ビッグデータはどんなもの?
昨今「ビッグデータ」というキーワードが様々なメディアでもよく取り上げられるようになり多くの人がそのワードを認知しています。「ビッグデータ」は、日本人にもイメージしやすい語呂で、Bigなデータとして誰にでも共有でき、その活用には多くの人が新しい可能性を感じている事とおもいます。
ビッグデータを駆使して、新しい視点を得るためには、統計的な処理を施し、可視化などで人にわかりやすく判断し易い情報に加工することが一般的です。分析前のデータマネージメントのプロセスには、概ね下記の3つのステージがあります。
データマネージメント
- データの収集と蓄積
- データの抽出とクリーニング及び分類
- データの統合
このようなプロセスを経て、ビッグデータとして分析が可能となります。今回は、データの収集/抽出クリーニングについて、考察してみましょう。
まずデータ収集の前にビッグデータとは何か?それを使って何ができそうか、今とても気になるところです。 今回、「ビッグデータ」の起源や定義についてネットで改めて調査してみました。
A. Gandomi氏とM. Haider氏が、2014年12月にInternational Journal of Information Managementに寄稿した記事(Beyond the hype: Big data concepts, methods, and analytics )によると、”その語の起源は定かでないが、1990年代の半ばに John Mashey 氏がシリコングラフィックスのランチでの会話で、その概念を明確にしたのが最初ではないか”と書いています。
この記事の中に「ビッグデータ」という語が、ProQuest リサーチライブラリーの中に出現する頻度が経年グラフと示されています。
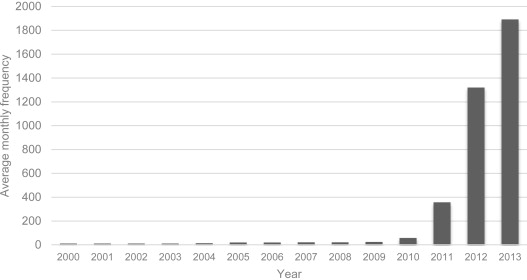
学術ライブラリでさえこのグラフが示すような出現数なので、「ビッグデータ」という言葉やその応用技術について一般の人の耳に届いたのは、2014年以降でしょう。
「ビッグデータ」は、その応用分野によって定義は様々で、2012年ごろから始まった、IBM / Oracle / SAPといったITのメジャープレイヤーのプロモーションで、「ビッグデータ」という言葉が一般に認知されて来たと言えます。
「ビッグデータ」は、日本語Wikipediaに以下のように定義されています。
ビッグデータは、通常、収集 取捨選択、管理、および許容される時間内にデータを処理するために一般的に使用されるソフトウェアツールの能力を超えたサイズのデータ集合を含んでいる。ビッグデータのサイズは、常に動いている目標値であり、単一のデータ集合内では、2012年現在数十テラバイトから数ペタバイトの範囲である。
目標値は、従来のDBMS技術だけでなく、NoSQLのような新設計のデータベースとその高速データ処理により動いている。この困難性により、「ビッグデータ」の新しいツールプラットフォームが、大量のデータの様々な側面を処理するために開発されている。
その他様々なプレイヤーが、独自の立場で「ビッグデータ」について、考察・定義などを行って、その統一的かつ明確な規定はありません。今まで見えなかったもの、なんとなく勘に頼っていた判断を、データ(事実)をもとに、わかりやすく把握し的確な判断を行えるようにするためのメカニズムと言えます。
現代のビジネス環境を考えた時、インターネット上に存在する様々な情報がビジネスに与えるインパクトは大きく、散在するデータから必要な情報を取り出して、多角的に分析することで、あなたのビジネスの未来を変えることができるのです。
ビッグデータはどこにある?
