1000で精度71%、10000で精度75%となりました。
最大文長の影響
人力分類データを用い、解析する最大文長32, 64, 128, 256, 512(トークン)で精度を調べました。最大文長がメディアンの40トークン、平均の61.9トークンに近いほど精度が高くなり、エポック数20でそれぞれ 79, 79, 70, 54, 53 [%] となりました。以後、最大文長64トークンで解析を行うこととしました。最大文長が長いケースでは、ほとんどのデータがネガティブに分類される傾向がありました。
図3: 精度に対する最大文長(トークン数)の影響
人力分類の影響
人力分類の影響を検討するため、人力分類データ(学習データ942)と、自動分類の学習データ1000のケースを比較しました。エポック数5においては人力分類の精度76%、自動分類の精度71%、エポック数20においてはそれぞれ79%、74%となり、いずれにおいても人力分類の精度が高い結果になりました。データ数1000程度の場合、人力によるクレンジングは有効だと考えられます。
図4: 精度に対する人力分類の影響
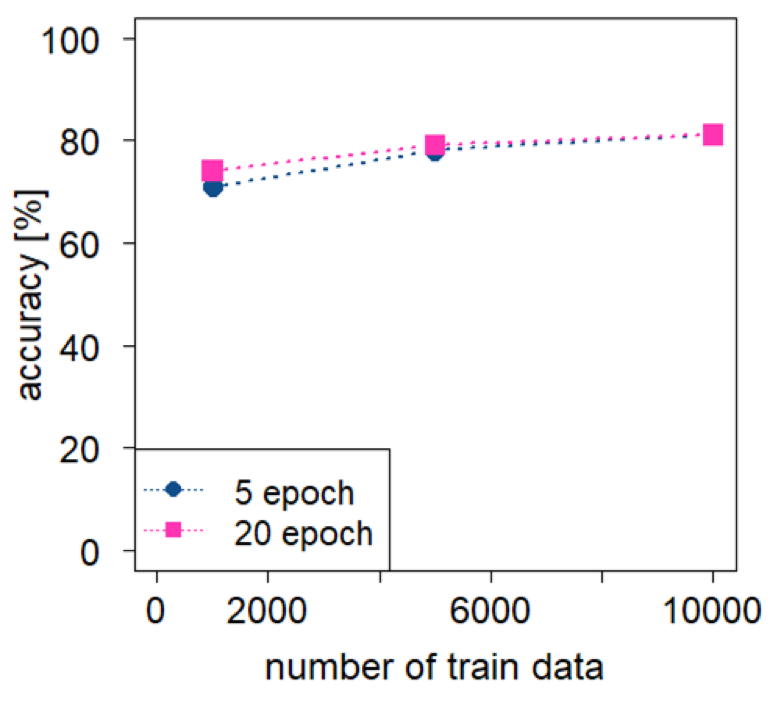
データ量とエポック数の影響
学習データ量と学習を行うエポック数の影響を調査しました。自動分類の学習データ1000, 5000, 10000について、5エポックで精度はそれぞれ71%、78%、81%、20エポックでそれぞれ74%、79%、81%となりました。人力分類のデータでは、5エポックで76%、20エポックで79%となりました。データ量が多いと少ないエポック数で学習が飽和すると考えられます。
図5: 精度に対するデータ量とエポック数の影響
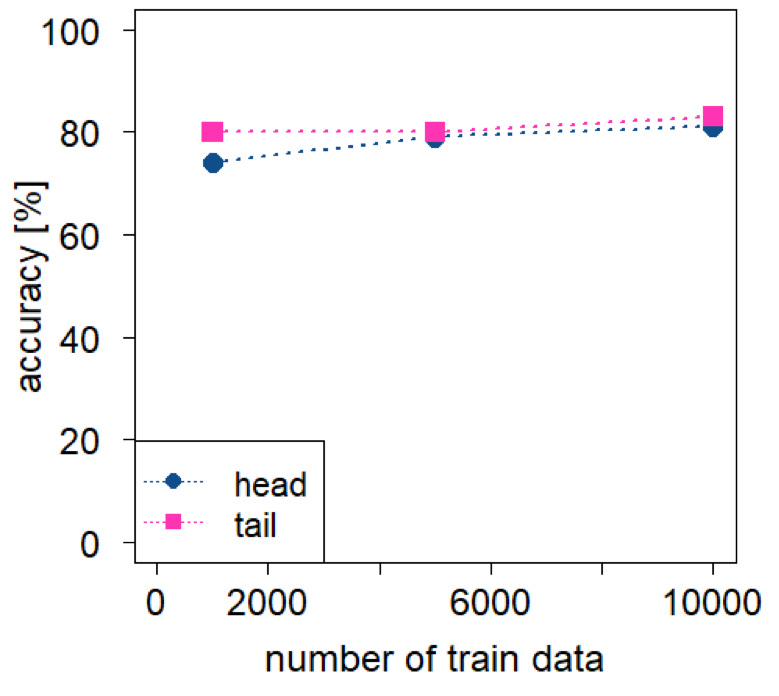
トリミング方法の影響
最大文長64トークンとしたとき、長いレビューでは一部のみを解析することになります。日本語の文章は結論が最後に来ることも多いため、解析する部分による影響を検討しました。文章を文頭から読み込み、文末をトリミングした場合と、逆に文末を保持して文頭をトリミングした場合の精度を比較しました。
自動分類データでは、文末を保持した場合の方が精度が高くなりました。文頭保持と文末保持の精度は、エポック数20において学習データ1000で74%と80%、5000で79%と80%、10000で81%と83%でした。逆に人力分類データでは、文頭を保持した場合が精度79%、文末を保持した場合が精度78%と少し低くなりました。データのクレンジングを行っていない場合は文末を保持した方が良いと考えられます。
図6: 精度に対するトリミング方法の影響
まとめ
Amazonレビューデータのネガポジ分析を行い、従来手法に対するBERTの優位性を示すことができました。従来手法では学習データ数10000で精度75%に対し、BERTにおいては、学習データ数10000で最高精度83%となりました。また、データ数1000程度の場合は人力によるデータのクレンジングがある程度有効と考えられます。
参考文献
Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” arXiv, 2018
小川雄太郎「つくりながら学ぶ! PyTorchによる発展ディープラーニング」マイナビ出版,2019
siny 「BERTを用いたネガポジ分類機の作成」Qiita, 2019