社内外に存在するデータ類で、事業や業務に活用できそうなデータは数多く存在します。 インターネットや社内システムなどから自社業務に関連するデータは探せば、いくらでも見い出せると思います。
例えば、インターネットに存在する以下のよう情報は、手動/自動に関わらず、多くの人によって日々調査されていると思います。
- Eコマース運営社なら、競合Eコマースサイトの、販売価格、配送価格、売れ筋情報、品揃え、GoogleやYahooの検索順位、取扱い製品の評価など。
- 家電製品のメーカーなら、Eコマース上の自社製品の価格やその推移、競合製品の価格やキャンペーン、売れ筋商品など。
- レストランチェーンなら、口コミ情報、競合店のキャンペーン、天候予測、店舗近隣のイベント、地域の人口統計など。
感覚的であれ、統計的であれ、インターネット上のこのような情報を活かして、自社事業や業務の取り組みに活かすことが当たり前になっています。
また、競合会社のプレスリリースや決算情報、政府・自治体・公共団体などが発表する各種統計などのパブリックデータ、各種メディアに掲載される、ニュース類、FaceBook・Twitter・Instagram・Blog・評価コミュニティー などのソーシャルネットワークに拡散されるバイラル情報、ナレッジコミュニティから得られる知識情報など、他にもあげれば枚挙にいとまがありません。
このような、外界の「ビッグデータ」と自社の業務システム・機器からのログ(IoT)、コールセンターの対応履歴、問い合わせメール、アンケート結果などから得られる情報を多角的に比較分析することで、現状を認識し事業戦略を立てるための判断材料として、また事業の未来予測を行うためのリファレンスとして、活用したいものです。
しかしながら、「ビッグデータ」には、数字として捉えられる、日付・価格・数量・人口などの定量データのほかに、ソーシャルメディア・ニュース・サポートセンターログなど文字ベースの定性データ(質的データ)が混在しています。
このようなデータ群の把握に役立つView を得るには、多くの工夫やToolの選択が必要になり、正解を見い出すことはそう簡単ではありません。
データを集めるには?
周りを見渡せば、あちこちに存在する「ビッグデータ」をコピーペーストしてエクセルなどに貼り付けて、分析することも可能です。しかしながら、人の作業量には限界がある上に大量となると、単調な作業になりがちな「コピー&ペースト」作業でのオペレータのストレスなど管理等も必要になります。
「ビッグデータ」を収集し分析用のデータプラットフォームを構築するには、人に代わりWebクローリングやスクレイピングといったシステム技術を使って、大量の情報を24時間365日休むことなく、効率よく大量に収集します。
Webクローリングは、Googleなどの検索サービスでも利用されている技術で、人がWebブラウザーでページを閲覧するのと同じシステムがWebなどのインターネットで公開されている情報を収集蓄積するもので、Webクローラーと呼ばれます。
ShtockDataは、自社内で専用プログラムを作成して、ターゲットサイトの情報を集める方法もありますが、現在では、「Webクローラー」のような、専用サービスを利用して、システム開発することなく、必要な情報を収集することが一般的になっています。
あなた(人間)にとっての「ビッグデータ」について考えてみましょう。
例えば、毎月平均一人あたり5件の装置を販売する6人の営業チームが、会議で6ヶ月間の引き合い状況や見積もりの状況を一覧するシーンを考えてみましょう。6人×5件×6ヶ月=180件の成約情報があり、これに対して、見積りが3倍・営業件数がその3倍あるとすると、全部で1,620件のコンタクト情報が存在します。
常時アクティブな案件が40%あるとすると、その数は約650件あり、案件別に状況を共有し認識するとなると無理があります。このデータはあなたという人間システムにとっては、処理不可能な量を持つデータ「ビッグデータ」と言えます。
そこで会議では、表計算ソフトなどを使って「営業ステータス別 / 担当者別 / 業種別 / 地域別」などの表やグラフを作成し、情報を把握しやすいように加工し、短時間で全体像を共有でき、問題点にフォーカスできるように工夫をします。
見やすくまとめられたデータは、前年対比など新しい次元でのデータ比較を可能にし、経年での状況把握や問題分析を精緻に行える能力をチームに与えてくれます。「ビッグデータ」を加工することで、誰もがわかりやすく、正確に状況を把握し注力すべきポイントを見出しやすくすることが可能です。
ケースによって、どのレベルの何のデータを「ビッグデータ」と捉えるかは、利用シーンによって大きく変わります。
データの整理
ShtockDataは、どのサイトのデータをどのように整理して蓄積するのかを調整します。人間が情報収集を行うには、どのサイトのどこをクリックして、必要なページにたどり着き、どの部分の情報を整理収集するかということは、簡単に判断できます。ShtockDataでは、この動作を実現する以下の機能を用意しています。
収集起点の設定
収集するサイトごとにページのデザインや構成が違い、必要な情報にたどり着く起点もそれぞれ違います。場合によっては、複数存在することもあります。
クロール効率の良い起点を設定し、そこから順次ページを巡回させる機能です。
ページの分析
ページの分析機能は、「パース」と呼ばれます。
Webページでは、「リンクしてページを遷移する」、「必要な情報を表示する」、「検索や申し込みなどのデータを書き込む」、「画像/映像/音声/ファイルなどを提供する」など、様々な機能が存在します。ページの内容を分析し、リンクや情報を収集する情報を特定する部分を定義できるように調整する機能です。
リンクの発見と遷移
必要なページへのリンクを発見し、設定したルールに従って、次に表示するページへ遷移する機能です。
必要な情報の整理と蓄積
ページ内の必要な要素(商品番号、商品名、金額、説明文など)を分類し、データベースに蓄積する機能です。以上の主な機能を使い、ShtockDataは、効率よく情報を収集します。Webやインターネットから収集した情報と社内で得られる大量のデータをシステムで分析して、人間の分析や判断に利用できるように加工をすることで、「ビッグデータ」を活用できるプラットフォームを構築します。
データの正規化
Webクローラーなどによって集められた大量の「ビッグデータ」を分析機にかける際に、最も課題となるのは、「分類に適した情報が用意できるか?」ということです。
価格を調べる場合を例に、Eコマースページを観察してみましょう。
価格情報の正規化
業務用品通販大手のASKULのページをチェックすると、リサーチに必要そうな情報がいくつも手に入ることがわかります。それでは以下のEコマースページ内にはどのくらいの情報が表示されているのでしょうか?
以下は、単一商品の表示ページです。
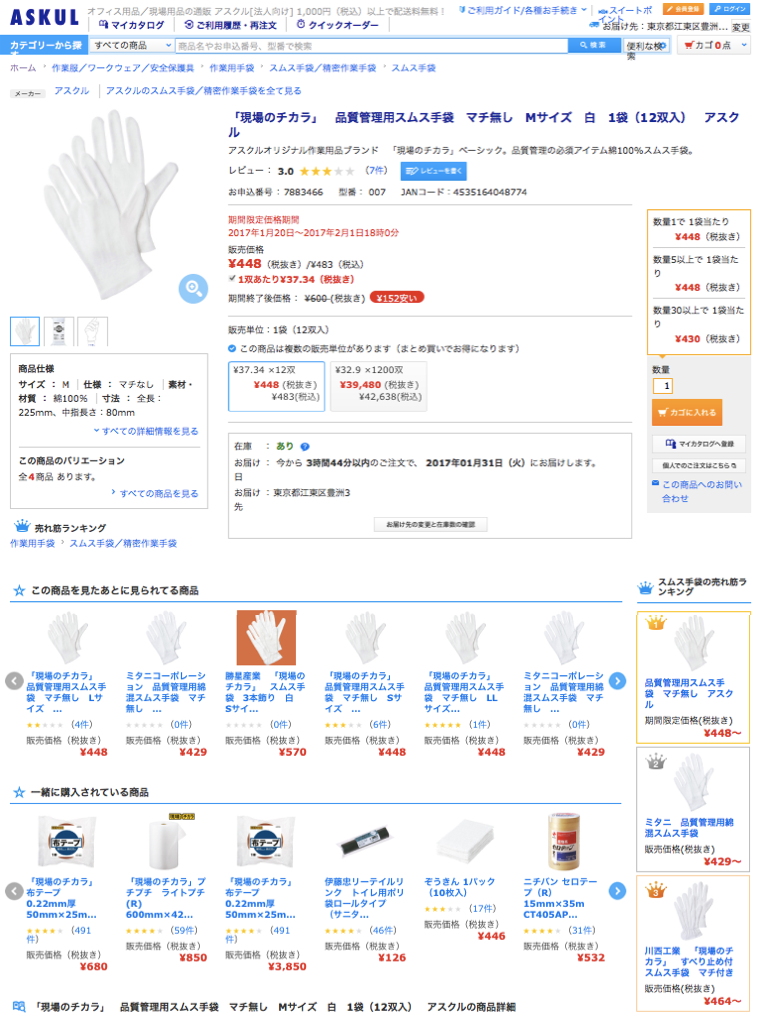
この例をご覧いただければ、定量的な値として簡単に比較できそうな価格情報でも、レコメンド商品や関連商品などを含めると数多く表示されていることが分かります。商品購入の際に、どのような価格情報がどこにどれだけ表示されているのか?など意識することはあまりないと思います。
例えば、一番上の行に「1,000円(税込)以上で送料無料!」とグレーに表示されている部分は、人の目にはあまり目立たず、手袋の販売価格認知の妨げになりませんが、システムでは、他の価格と等価に認識されてしまいます。
では、収集対象商品の価格に着目してみましょう。
| キャンペーン販売期間中の現在売価 | 【一袋12枚税抜単価¥448/税込単価¥483/一枚あたり単価¥37.34】 |
|---|---|
| キャンペーン終了後の将来売価 | 【税抜単価¥600/割引金額¥152】 |
| 数量割引現在売価 | 【価格12枚の価格/1200枚の税抜き価格¥38,480(これは送料抜きになる)】 |
などと数多く存在します。一つの商品ための価格表記だけでもいくつも存在します。
また、複数のサイトを比較してみても、サイトAの表示は「税抜き送料別」、サイトBの表示は「税込送料込み」、サイトCの表示は「税込送料別」など、商品の販売価格一つを考えてみても、比較を行うには、様々な調整を行う必要があります。加えてバーゲンやキャンペーン価格なども存在し、最近ではポイント還元率など、商品の価格比較だけでも考慮すべきポイントが多数存在します。
金額の表記方法についても、中古車などは、¥1,500,000.-/150万円/$12,000.00-などと、表記や単位がまちまちの場合があり、分析前にこれらを一つのルールで比較できるデータに正規化する必要があります。
商品価格調査のデータの正規化には、例えば、下記のような要素があります。
| 単位の統一 | 数量、面積、重量、長さ、容量… |
|---|---|
| 表記の統一 | ¥34,500 6百万円 ¥2,450(単位千円) |
| 半全角の統一 | 34,500円 H663/R HD223-1 |
| カテゴリの統一 | 化粧品=コスメ |
| 新旧製品の関連付け | A22401 → A22401N等やバリエーション |
マッチング(名寄せ)
処理を複雑化させる要因に、Webサイトごとの、商品名や型番表示の揺れによる違いがあり、単純に型番や名称だけで比較することを困難にしています。全ての商品がJANコードなどで比較できれば良いのですが、サイトによっては、JANコードを取り扱っていないところも多く、また「メーカー型番」や「商品名」にも、表記揺れがあり、完全なマッチングの妨げになっています。
商品の情報収集においては、商品ごとの特性により、サイズや色や素材の違いなど名寄せの際に考慮すべき項目が数多く存在します。同じ型番でサイト検索を行っても、500円で売られている製品のオプション品が、5万円で販売されている本体と一緒検索結果にリストアップされるといういうような事があります。
例:「RICOH GR2」の検索結果
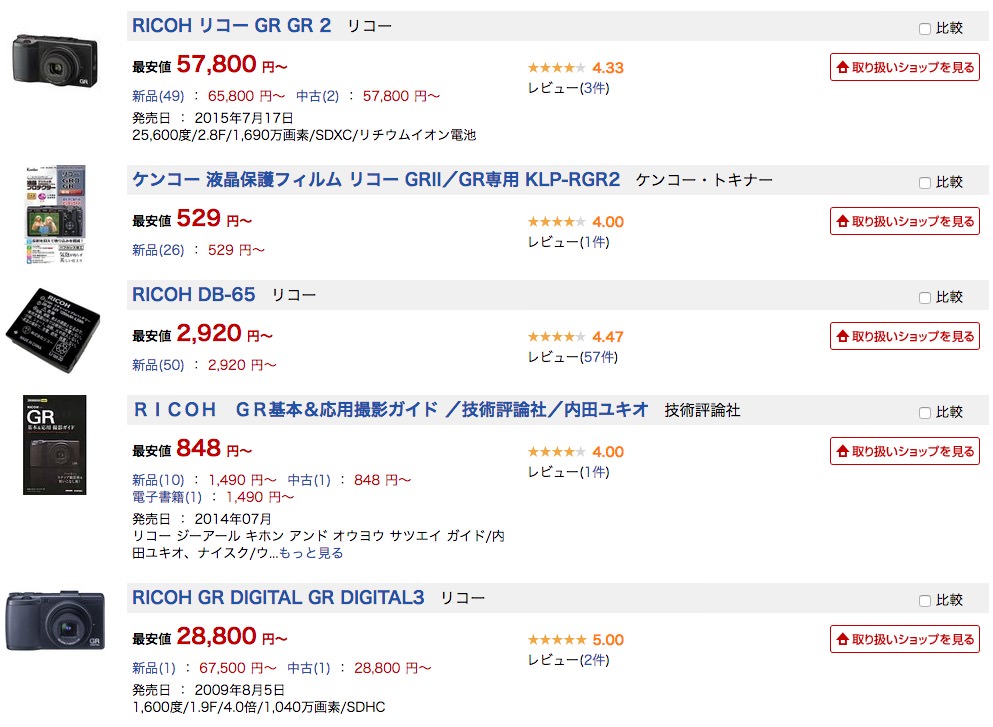
人間にはすぐ理解できるこのような商品の違いも、システムの場合はあらかじめ調整しておかなければ、正しく比較できるデータを収集することが困難になります。
(事例)電子コミックのマッチング
一般書籍のように電子コミックでは、ISBNなどの統一番号を持っておらず、提供サービスごとのコミック特定には少し工夫を要する。
例えば、「弱虫ペダル 第3巻」を調べてみると、サイトごとにタイトル表記に下記のような揺れがあります。
| ebookJapan | 弱虫ペダル (3) |
|---|---|
| BookLive | 弱虫ペダル 3 |
| Yahoo BookS | 弱虫ペダル 3巻 |
| 楽天Books | 弱虫ペダル 3 (少年チャンピオン・コミックス) [電子書籍版] |
| sokuyomi | 弱虫ペダル / 3 |
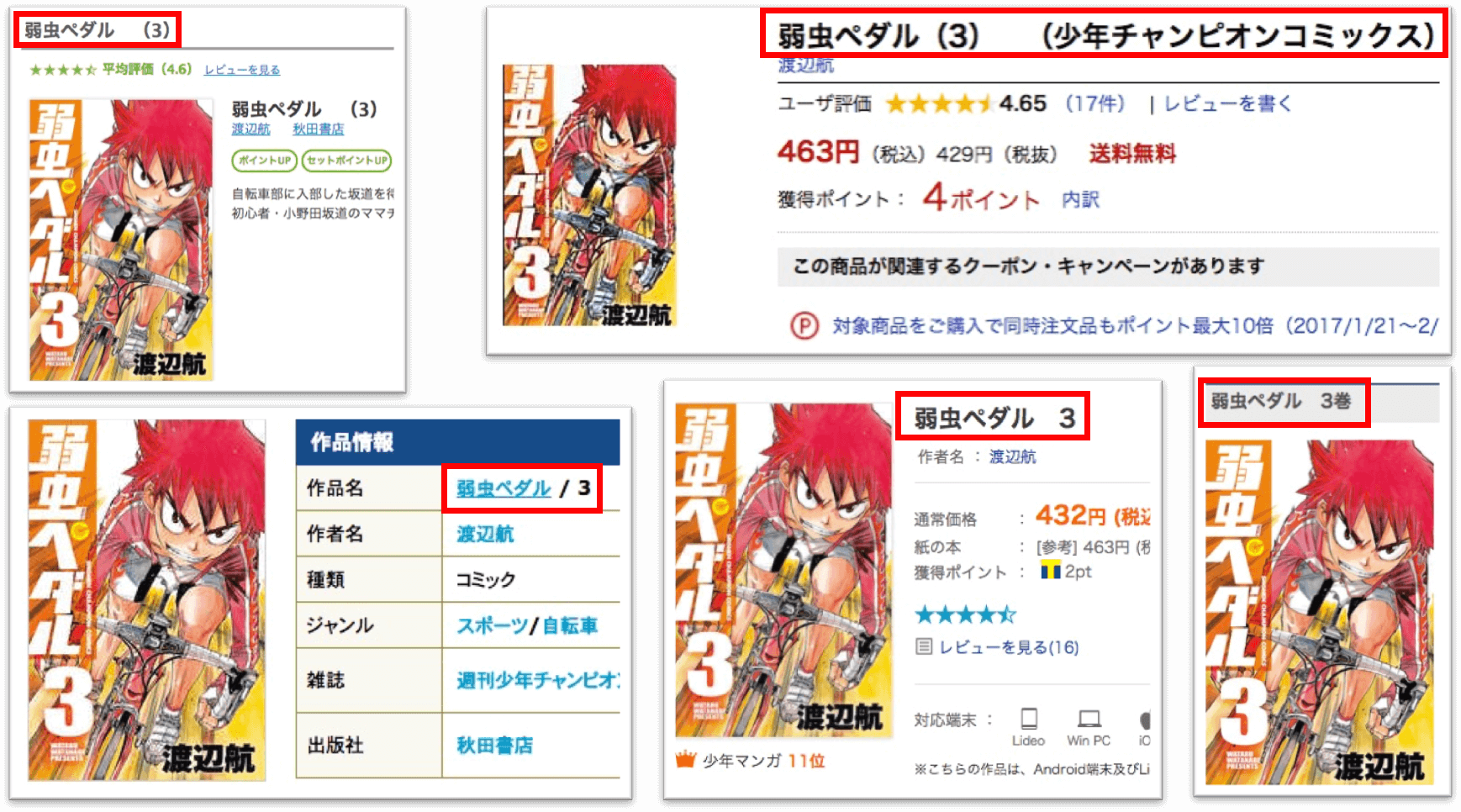
この3種類の表記を同じものだと判断することは、人間には容易ですが、システムであれば、下記のような手順を設定する必要があります。
- タイトルの数字・記号・スペースなどの全半角を正規化。
- タイトルの頭からスペースまでを取得して、シリーズタイトル名として保存する。
- タイトルの後に、連続して現れる数字を関数として保存する。
これでも名寄せのできないシリーズなども多く存在するので、一般的には、出版社/作者名/カテゴリなどのサイトの情報を駆使して、マッチングを行って、シリーズを特定するようなメカニズムが必要です。
データクリーニング(ノイズとの戦い)
システムでは、様々なトライによりデータを正規化し、商品情報を統一的に取り扱えるように、収集済みのデータ正規化や名寄せを行っても、まだこれで終わりではありません。収集時に取得した「ノイズの修正」や「取捨選択」作業(データクリーニングやクレンジングと呼びます。)を行って、初めて「ビッグデータ」としての価値を生みます。ノイズが多く、俗に言うダーティーデータをプロセスしても、結果が芳しくないことは明白です。
定量的な情報のノイズ処理
Eコマースでの価格調査などでのノイズは、発見・修正しやすいといえます。例えば、一つのEコマースサイトの情報を収集しても、ページデザインが商品特性によって微妙に違っており、設定した通りに情報を収集できない場合があります。
しかしながら、掲載される情報は情報提供者により管理されており、ShtockDataの収集条件の調整で、不足やノイズの少ない情報の収集が可能になります。
定性的な情報のノイズ処理
口コミサイトなどユーザが自由に発言するサイトでは、不要な情報を多く収集してしまうこともあります。提供者に発言をコントロールされていないWebサイトでは、意図的に他サイトのへの誘導を促す投稿や広告めいた投稿など、その場所での話題に関連性のない情報を収集してしまいます。これらの情報を排除することは、容易ではありません。
収集した情報を観察し、ノイズになる情報を排除するためのワードや投稿のパターンによってフィルタリングを行うことで、ある程度排除することができますが、「ビッグデータ」分析システムの結果について、そのータ特性を理解した上で判断することが必要です。もちろん分析システムもある程度のノイズは容認しうるシステムを構築する必要があることも、課題となります。
まとめ
「ビッグデータ」は、従来のコンピュータシステムでは取り扱うことが難しいほどの大量のデータをさしますが、定義は一定していません。なたに必要な「ビッグデータ」は、状況を観察することで、インターネット上にも業務システム上にも見つけることができます。ShtockDataは、効率良くデータを収集しますが、取得データは、玉石混合の状態になっていることが多々あります。
これを使えるレベルにするべく、正規化/名寄せ/クリーニングなどの処理を行って、初めて分析可能な「ビッグデータ」として活用できます。「ビッグデータ」は、金額や時間などの「定量的な」データと、口コミ発言や評価といった「定性的」なデータに分類され、これらをうまく分析することで、今まで見られなかった視点で状況を把握し、新しい施策や判断を促すことが可能です。「ビッグデータ」は企業の未来を変えてゆく可能性を秘めています。
次の記事「収益を最大化するレベニューマネージメント」では、データをどのようなプロセスで扱うのか、またその具体的な例を見てみましょう。
ネット普及以前から、IT業界で30年以上勤務。
ハードソフト両面でのネットワーク普及からネットコンテンツの創出運営まで幅広い業務を経験。
趣味:模型グライダー








